

Escrito por Marlon Cajamarca en Planeta Chatbot.
En los últimos años, la inteligencia artificial (IA) ha sido el sujeto de intensa exageración por parte de los medios de comunicación. El Machine Learning y el Deep Learning, en español Aprendizaje Automático (AA) y Aprendizaje Profundo (AP), junto con la IA, han sido mencionados en incontables artículos y medios de comunicación, regularmente fuera de las esferas de las publicaciones meramente tecnológicas. Se nos promete un futuro de chatbots inteligentes, coches autónomos y asistentes digitales, un futuro algunas veces pintado con un tinte sombrío y otras veces de manera utópica, en donde los trabajos serán escasos y la mayoría de la actividad económica será manejada por robots y maquinas embebidas con IA.
Inteligencia Artificial, Machine Learning y Deep Learning
Para el futuro o actual practicante de Machine Learning, es de vital importancia el poder reconocer la señal entre el ruido, tal que seamos capaces de reconocer y difundir acerca de los desarrollos que realmente están cambiando nuestro mundo y no de las exageraciones comúnmente vistas en los medios de comunicación. Si como yo, eres un practicante de Machine Learning, Deep Learning u otro campo de la IA, probablemente seremos las personas encargadas de desarrollar esas máquinas y agentes inteligentes, y por lo tanto, tendremos un rol activo que jugar en esta y la sociedad futura.
Por tal fin, este artículo pretende dar respuesta a preguntas como: ¿Qué es lo que ha alcanzado hasta ahora el Deep Learning?, ¿Qué tan significantes son dichos logros?, ¿Qué nos espera en el futuro?, ¿Realmente debemos creer en la exageración mediática del momento?
Tabla de contenidos
Breve Introduccion a la Inteligencia Artificial, Aprendizaje Automatico y Aprendizaje Profundo
Primero que todo, definamos claramente de que estamos hablando cuando hablamos de inteligencia artificial. ¿Qué es Inteligencia Artificial, el Aprendizaje Automático y el Aprendizaje Profundo? Y ¿Cuál es la relación entre estos términos?

Inteligencia Artificial
La inteligencia artificial (IA) nació en los años 50, de la mano de algunos pioneros del naciente campo de las ciencias de la computación. Estos pioneros entonces comenzaron a preguntarse acerca de poder lograr que los computadores “pensaran”. Por lo tanto, una definición concisa acerca del campo de la IA sería: el esfuerzo de automatizar tareas intelectuales normalmente realizadas por humanos. Como tal, IA es un campo general que contiene a el Aprendizaje Automático (AA) y a el Aprendizaje Profundo (AP), pero que también incluye otro tipo de sub-campos que no necesariamente involucran “Aprendizaje” como tal.
Los primeros programas que jugaban ajedrez, por ejemplo, sólo involucraban reglas rígidas creadas por programadores, por lo que estos no califican como aprendizaje automático. Por mucho tiempo, muchos expertos creyeron que la IA con nivel humano podía alcanzarse al hacer que los programadores crearan a mano un conjunto de reglas lo suficientemente grandes para manipular el conocimiento y así generar máquinas inteligentes. Este enfoque es conocido como IA simbólica, y fue el paradigma que dominó el campo de la IA desde 1950 hasta finales de 1980 y alcanzó el pico de su popularidad durante el boom de los Sistemas Expertos en 1980.
Aunque la IA simbólica probó ser adecuada para resolver problemas lógicos y bien definidos, como el jugar al ajedrez, se volvió intratable el encontrar reglas explícitas para resolver problemas mucho más complejos, como la clasificación de imágenes, el reconocimiento de voz y la traducción entre lenguajes naturales (como español, inglés, etc. diferentes a lenguajes no naturales como los lenguajes de programación). Un nuevo enfoque surgió entonces para tomar el lugar de la IA simbólica: El Machine Learning o Aprendizaje Automático.
Aprendizaje Automatico o Machine Learning
En la Inglaterra victoriana, alrededor de 1840 y 1850, Charles Babbage invento el Motor Analítico: El primer computador mecánico de propósito general. Este solo computaba operaciones de manera mecánica con el fin de automatizar el cómputo de ciertas operaciones en el campo del análisis matemático, de ahí su nombre Motor analítico. Sin embargo, este motor analítico no tenía las pretensiones de originar algo nuevo, solo podía hacer lo que se le ordenaba computar, su único fin era para asistir a los matemáticos en algo que ellos ya sabían hacer.
Luego en 1950, Alan Tuning, introdujo el test de Turing, y llego a la conclusión de que computadores de propósito general podrían ser capaces de “Aprender” y “ser originales”. El AA surgió entonces de preguntas como:
¿puede un computador ir mas allá de lo que le ordenamos como hacer y aprender por si mismo como realizar una tarea específica? ¿Podría un computador sorprendernos? Y, en vez de programadores especificando regla por regla como procesar datos, ¿podría un computador automáticamente aprender esas reglas directamente de los datos que le pasamos?

Aprendizaje Automático: Un nuevo paradigma de programación
La pregunta abrió una nueva puerta a un nuevo paradigma de programación. A diferencia del clásico paradigma de la IA simbólica, donde humanos inyectan reglas (un programa) y datos para ser procesados acorde con dichas reglas para así obtener respuestas a la salida del programa, con el Machine Learning o Aprendizaje Automático, los humanos pasamos los datos como entrada al igual que las respuestas esperadas de dichos datos con el fin de obtener a la salida las reglas que nos permiten hacer el mapeo efectivo entre entradas y sus correspondientes salidas. Estas reglas pueden ser luego aplicadas a nuevos datos para producir respuestas originales, es decir, generadas automáticamente por las reglas que el sistema “aprendió” y no por reglas explícitamente codificadas por programadores.
Un sistema de Aprendizaje Automático es “entrenado” en vez de ser explícitamente “programado”. A este sistema se le presentan muchos ejemplos relevantes para la tarea en cuestión y este encuentra la estructura estadística o patrones en dichos ejemplos que eventualmente permiten al sistema aprender las reglas para automatizar dicha tarea. Por ejemplo, si deseamos automatizar la tarea del etiquetado de nuestras fotos de vacaciones, lo que haríamos es pasar al sistema de AA muchos ejemplos de fotos ya etiquetadas por humanos y el sistema aprendería las reglas estadísticas que le permitirían asociar fotos específicas con sus respectivas etiquetas.
Sin embargo, aunque el AA empezó a ser tenido en cuenta desde los años 90, este se ha convertido en el más popular y exitoso de los sub-campos de la IA, una tendencia guiada por la disponibilidad de mejor hardware y gigantes conjuntos de datos. El AA está fuertemente relacionado a la estadística matemática, sin embargo difiere de la estadística en varias formas. A diferencia de la estadística, el AA tiende a lidiar con grandes y complejos conjuntos de datos (los cuales pueden contener millones de imágenes cada una de ellas con miles de pixeles) para lo cual el clásico análisis estadístico (como el análisis bayesiano) sería totalmente impráctico. Como resultado, el AA, y en especial el Aprendizaje Profundo, muestra poca teoría matemática, comparada con el campo de la estadística, y son considerados más como campos orientados hacia la ingeniería. Es decir, el AA es una disciplina aplicada, en la cual las ideas son probadas mucho más a menudo de forma empírica que de forma teórica.
Adentrandonos en el Aprendizaje Profundo
Para definir el Deep Learning/Aprendizaje Profundo y entender la diferencia entre AP y otros enfoques del AA, primero necesitamos alguna idea de lo que hacen y como funcionan los algoritmos de AA. Acabamos de decir que el AA descubre reglas para ejecutar tareas de procesamiento de datos, dados los ejemplos de lo que se espera como respuesta o salida de dichos datos. Por lo tanto para realizar AA necesitaremos de tres ingredientes fundamentales:
- Datos de entrada: Por ejemplo, si la tarea es reconocimiento de voz, estos datos de entrada serían archivos de sonido o grabaciones de gente hablando. Si la tarea es etiquetado de imágenes, estos datos podrían ser fotos o imágenes.
- Ejemplos de lo que se espera como salida: En la tarea de reconocimiento de voz, estos podrían ser transcripciones generadas por humanos de los archivos de audio. En la tarea de etiquetado de imágenes, las salidas esperadas pueden ser etiquetas tales como “perro”, “gato”, “persona”, etc.
- Una forma de medir si el algoritmo está realizando un buen trabajo: Este paso es necesario para determinar la distancia o desvío entre la salida actual generada por el algoritmo y la salida esperada. Esta medida es usada como señal de realimentación para ajustar la forma en la que el algoritmo trabaja y se actualiza. Este paso del ajustamiento es lo que llamamos “Aprendizaje”.
Estos ingredientes por si mismos son los fundamentales para todo tipo de algoritmo de AA y AP. Con estos ingredientes exploraremos ahora que es lo que realmente hace un algoritmo de AA y de AP con ellos para producir resultados que parecen salidos de historias de ficción.
Aprendiendo Representaciones a partir de Datos
Un modelo de AA transforma sus datos de entrada en respuestas con significado, un proceso que es “aprendido” de la exposición de dicho modelo a ejemplos previamente conocidos de entradas y salidas correspondientes. Por lo tanto, el problema central en el AA y el AP es el aprender representaciones útiles de los datos de entrada, representaciones que nos acerquen a la generación o predicción de las salida esperadas.
Antes de ir más lejos, respondamos a la pregunta ¿que es una representación? En su núcleo, una representacion es una forma diferente de ver los datos, una forma diferente de representar o codificar datos. Por ejemplo, una imagen a color puede ser codificada en formato RGB (red-green-blue) o en formato HSV (hue-saturation-value): Estas son dos representaciones diferentes de los mismos datos. Algunas tareas que pueden ser más difíciles utilizando una de esas representaciones pueden volverse mucho más fáciles al utilizar la otra representación.
Por ejemplo, la tarea “seleccionar todos los pixeles rojos en una imagen” es mucho más simple en el formato RGB mientras que la tarea “hacer la imagen menos saturada” es más simple en el formato HSV. Los modelos de AA están diseñados para encontrar las representaciones más apropiadas de la información que reciben como entrada, transformaciones de los datos que los hacen amenos a la tarea en cuestión, como a la tarea de clasificación de imágenes, por poner un ejemplo.
Hagamos esto un poco más concreto mediante el siguiente ejemplo. Consideremos un plano cartesiano x-y con algunos puntos representados por sus respectivas coordenadas (x,y) como se muestra en la siguiente imagen:

Algunos datos de ejemplo en el plano cartesiano
Como podemos ver, tenemos unos pocos puntos blancos y otros pocos puntos negros. Digamos que queremos desarrollar un algoritmo que pueda tomar las coordenadas (x,y) de un punto y entregar como salida si el punto es blanco o negro. En este caso:
- Las entradas son las coordenadas de nuestros puntos
- Las salidas esperadas son los colores de nuestros puntos.
- Una forma de medir si nuestro algoritmo está realizando bien su trabajo podría ser contando la cantidad de puntos que han sido correctamente clasificados por el algoritmo.
Lo que necesitamos aquí es una nueva representación de nuestros datos originales que limpiamente separe los puntos blancos de los negros. Una de esas transformaciones las cuales podríamos usar, entre muchas otras posibilidades, sería un cambio de coordenadas, así:

Cambio de coordenadas realizado de forma manual
En este nuevo sistema de coordenadas, las coordenadas de nuestros puntos puede decirse que son una nueva representación de nuestros datos originales. Y en este caso es una muy buena representación! Con esta nueva representación, el problema de clasificación entre puntos blanco y negros puede ser expresada con una simple regla: “Puntos negros son los cuales x>0” y “Puntos blancos son los cuales x<0”. Esta nueva representación básicamente resuelve el problema de clasificación.
En este caso, nosotros definimos el cambio de coordenadas a mano. Pero si en cambio intentamos buscar sistemáticamente diferentes posibles cambios de coordenadas, y usamos como realimentación el porcentaje de puntos correctamente clasificados, entonces estaremos haciendo ML/AA. “Aprendizaje” en el contexto del AA, describe el proceso de la búsqueda automática de mejores y más útiles representaciones para nuestros datos.
Todos los algoritmos de AA consisten en encontrar automáticamente dichas representaciones que convierten datos de entrada en representaciones mucho más útiles de los mismos para una tarea en específico. Estas operaciones pueden ser cambios de coordenadas, proyecciones lineales, translaciones, operaciones no lineales, etc. Los algoritmos de AA no son usualmente creativos encontrando estas transformaciones, ellos están meramente buscando a través un conjunto predefinido de operaciones, dicho conjunto es denominado espacio de hipótesis.
Entonces, eso es lo que realmente es el AA, técnicamente: La búsqueda de representaciones útiles de los datos de entrada, dentro de un espacio predefinido de posibilidades, usando como guía una señal de realimentación que nos permiten realizar predicciones viables de las salidas esperadas. Esta simple idea permite resolver una amplia gama de tareas intelectuales, desde el reconocimiento de voz, la vision computarizada y hasta los coches autónomos.
Ahora, ya que hemos entendido lo que significa “Aprendizaje” en el contexto del AA, miremos que es lo que hace el Aprendizaje Profundo o Deep Learning tan especial.
El término “Profundo” En Aprendizaje Profundo
Deep Learning o Aprendizaje Profundo es un sub-campo específico del Aprendizaje Automático: Un nuevo intento en aprender representaciones idóneas de los datos en el que se pone un énfasis en aprender dichas representaciones de manera sucesiva mediante lo que se denominan capas. El término “Profundo” en Aprendizaje Profundo no hace ninguna referencia a un tipo de entendimiento profundo alcanzado mediante la utilizacion de este tipo de enfoque, en vez de ello, el término representa la idea de la representación sucesiva y jerarquizada de los datos por medio de capas. La cantidad de capas que contribuyen a un modelo es denominada la “profundidad del modelo”. Con esto en mente, otros nombres apropiados para este enfoque podrían ser “Aprendizaje Representacional por capas” o “Aprendizaje Representacional Jerarquizado”.
Modelos de AP modernos normalmente involucran decenas o cientos de capas sucesivas de representación, y todos los parámetros que ellas contienen son aprendidos automáticamente mediante la exposición de dichos modelos a los denominados datos de entrenamiento. Mientras tanto, otros enfoques en el AA tienden a enfocarse en el aprendizaje utilizando sólo una o dos capas de representación para sus datos, por lo tanto, este tipo de enfoques son denominados modelos de Aprendizaje Superficial o Shallow Learning, lo contrario al Aprendizaje Profundo o Deep Learning.
En el AP, esta representaciones por capas son casi siempre aprendidas mediante modelos llamados Redes Neuronales, los cuales están literalmente estructurados en capas apiladas una después de la otra. El termino Redes Neuronales es una referencia a la neurobiología, pero, aunque algunos de los conceptos centrales en el AP fueron desarrollados en parte de la inspiración tomada de nuestro entendimiento del cerebro, los modelos de AP no son modelos del cerebro. No hay ninguna evidencia de que el cerebro implemente algunos de los mecanismos de aprendizaje usados en los modelos modernos de AP.
Muchos de nosotros nos hemos encontrado con artículos y revistas proclamando que modelos de AP funcionan como el cerebro humano o que fueron modelado basados en el cerebro humano, pero ese no es el caso. Podría ser confuso y contraproducente para los novatos entrando en este sub-campo el pensar que el AP esta en alguna manera relacionado con la neurobiología. Para nuestros propósitos, el AP es un marco de trabajo matemático para el aprendizaje representacional de los datos.
Para ganar un poco más de intuición de como lucen las representaciones aprendidas por un algoritmo de AP, examinemos como una red con varias capas de profundidad transforma una imagen de un digito escrito a mano con el fin de reconocer que digito es a su salida.

Red Neuronal Profunda para la clasificación de dígitos


Representaciones profundas aprendidas por el modelo de clasificación de dígitos
Como podemos ver en las figuras anteriores, la red transforma la imagen del digito en representaciones que son cada vez más diferentes de la imagen original y a su vez cada vez más informativas con respecto al resultado final. Podríamos pensar en una “Red Neuronal Profunda” como una operación de destilación de la información multi-etapa, donde la información fluye a través de filtros sucesivos y sale cada vez más purificada, es decir, mucho más útil con respecto a una tarea en específico que deseamos resolver, en este caso el reconocimiento de dígitos provenientes de imágenes de dichos dígitos escritos a mano.
Entonces, eso es lo que es el AP, técnicamente: Una forma multi-etapa de aprender representaciones de los datos. Es una idea simple, pero resulta que mecanismos muy simples, al ser lo suficientemente escalados, pueden terminar pareciendo como magia.
Entendiendo el Funcionamiento del Aprendizaje Profundo
En este punto, ya sabemos que el AA es acerca del mapeo de entradas (como imágenes) a objetivos (como la etiqueta “gato”), y que es realizado al observar muchos ejemplos de entradas y sus correspondientes objetivos. También sabemos que las Redes Neuronales Profundas (RN Profundas) realizan ese mapeo de entradas a objetivos mediante la aplicación de muchas (profundad de la red) transformaciones simples y sucesivas de los datos (mediante las capas de la red), y que estas transformaciones de los datos son aprendidas mediante la exposición de la red a muchos ejemplos de entrada-objetivo. Miremos ahora como concretamente este “aprendizaje” ocurre en dichas Redes Neuronales profundas.
La especificación de lo que una capa debe hacer a sus entradas es guardada en los llamados pesos de la capa, que en esencia son un montón de números. En términos técnicos, diríamos que la transformación realizada por una capa a sus datos de entrada esta parametrizada por sus pesos. Estos pesos o weights son entonces denominados los parámetros de la capa en cuestión. En este contexto, “Aprendizaje” significa encontrar ese conjunto de valores numéricos para cada uno de los pesos en cada una de las capas de la RN, tal que la RN sea capaz de mapear correctamente las entradas de nuestros ejemplos con sus correspondientes objetivos.
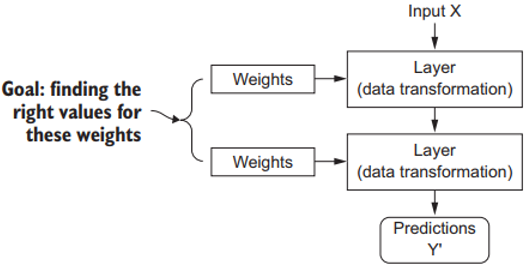
Una Red Neuronal esta parametrizada por sus pesos
sin embargo, para controlar algo, primero debemos ser capaces de observarlo. Para controlar la salida o respuesta de nuestra RN, necesitamos ser capaces de medir que tan desviada es sus salidas o predicciones con respecto a la salidas esperadas u objetivos. Este es el trabajo de la Función de Costo o Función de Perdida de la RN, a veces también llamada Función Objetivo. Esta función de perdida es la encargada de tomar las predicciones entregadas por la RN junto con el verdadero objetivo (lo que deseamos que la RN produzca) y luego computar el valor o puntuación de desvío, capturando que tan bien la RN ha hecho su trabajo de predicción para ese ejemplo en específico, como vemos en la siguiente figura.

La funcion de perdida mede la calidad de las predicciones o salidas de la red
El truco fundamental en el AP es usar este valor de desvío como señal de realimentación para ajustar el valor de cada uno de los pesos un poco, en la dirección que disminuya el valor de perdida para el ejemplo actual, como se muestra a continuación:
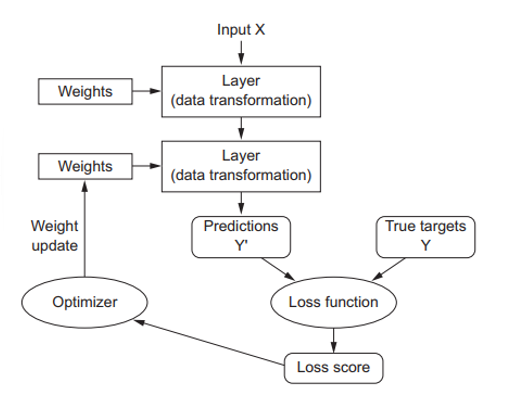
El ajuste del valor de cada uno de estos pesos o parámetros de la red es el trabajo del Optimizador, el cual implementa lo que se denomina el Algoritmo de Retropropagación o Propagación Inversa. Este algoritmo es uno de los algoritmos vitales, si no el más vital, en lo que concierne al AP.
Inicialmente, los pesos de la RN son asignados con valores aleatorios, por lo que al inicio la RN implementara meramente una serie de transformaciones aleatorias. Naturalmente, las salidas de la RN en este punto inicial estarán lejos de lo que idealmente deben ser, y el valor de perdida será del mismo modo muy alto. Pero, con cada ejemplo que la RN procesa, cada uno de los pesos es ajustado un poco en la dirección correcta, es decir, en la dirección en la que el valor de pérdida disminuya.
Este es el denominado Bucle de Entrenamiento, el cual, repetido la cantidad de veces suficiente (típicamente decenas de iteraciones sobre miles o millones de ejemplos), producirá los valores para cada uno de los pesos de la RN que minimizaran la función de pérdida. Una RN con una mínima perdida es una red en la que sus salidas o predicciones están tan cerca como sea posible de los verdaderos objetivos: Entonces tendremos una Red Entrenada.
Logros Actuales y Panorama Futuro del Aprendizaje Profundo
Aunque el AP es sub-campo un poco viejo del AA, este alcanzo su máximo auge a principios del 2010. En los subsecuentes años, este ha lograda nada menos que una revolución en el campo, con resultados notables en problemas perceptuales tales como visión y audición (problemas que involucran habilidades que parecen naturales e intuitivas para nosotros los humanos pero por largo tiempo han sido complejas y esquivas para las maquinas).
En particular, el AP ha permitido los siguientes avances, todos ellos en áreas históricamente difíciles para el AA:
- Clasificación de imágenes cercana al nivel humano.
- Reconocimiento de voz cercano al nivel humano.
- Transcripción de escritura a mano cercana al nivel humano.
- Traducción automática mejorada.
- Conversión de texto a dialogo mejorada.
- Asistentes digitales como Google Now y Amazon Alexa.
- Conducción autónoma cercana al nivel humano.
- Mejora en publicidad personalizada usada por Google, Baidu y Bing.
- Buscadores web mejorados.
- Habilidad para responder preguntas hechas en lenguajes naturales.
- Nivel súper humano en ciertos juegos como Go, ajedrez, entre otros.
Aún seguimos explorando la gran gama de posibilidades en las cuales el AP puede aportar su grano de arena. Se ha empezado a aplicar AP a una amplia variedad de problemas fuera de la típica percepción de máquina y entendimiento del lenguaje natural, tales como el razonamiento formal, causalidad, etc. De ser exitoso, estaríamos en una era en donde el AP asista a los humanos en ciencias, desarrollo de software, medicina, y otros campos más.
No Hay que Creer en la Exageración a Corto plazo
Aunque el AP nos ha llevado a conseguir logros notables en estos últimos años, las expectativas por lo que este campo será capaz de alcanzar en la próxima década tienden a exagerarse mucho más de lo que podría ser posible. Aunque algunas aplicación que cambiaran radicalmente el mundo como los autos autónomos ya están al alcance, muchas otras se mantendrán muy probablemente fuera de nuestro alcance por un largo tiempo, tales como como sistemas de diálogos realmente creíbles, traducción automática a nivel humano a través de lenguajes arbitrarios, y el entendimiento a nivel humano del lenguaje natural.
En particular, ninguna charla acerca de inteligencia Artificial General a nivel humano debería tomarse muy seriamente. El riesgo con las grandes expectativas a corto plazo es que, mientras la tecnología falla en entregar resultados, la inversión en investigación se detendrá paulatinamente, ralentizando el progreso por un largo tiempo.
Esto a pasado antes. Dos veces en el pasado, la IA entro en un ciclo de intenso optimismo seguido de uno de decepción y escepticismo, resultando en la escases de inversión. Primero inicio con la IA simbólica en 1960. In esos primeros años, las proyecciones acerca de la IA volaban alto y algunos pioneros en el campo pronosticaban que en 10 años la creación de inteligencia artificial general sería un problema resuelto. Sin embargo aún hoy en el 2019 ese hito parece estar lejos de alcanzar, tan lejos que aún no somos capaces de pronosticar cuando sucederá. Años después, al ver que estas grandes expectativas fallaron en materializarse, la inversión de investigadores y del gobierno se alejó del campo de la IA, marcando el comienzo de lo que se denominó el primer invierno de la IA.
Y este no sería el último. En 1980, un nuevo intento en la IA simbólica, esta vez por el campo de los sistemas expertos, comenzó a ganar tracción entre grandes compañías. Unas cuantas historias iniciales exitosas accionaron una nueva ola de inversión, con corporaciones a lo largo del mundo iniciando sus propios departamentos internos de IA para desarrollar estos sistemas expertos. Alrededor de 1985, las compañías estaban gastando cerca de 1 billón de dólares por año en esta tecnología. Sin embargo, a inicios de los años 90, estos sistemas probaron ser difíciles de mantener, difíciles de escalar, y limitados en su rango de operación, por lo que el interés por los sistemas expertos fue muriendo lentamente. Ahí fue donde se originó el segundo invierno de la IA.
Podríamos estar actualmente en el tercer ciclo de exageración y decepción en el campo de la IA, aunque ahora estemos en la fase de intenso optimismo. Es mejor moderar nuestras expectativas a corto plazo y hacer que la gente se familiarice mas con el lado técnico del campo, con el fin de que se tenga una idea clara de lo que el AP puede y no puede entregarnos.
La Promesa Futura de la Inteligencia Artificial y el Aprendizaje Profundo
Aunque podremos tener expectativas a corto plazo acerca de la IA, la imagen a largo plazo luce brillante. Aún estamos iniciando la aplicación del AP en diversos e importantes problemas para los cuales luce totalmente como una tecnología transformadora, desde el diagnóstico clínico a los asistentes digitales.
La investigación en IA se ha movido rápido y a pasos agigantados en estos últimos cinco años, esto en gran parte al nivel de inversión nunca antes visto en la corta historia de la IA, pero hasta ahora relativamente poco de este progreso ha logrado hacerse camino hacia los productos y procesos que dan forma al mundo. La mayoría de los descubrimientos investigativos en el AP aún no han sido aplicados, o al menos no aplicados al rango total de problemas que el AP podría solucionar alrededor de todas las industrias. Nuestro doctor aun no usa IA, ni tampoco lo hace nuestro contador. Aun no utilizamos tecnologías de IA en nuestra rutina diaria.
De acuerdo, podremos preguntarle a nuestro móvil inteligente simples preguntas y obtener razonables respuestas, podremos obtener recomendación de productos en Amazon bastante útiles, y también podremos buscar la palabra “cumpleaños” en Google Photos y encontrar inmediatamente nuestras fotos de cumpleaños del mes o año pasado. Eso es un gran avance comparado con lo que este tipo de tecnologías solían ser. Sin embargo, estas tecnologías siguen siendo solo accesorios para nuestras rutinas diarias. La IA aún tiene que hacer la transición para convertirse en parte central de la manera en la que trabajamos, pensamos y vivimos.
Ahora mismo, puede ser difícil de creer que la IA pueda tener tan inmenso impacto en el mundo, y eso es principalmente porque ésta aún no está ampliamente desplegada y aplicada, tanto como cuando en 1995 sería difícil de creer el impacto futuro del internet. Tiempo atrás, la gente no podría pronosticar como el internet sería tan relevante para ellos y como cambiaria dramáticamente sus vidas. Lo mismo es cierto para el AP y la IA en estos días. Pero no nos equivoquemos, la IA está por venir. En un futuro no muy distante, la AI será nuestro asistente personal, incluso nuestro amigo. Esta responderá nuestras preguntas, ayudara a educar a nuestros hijos, y estará pendiente de nuestro estado de salud. Nos enviara nuestros mercados a la puerta de la casa y nos llevara autónomamente de un punto A hacia un punto B. Sera nuestra interface en un mundo mucho más complejo y sensitivo a la información. Y, incluso más importante, la IA ayudara a la humanidad a progresar, asistiendo científicos humanos en nuevos descubrimientos de vanguardia a lo largo de todos los campos científicos, desde la genómica hasta las matemáticas.
En el camino, podríamos enfrentar algunos problemas e incluso un nuevo invierno de la IA, similar a lo experimentado por la industria del internet en el año 2000. Pero llegaremos allá, eventualmente. La IA terminara siendo aplicada en casi todo proceso que involucre a nuestra sociedad y nuestras vidas diarias, tal cual lo es el internet hoy en día.
No debemos creer en la exageración a corto plazo, pero debemos creer en la visión a largo plazo. Puede tomar mucho para que la IA sea desplegada a su verdadero potencial, un potencial del que algunos no hemos ni siquiera llegado a soñar, pero la IA está en camino, y transformara nuestro mundo de una manera fantástica.
Eso es todo por esta vez colegas. Aquellos interesados en profundizar un poco mas en estas ideas y obtener informacion adicional (en Ingles), les recomiendo revisar el increible libro Deep Learning with Python de Francois Chollet. Hasta la proxima y no olviden dejar sus aplausos y compartir el articulo si fue de su utilidad.