

Aunque el Machine Learning y la IA en general están explotando y expandiéndose en todos los campos, muchas empresas siguen teniendo un gran problema: les gustaría utilizar el ML/AI, pero no tienen los datos. Por desgracia para ellas, sin datos no hay por donde empezar. Y contratar data scientists no es la respuesta. De hecho, en los últimos meses, la demanda de ingenieros de datos está aumentando, y por buenas razones. De todos modos, hay formas de recopilar datos que implican a personas que están un paso por delante con respecto a los ingenieros de datos. Además, a veces, la recogida de datos requiere de algún modo la intervención manual de estas personas, lo que ralentiza el proceso de recogida de datos.
Así que, desde el surgimiento de la ingeniería de avisos, en este artículo, mostraremos cómo podemos usar avisos efectivos para la recolección de datos. Esto es lo que leerás aquí:
Table of contents:
Effective prompts for survey design
Prompt engineering for text annotation
– Sentiment analysis
– Named entity recognition
– Topic categorization
– Emotions classification
How prompt engineering can speed up the data extraction process
Putting it all togheter
Tabla de contenidos
Prompts eficaces para el diseño de encuestas
Una forma «histórica» o «clásica» de recopilar datos son las encuestas. Responder preguntas siempre ha ayudado a personas de diversos sectores a realizar investigaciones.
Hay que decir que la metodología ha cambiado con el tiempo, pero una encuesta sigue siendo una de las formas «base» de recopilar datos y todavía ayudamos a la gente a rellenarlas de diferentes maneras: en papel, por teléfono o por correo electrónico. Incluso los creadores recopilan datos a través de encuestas en las redes sociales y por correo electrónico (¡yo soy culpable!) para mejorar sus contenidos.
Así que, dada la importancia de las encuestas, ¿por qué no mejorarlas a través de la IA? O, simplemente: ¿qué harías si tuvieras que crear una encuesta, pero no sabes por dónde empezar?
Ya lo sé. Le preguntarías a ChatGPT.
Buena solución, pero hagámosla con un método.
He aquí algunos consejos para crear prompts eficaces y siempre válidos:
- Que sean concisas y directas. Las instrucciones deben ser siempre breves y directas. De hecho, las preguntas largas pueden confundir al modelo de IA y dar lugar a respuestas imprecisas. Por tanto, sé preciso y conciso.
- Evita la jerga y los términos técnicos. A menos que la recopilación de datos se dirija específicamente a un público especializado, es importante evitar el uso de jerga y términos técnicos. Pide a la IA que utilice un lenguaje sencillo que pueda ser fácilmente comprendido por un amplio abanico de individuos, si los datos van a ir dirigidos a personas con distintos conocimientos (especialmente en el caso de las encuestas).
- Haz una pregunta cada vez. Cada pregunta debe centrarse en un único concepto o cuestión. Hacer varias preguntas a la vez puede crear confusión y dificultar que la máquina proporcione respuestas precisas. Concéntrese en las preguntas y, si es necesario, divida las ideas complejas en varias preguntas.
Hagamos ahora algunos ejemplos puntuales de encuestas.
Podemos empezar con una encuesta de satisfacción del cliente sobre un producto concreto: «Generar preguntas de encuesta sobre la satisfacción del cliente para un producto. Las respuestas deben ser 5«.
Y obtenemos:
Aquí hay algunas preguntas de encuesta sobre la satisfacción del cliente para un producto, donde los encuestados pueden proporcionar respuestas en una escala de 1 a 5 (siendo 5 el nivel más alto de satisfacción):
1) ¿Cuál es su grado de satisfacción con la calidad general de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
2) ¿Cómo calificaría el rendimiento y la fiabilidad de nuestro producto?
1: Muy deficiente
2: Deficiente
3: Regular
4: Bueno
5: Excelente
3) ¿En qué medida satisface nuestro producto sus necesidades y expectativas?
1: En absoluto
2: Algo
3: Moderadamente
4: Mayoritariamente
5: Completamente
3) ¿En qué medida satisface nuestro producto sus necesidades y expectativas?
1: En absoluto
2: Algo
3: Moderadamente
4: Mayoritariamente
5: Completamente
4) ¿Cuál es su grado de satisfacción con el servicio de atención al cliente de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
5) ¿Qué probabilidades hay de que recomiende nuestro producto a otras personas?
1: Muy improbable
2: Improbable
3: Neutral
4: Probable
5: Muy probable
6) ¿Cómo calificaría la relación calidad-precio de nuestro producto?
1: Mala relación calidad-precio
2: Valor por debajo de la media
3: Valor medio
4: Buena relación calidad-precio
5: Excelente relación calidad-precio
7) ¿Cuál es su grado de satisfacción con la facilidad de uso de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
8) ¿Cuál es su grado de satisfacción con las características y funcionalidades de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
9) ¿Cómo calificaría la durabilidad y longevidad de nuestro producto?
1: Muy mala
2: Deficiente
3: Regular
4: Buena
5: Excelente
10) ¿Cuál es su grado de satisfacción general con nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
Estas preguntas te ayudarán a calibrar los niveles de satisfacción de los clientes y a identificar los puntos fuertes y las áreas de mejora de tu producto. Recuerda analizar las respuestas cuidadosamente para obtener información valiosa y tomar decisiones informadas para mejorar la satisfacción del cliente.
No soy un experto en encuestas, pero considero que las preguntas proporcionadas por ChatGPT son una buena encuesta.
Ahora una pregunta: ¿podemos hacer algo mejor? Dijimos que teníamos que ser específicos, pero, efectivamente, no lo fuimos.
Para ser más precisos, podemos introducir una pregunta como esta: «Generar preguntas de encuesta sobre la satisfacción del cliente para un producto digital que ayuda a la gente a aprender IA. Las respuestas deben ser 3«.
Y obtenemos:
Por supuesto. He aquí algunas preguntas de encuesta sobre la satisfacción de los clientes de un producto digital que ayuda a aprender IA, en las que los encuestados pueden dar respuestas en una escala de 1 a 3 (siendo 3 el nivel más alto de satisfacción):
1) ¿Está satisfecho con el contenido de nuestro producto de aprendizaje de IA?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
2) ¿Cómo calificaría la claridad y comprensibilidad del material didáctico?
1: Poco claro y difícil de entender
2: Algo claro y comprensible
3: Muy claros y comprensibles
3) ¿Hasta qué punto nuestro producto de aprendizaje de IA ha cumplido sus expectativas?
1: No ha cumplido las expectativas
2: Cumple parcialmente las expectativas
3: Cumple totalmente las expectativas
4) ¿Cuál es su grado de satisfacción con la organización y estructura de los módulos de aprendizaje?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
5) ¿En qué medida le resultan útiles los ejercicios prácticos y los proyectos prácticos de nuestro producto de aprendizaje de IA?
1: No son útiles
2: Algo útiles
3: Muy útil
6) ¿Cuál es su grado de satisfacción con la disponibilidad y accesibilidad del apoyo y la asistencia?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
7) ¿Le parecen eficaces los cuestionarios y evaluaciones interactivos para reforzar su aprendizaje?
1: Poco eficaces
2: Algo eficaces
3: Muy eficaz
8) ¿Cuál es su grado de satisfacción con la interfaz de usuario y la navegación de nuestra plataforma de aprendizaje de IA?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
9) ¿Cómo calificaría la relevancia y aplicabilidad de los conceptos y técnicas de IA que se enseñan en nuestro producto de aprendizaje?
1: No relevante o aplicable
2: Algo relevantes y aplicables
3: Muy relevantes y aplicables
10) ¿Cuál es su grado de satisfacción con la experiencia general de aprendizaje que ofrece nuestro producto de aprendizaje de IA?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
Estas preguntas te ayudarán a evaluar los niveles de satisfacción de los clientes con tu producto y a identificar las áreas en las que se pueden realizar mejoras. El análisis de las respuestas te proporcionará información valiosa para mejorar la experiencia de aprendizaje y satisfacer eficazmente las necesidades de sus clientes.
Como podemos ver, si somos más específicos con la pregunta, la encuesta mejora. Podemos ver, de hecho, que las preguntas de las dos encuestas son similares, pero hay algunas diferencias.
Por ejemplo, consideremos la pregunta 9 debido a la primera indicación: «¿Cómo calificaría la durabilidad y longevidad de nuestro producto?«. ¿Podría relacionarse de algún modo con un producto de IA? Bueno, depende, pero quizá no. Sin embargo, la pregunta 9 del segundo intento es: «¿Cómo calificaría la relevancia y aplicabilidad de los conceptos y técnicas de IA que se enseñan en nuestro producto de aprendizaje?». Esta pregunta es mucho más directa y concisa, ¿no crees?
Ingeniería para la anotación de textos
La anotación de datos es el proceso de etiquetar (o anotar) datos en bruto con información adicional para hacerlos utilizables para algoritmos de ML.
En concreto, la anotación de datos, en lo que respecta a los datos de texto, es el proceso de añadir anotaciones al texto para añadir estructura o información adicional. Dependiendo de la tarea y los requisitos particulares, las anotaciones pueden contener una variedad de etiquetas, incluyendo etiquetas de sentimiento, entidades con nombre, etiquetas de parte de discurso, estructura gramatical, etiquetas de intención, etiquetas de categorización y más.
La ingeniería de prompts puede ayudarnos en las tareas de anotación de datos, haciendo que el proceso de recopilación de anotaciones a partir de texto sea automatizable y rápido. De hecho, proporcionando instrucciones específicas, el modelo puede generar prompts para extraer anotaciones para el análisis de sentimientos, el reconocimiento de entidades con nombre o cualquier otra tarea de clasificación de texto.
Veamos algunos ejemplos.
Análisis de sentimientos
El análisis de sentimientos es un subcampo del Procesamiento del Lenguaje Natural (NLP) que nos ayuda a comprender si un texto concreto tiene un sentimiento positivo, negativo o neutro. En estos casos, necesitamos un texto y queremos pedir a nuestra IA que clasifique su sentimiento.
Una pregunta puede ser algo como: «Analiza el sentimiento de la siguiente frase y etiquétala como positiva, negativa o neutra«. O «Clasifica el sentimiento de la siguiente frase en una de las categorías: positivo, negativo o neutro«.
Por ejemplo: «Analice el sentimiento de la frase dada y etiquétela como positiva, negativa o neutra» y obtenemos:
Basándose en la frase dada, el sentimiento puede clasificarse como negativo. La frase «decepción total» sugiere un fuerte sentimiento negativo, indicando que la película no cumplió las expectativas del hablante. La mención de «esperaba mucho más» refuerza aún más el sentimiento negativo, expresando una sensación de insatisfacción. Por lo tanto, la etiqueta de sentimiento para esta frase sería negativa.
Reconocimiento de entidades con nombre
El reconocimiento de entidades con nombre (NER) es el proceso de localizar y clasificar determinados tipos de información que se encuentran en los datos brutos. En concreto, es la tarea de identificar entidades, como personas, lugares y organizaciones, en un texto en lenguaje natural.
Como ya hemos señalado, los prompts deben ser precisas, concisas y lo más breves posible. En el caso de NER, tenemos que ser muy específicos, sobre todo en lo que respecta al campo de dominio.
Así, por ejemplo, algunos prompts pueden ser:
- «Extraer todos los nombres de persona del texto dado»
- «Identificar y clasificar todas las organizaciones mencionadas en el documento»
- «Detectar y clasificar todos los términos jurídicos y entidades del documento», etc.
Así, por ejemplo, podemos introducir la siguiente consulta: «Encuentra y clasifica todas las ubicaciones y empresas mencionadas en el párrafo: «Apple y Facebook son considerados gigantes tecnológicos de Silicon Valley». Y obtenemos:
Aquí está la categorización de lugares y empresas mencionados en el párrafo dado:
Ubicaciones: Silicon Valley
Empresas: Apple y Facebook
En este ejemplo, «Silicon Valley» se categoriza como ubicación, mientras que «Apple» y «Facebook» se categorizan como empresas.
Categorización por temas
La categorización por temas es una forma de organizar el texto que ayuda al lector a comprender el tema principal del texto y ver cómo se desarrolla. Cuando un texto se categoriza, se divide en partes más pequeñas que son más fáciles de entender.
Por ejemplo, un texto sobre la historia del baloncesto puede clasificarse en los apartados de historia, jugadores, equipos y deportes. Las indicaciones eficientes pueden ser:
- «Basándose en el contenido del texto, clasifíquelo como ‘Deportes’, ‘Política’, ‘Entretenimiento’ o ‘Tecnología'».
- «Clasifique el siguiente texto como ‘Salud y bienestar’, ‘Negocios y finanzas’, o ‘Ciencia y tecnología’, en función de su temática».
- «Determine si el siguiente texto debe categorizarse como ‘Historia’, ‘Literatura’, ‘Filosofía’, o ‘Religión’, en función de su contenido».
Veamos el efecto de los prompts genéricos con respecto a un específico. Por ejemplo, consideremos los dos primeros párrafos de este artículo. Una pregunta genérica podría ser:
«Por favor, clasifique el siguiente texto en los temas apropiados:
El nómada digital se ha convertido en un personaje icónico de la era moderna del trabajo a distancia. Las palabras suelen evocar la imagen de un escritor profesional o un trabajador tecnológico con un ordenador, deambulando por las calles de una pintoresca ciudad extranjera o tecleando en un café frente al mar.
Ven mundo, conocen gente nueva, trabajan en su tiempo libre. Los nómadas digitales son muchos tipos diferentes de trabajadores. Algunos son autónomos o contratistas independientes; otros son emprendedores que crean su propia empresa; y otros trabajan en puestos remotos a tiempo completo para empresas de todo el mundo.
Algunos son asalariados, mientras que otros dependen de ingresos ad hoc. En general, dicen los expertos, muchos de estos trabajadores son de cuello blanco y tienen una buena formación.»
Y obtenemos:
Posibles categorizaciones para el texto dado:
- Estilo de vida nómada digital
- Cultura del trabajo a distancia
- Emprendimiento y trabajo autónomo
- Equilibrio trabajo-vida privada
- Mano de obra global y colaboración internacional
- Oportunidades económicas y diversidad de ingresos
- Factores socioeconómicos en el nomadismo digital
- Flexibilidad profesional y trabajo independiente
- Impacto de la tecnología en el trabajo y los viajes
- Diversidad de la mano de obra e inclusión en el trabajo a distancia
Ten en cuenta que las categorizaciones pueden variar en función del contexto y de los requisitos específicos de la tarea de categorización.
En realidad son muchos temas. Por lo tanto, utilicemos un estímulo específico como: «Determine si el siguiente texto debe clasificarse como ‘tecnología’ o ‘trabajo’, basándose en su tema principal«:
El nómada digital se ha convertido en un personaje icónico de la era moderna del trabajo a distancia. Las palabras suelen evocar la imagen de un escritor profesional o un trabajador tecnológico con un ordenador, deambulando por las calles de una pintoresca ciudad extranjera o tecleando en un café frente al mar.
Ven mundo, conocen gente nueva, trabajan en su tiempo libre. Los nómadas digitales son muchos tipos diferentes de trabajadores. Algunos son autónomos o contratistas independientes; otros son emprendedores que crean su propia empresa; y otros trabajan en puestos remotos a tiempo completo para empresas de todo el mundo.
Algunos son asalariados, mientras que otros dependen de ingresos ad hoc. En general, dicen los expertos, muchos de estos trabajadores son de cuello blanco y tienen una buena formación.»
Y así nos va:
Por su tema principal, el siguiente texto debería clasificarse como «trabajo».
Algunos son asalariados, mientras que otros dependen de ingresos ad hoc. En general, dicen los expertos, muchos de estos trabajadores son de cuello blanco y tienen una buena formación.»
Y así nos va:
Por su tema principal, el siguiente texto debería clasificarse como «laboral».
Clasificación de emociones
La clasificación de emociones es el arte de extraer emociones del texto, es decir, nuestro algoritmo puede etiquetar un texto según exprese sentimientos positivos o negativos.
Por ejemplo, si escribo: «Estoy contento porque hoy brilla el sol», este texto se etiquetaría como «contento».
Por tanto, unas instrucciones eficaces pueden ser:
- «Detectar y etiquetar emociones en las siguientes publicaciones en redes sociales, distinguiendo entre emociones positivas (por ejemplo, alegría) y negativas (por ejemplo, enfado)».
- «Clasificar el tono emocional (por ejemplo, humorístico, sarcástico, melancólico) de la siguiente entrada de blog basándose en su contenido textual».
Por ejemplo, utilicemos este artículo para hacer un ejemplo: «Clasifica el tono emocional, distinguiendo entre emociones positivas (por ejemplo, alegría) y negativas (por ejemplo, enfado), del siguiente texto:
«Es increíble saber que estoy por delante de ambos en Grand Slams, pero al mismo tiempo cada uno escribe su propia historia», dijo Djokovic, que también recuperó el número uno del mundo en París.
«Siento que cada gran campeón de su propia generación ha dejado una enorme huella y un legado».
«Tengo una fe, una confianza y una fe enormes en mí mismo y en todo lo que soy, en quién soy y en lo que soy capaz de hacer».
«Este trofeo es otra confirmación de la calidad del tenis que todavía soy capaz de producir».
Djokovic intentará empatar el récord de Court en Wimbledon, un lugar donde ya ha ganado siete veces y será el favorito para igualar el récord de títulos masculinos de Federer.
«Los Grand Slams son las mayores prioridades en la lista de control, no sólo esta temporada, sino cualquier temporada, especialmente en esta etapa de mi carrera», dijo Djokovic.
«El viaje aún no ha terminado. Si estoy ganando Slams, ¿por qué pensar siquiera en poner fin a una carrera que ya dura 20 años?».
«Sigo sintiéndome motivado e inspirado para jugar el mejor tenis en estos torneos».
«Estos son los que más cuentan en la historia de nuestro deporte».
Y lo conseguimos:
El tono emocional del texto es principalmente positivo. He aquí el desglose:
Emociones positivas
- Alegría/amistad: «Es increíble saber que estoy por delante de los dos en Grand Slams»
- Confianza/creencia: «Tengo una enorme fe, confianza y creencia en mí mismo»
- Confirmación/satisfacción: «Este trofeo es otra confirmación de la calidad de tenis que aún soy capaz de producir».
- Motivación/inspiración: «Sigo sintiéndome motivado e inspirado para jugar el mejor tenis en estos torneos».
- Prioridades: «Los Grand Slams son las mayores prioridades en la lista de control, no sólo esta temporada sino cualquier temporada»
Emociones neutras
- Reconocimiento: «pero al mismo tiempo cada uno escribe su propia historia» (neutral, constatando un hecho).
- Legado/marca: «cada gran campeón de su generación ha dejado una gran huella y un legado» (neutral, reconoce el impacto)
En general, el texto expresa emociones positivas como alegría, confianza, satisfacción, motivación e inspiración.
Cómo la ingeniería rápida puede acelerar el proceso de extracción de datos
La extracción de datos es una parte fundamental de un flujo de trabajo de Data Science porque, como es comprensible, nos proporciona los datos que necesitamos analizar.
Sin embargo, aunque podamos utilizar algún lenguaje de programación para automatizar la extracción de datos, a veces el proceso no es sencillo porque podemos necesitar desarrollar mucho código. Pensemos, por ejemplo, en el proceso de extracción de datos de un archivo PDF o de un sitio web (web scraping): esto puede requerir mucho tiempo y código.
Sin embargo, hoy en día existen muchas herramientas que, dada una determinada orden, pueden extraer los datos que necesitamos de diversas fuentes.
Así, imaginemos que tenemos un PDF con una tabla como ésta:
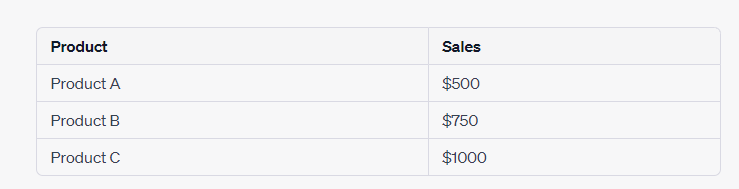
Una pregunta eficaz puede ser: «Extrae los valores de la columna ‘Ventas’ de la siguiente tabla«.
Y obtendríamos:
Claro, aquí está la salida deseada: [«$500», «$750», «$1000»]
Otra pregunta puede ser: «Extraiga los nombres y los números de teléfono del siguiente texto:
John Doe — john.doe@example.com — (555) 123–4567
Jane White — j.white@example.com — (111) 564–0981
Sam Simons — sam-simons@example.com — (123) 467–0987
Tricia Hawking — hawking.tricia@example.com — (012) 809–111”
Y obtenemos:
Aquí están los nombres y números de teléfono extraídos del texto proporcionado:
John Doe — (555) 123–4567
Jane White — (111) 564–0981
Sam Simons — (123) 467–0987
Tricia Hawking — (012) 809–111
Así que, como de costumbre, los prompts tienen que ser específicos. De hecho, en un caso como el anterior, escribir «extraer todos los datos del texto proporcionado» daría como resultado la extracción incluso de los correos electrónicos, pero en este caso no nos interesaban.
Ponerlo todo junto
Para una mejor comprensión, hemos separado las indicaciones en categorías, para poder hacer mejores ejemplos.
Pero la realidad es siempre más compleja que los ejemplos básicos, y puede que necesitemos clasificar el texto con referencias que estén «intercategorizadas».
Por ejemplo, consideremos este artículo. Queremos saber
- El día.
- La ubicación.
- Las emociones del Primer Ministro.
- El tema entre la actualidad y la crónica.
Extraiga el día, la ubicación, las emociones del Primer Ministro entre feliz y triste, y el tema entre la actualidad y la crónica en el siguiente texto:
Al menos 10 personas han muerto y otras 25 están hospitalizadas tras estrellarse un autobús de bodas en una región vinícola australiana.
Los pasajeros regresaban de una boda en una bodega el domingo por la noche en Hunter Valley, un lugar popular entre los enoturistas, cuando el autocar volcó.
La policía ha acusado al conductor del autobús, de 58 años, de 10 cargos de conducción peligrosa con resultado de muerte.
La policía informó de que aún se estaba identificando a los fallecidos.
Sin embargo, no se informó de que los recién casados estuvieran en el autobús.
La comisaria de policía Karen Webb dijo que el lugar del accidente es «todavía una escena del crimen activa». «Tenemos agentes forenses procesando la escena del crimen, tenemos agentes de la unidad de investigación de accidentes, tenemos agentes de rescate [en la escena]», añadió.
El accidente se produjo sobre las 23.30 hora local [13.30 GMT] cuando, según la policía, había niebla espesa en la zona. El autobús volcó al girar en una rotonda a la salida de una autopista. Según las autoridades, el vehículo ya ha sido puesto en posición vertical.
El subcomisario interino de la policía de Nueva Gales del Sur, Tracy Chapman, declaró que los pasajeros se dirigían a Singleton «presumiblemente para alojarse». Dos de los supervivientes fueron trasladados en helicóptero. Los medios de comunicación locales informan de que al menos uno de ellos sigue en estado crítico.
El Primer Ministro australiano, Anthony Albanese, declaró que es «tan cruel, tan triste y tan injusto» que un «día alegre en un lugar tan hermoso como éste termine con una pérdida de vidas tan terrible».»
Y obtenemos:
Día y hora: Domingo por la noche
Lugar: Hunter Valley, Australia
Emociones del Primer Ministro: Triste
Tema Crónica
Las emociones del Primer Ministro expresadas en el texto son tristes. Describe el incidente como «tan cruel, tan triste y tan injusto» que un «día alegre en un lugar tan hermoso como ese acabe con una pérdida de vidas tan terrible.»
Bueno, yo diría que esto está perfectamente clasificado. Pero, como hemos visto, la pregunta es muy específica. Si preguntáramos «las emociones del Primer Ministro», por ejemplo, la respuesta no sería tan precisa.
Por lo tanto, los prompt dan resultados precisos, solo si son precisos.
Conclusiones
En este artículo hemos visto cómo crear prompts eficaces para la recopilación de datos.
La ingeniería de prompts es una posibilidad de oro que nos brinda la IA para acelerar este proceso.
Recuerda las reglas de oro para proporcionar instrucciones breves, precisas y concisas y los resultados serán sorprendentes.