The post Diseñando prompts eficaces para la recogida de datos: estrategias y buenas prácticas first appeared on Planeta Chatbot.
]]>Así que, desde el surgimiento de la ingeniería de avisos, en este artículo, mostraremos cómo podemos usar avisos efectivos para la recolección de datos. Esto es lo que leerás aquí:
Table of contents:
Effective prompts for survey design
Prompt engineering for text annotation
– Sentiment analysis
– Named entity recognition
– Topic categorization
– Emotions classification
How prompt engineering can speed up the data extraction process
Putting it all togheter
Prompts eficaces para el diseño de encuestas
Una forma «histórica» o «clásica» de recopilar datos son las encuestas. Responder preguntas siempre ha ayudado a personas de diversos sectores a realizar investigaciones.
Hay que decir que la metodología ha cambiado con el tiempo, pero una encuesta sigue siendo una de las formas «base» de recopilar datos y todavía ayudamos a la gente a rellenarlas de diferentes maneras: en papel, por teléfono o por correo electrónico. Incluso los creadores recopilan datos a través de encuestas en las redes sociales y por correo electrónico (¡yo soy culpable!) para mejorar sus contenidos.
Así que, dada la importancia de las encuestas, ¿por qué no mejorarlas a través de la IA? O, simplemente: ¿qué harías si tuvieras que crear una encuesta, pero no sabes por dónde empezar?
Ya lo sé. Le preguntarías a ChatGPT.
Buena solución, pero hagámosla con un método.
He aquí algunos consejos para crear prompts eficaces y siempre válidos:
- Que sean concisas y directas. Las instrucciones deben ser siempre breves y directas. De hecho, las preguntas largas pueden confundir al modelo de IA y dar lugar a respuestas imprecisas. Por tanto, sé preciso y conciso.
- Evita la jerga y los términos técnicos. A menos que la recopilación de datos se dirija específicamente a un público especializado, es importante evitar el uso de jerga y términos técnicos. Pide a la IA que utilice un lenguaje sencillo que pueda ser fácilmente comprendido por un amplio abanico de individuos, si los datos van a ir dirigidos a personas con distintos conocimientos (especialmente en el caso de las encuestas).
- Haz una pregunta cada vez. Cada pregunta debe centrarse en un único concepto o cuestión. Hacer varias preguntas a la vez puede crear confusión y dificultar que la máquina proporcione respuestas precisas. Concéntrese en las preguntas y, si es necesario, divida las ideas complejas en varias preguntas.
Hagamos ahora algunos ejemplos puntuales de encuestas.
Podemos empezar con una encuesta de satisfacción del cliente sobre un producto concreto: «Generar preguntas de encuesta sobre la satisfacción del cliente para un producto. Las respuestas deben ser 5«.
Y obtenemos:
Aquí hay algunas preguntas de encuesta sobre la satisfacción del cliente para un producto, donde los encuestados pueden proporcionar respuestas en una escala de 1 a 5 (siendo 5 el nivel más alto de satisfacción):
1) ¿Cuál es su grado de satisfacción con la calidad general de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
2) ¿Cómo calificaría el rendimiento y la fiabilidad de nuestro producto?
1: Muy deficiente
2: Deficiente
3: Regular
4: Bueno
5: Excelente
3) ¿En qué medida satisface nuestro producto sus necesidades y expectativas?
1: En absoluto
2: Algo
3: Moderadamente
4: Mayoritariamente
5: Completamente
3) ¿En qué medida satisface nuestro producto sus necesidades y expectativas?
1: En absoluto
2: Algo
3: Moderadamente
4: Mayoritariamente
5: Completamente
4) ¿Cuál es su grado de satisfacción con el servicio de atención al cliente de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
5) ¿Qué probabilidades hay de que recomiende nuestro producto a otras personas?
1: Muy improbable
2: Improbable
3: Neutral
4: Probable
5: Muy probable
6) ¿Cómo calificaría la relación calidad-precio de nuestro producto?
1: Mala relación calidad-precio
2: Valor por debajo de la media
3: Valor medio
4: Buena relación calidad-precio
5: Excelente relación calidad-precio
7) ¿Cuál es su grado de satisfacción con la facilidad de uso de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
8) ¿Cuál es su grado de satisfacción con las características y funcionalidades de nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
9) ¿Cómo calificaría la durabilidad y longevidad de nuestro producto?
1: Muy mala
2: Deficiente
3: Regular
4: Buena
5: Excelente
10) ¿Cuál es su grado de satisfacción general con nuestro producto?
1: Muy insatisfecho
2: Insatisfecho
3: Neutral
4: Satisfecho
5: Muy satisfecho
Estas preguntas te ayudarán a calibrar los niveles de satisfacción de los clientes y a identificar los puntos fuertes y las áreas de mejora de tu producto. Recuerda analizar las respuestas cuidadosamente para obtener información valiosa y tomar decisiones informadas para mejorar la satisfacción del cliente.
No soy un experto en encuestas, pero considero que las preguntas proporcionadas por ChatGPT son una buena encuesta.
Ahora una pregunta: ¿podemos hacer algo mejor? Dijimos que teníamos que ser específicos, pero, efectivamente, no lo fuimos.
Para ser más precisos, podemos introducir una pregunta como esta: «Generar preguntas de encuesta sobre la satisfacción del cliente para un producto digital que ayuda a la gente a aprender IA. Las respuestas deben ser 3«.
Y obtenemos:
Por supuesto. He aquí algunas preguntas de encuesta sobre la satisfacción de los clientes de un producto digital que ayuda a aprender IA, en las que los encuestados pueden dar respuestas en una escala de 1 a 3 (siendo 3 el nivel más alto de satisfacción):
1) ¿Está satisfecho con el contenido de nuestro producto de aprendizaje de IA?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
2) ¿Cómo calificaría la claridad y comprensibilidad del material didáctico?
1: Poco claro y difícil de entender
2: Algo claro y comprensible
3: Muy claros y comprensibles
3) ¿Hasta qué punto nuestro producto de aprendizaje de IA ha cumplido sus expectativas?
1: No ha cumplido las expectativas
2: Cumple parcialmente las expectativas
3: Cumple totalmente las expectativas
4) ¿Cuál es su grado de satisfacción con la organización y estructura de los módulos de aprendizaje?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
5) ¿En qué medida le resultan útiles los ejercicios prácticos y los proyectos prácticos de nuestro producto de aprendizaje de IA?
1: No son útiles
2: Algo útiles
3: Muy útil
6) ¿Cuál es su grado de satisfacción con la disponibilidad y accesibilidad del apoyo y la asistencia?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
7) ¿Le parecen eficaces los cuestionarios y evaluaciones interactivos para reforzar su aprendizaje?
1: Poco eficaces
2: Algo eficaces
3: Muy eficaz
8) ¿Cuál es su grado de satisfacción con la interfaz de usuario y la navegación de nuestra plataforma de aprendizaje de IA?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
9) ¿Cómo calificaría la relevancia y aplicabilidad de los conceptos y técnicas de IA que se enseñan en nuestro producto de aprendizaje?
1: No relevante o aplicable
2: Algo relevantes y aplicables
3: Muy relevantes y aplicables
10) ¿Cuál es su grado de satisfacción con la experiencia general de aprendizaje que ofrece nuestro producto de aprendizaje de IA?
1: No estoy satisfecho
2: Algo satisfecho
3: Muy satisfecho
Estas preguntas te ayudarán a evaluar los niveles de satisfacción de los clientes con tu producto y a identificar las áreas en las que se pueden realizar mejoras. El análisis de las respuestas te proporcionará información valiosa para mejorar la experiencia de aprendizaje y satisfacer eficazmente las necesidades de sus clientes.
Como podemos ver, si somos más específicos con la pregunta, la encuesta mejora. Podemos ver, de hecho, que las preguntas de las dos encuestas son similares, pero hay algunas diferencias.
Por ejemplo, consideremos la pregunta 9 debido a la primera indicación: «¿Cómo calificaría la durabilidad y longevidad de nuestro producto?«. ¿Podría relacionarse de algún modo con un producto de IA? Bueno, depende, pero quizá no. Sin embargo, la pregunta 9 del segundo intento es: «¿Cómo calificaría la relevancia y aplicabilidad de los conceptos y técnicas de IA que se enseñan en nuestro producto de aprendizaje?». Esta pregunta es mucho más directa y concisa, ¿no crees?
Ingeniería para la anotación de textos
La anotación de datos es el proceso de etiquetar (o anotar) datos en bruto con información adicional para hacerlos utilizables para algoritmos de ML.
En concreto, la anotación de datos, en lo que respecta a los datos de texto, es el proceso de añadir anotaciones al texto para añadir estructura o información adicional. Dependiendo de la tarea y los requisitos particulares, las anotaciones pueden contener una variedad de etiquetas, incluyendo etiquetas de sentimiento, entidades con nombre, etiquetas de parte de discurso, estructura gramatical, etiquetas de intención, etiquetas de categorización y más.
La ingeniería de prompts puede ayudarnos en las tareas de anotación de datos, haciendo que el proceso de recopilación de anotaciones a partir de texto sea automatizable y rápido. De hecho, proporcionando instrucciones específicas, el modelo puede generar prompts para extraer anotaciones para el análisis de sentimientos, el reconocimiento de entidades con nombre o cualquier otra tarea de clasificación de texto.
Veamos algunos ejemplos.
Análisis de sentimientos
El análisis de sentimientos es un subcampo del Procesamiento del Lenguaje Natural (NLP) que nos ayuda a comprender si un texto concreto tiene un sentimiento positivo, negativo o neutro. En estos casos, necesitamos un texto y queremos pedir a nuestra IA que clasifique su sentimiento.
Una pregunta puede ser algo como: «Analiza el sentimiento de la siguiente frase y etiquétala como positiva, negativa o neutra«. O «Clasifica el sentimiento de la siguiente frase en una de las categorías: positivo, negativo o neutro«.
Por ejemplo: «Analice el sentimiento de la frase dada y etiquétela como positiva, negativa o neutra» y obtenemos:
Basándose en la frase dada, el sentimiento puede clasificarse como negativo. La frase «decepción total» sugiere un fuerte sentimiento negativo, indicando que la película no cumplió las expectativas del hablante. La mención de «esperaba mucho más» refuerza aún más el sentimiento negativo, expresando una sensación de insatisfacción. Por lo tanto, la etiqueta de sentimiento para esta frase sería negativa.
Reconocimiento de entidades con nombre
El reconocimiento de entidades con nombre (NER) es el proceso de localizar y clasificar determinados tipos de información que se encuentran en los datos brutos. En concreto, es la tarea de identificar entidades, como personas, lugares y organizaciones, en un texto en lenguaje natural.
Como ya hemos señalado, los prompts deben ser precisas, concisas y lo más breves posible. En el caso de NER, tenemos que ser muy específicos, sobre todo en lo que respecta al campo de dominio.
Así, por ejemplo, algunos prompts pueden ser:
- «Extraer todos los nombres de persona del texto dado»
- «Identificar y clasificar todas las organizaciones mencionadas en el documento»
- «Detectar y clasificar todos los términos jurídicos y entidades del documento», etc.
Así, por ejemplo, podemos introducir la siguiente consulta: «Encuentra y clasifica todas las ubicaciones y empresas mencionadas en el párrafo: «Apple y Facebook son considerados gigantes tecnológicos de Silicon Valley». Y obtenemos:
Aquí está la categorización de lugares y empresas mencionados en el párrafo dado:
Ubicaciones: Silicon Valley
Empresas: Apple y Facebook
En este ejemplo, «Silicon Valley» se categoriza como ubicación, mientras que «Apple» y «Facebook» se categorizan como empresas.
Categorización por temas
La categorización por temas es una forma de organizar el texto que ayuda al lector a comprender el tema principal del texto y ver cómo se desarrolla. Cuando un texto se categoriza, se divide en partes más pequeñas que son más fáciles de entender.
Por ejemplo, un texto sobre la historia del baloncesto puede clasificarse en los apartados de historia, jugadores, equipos y deportes. Las indicaciones eficientes pueden ser:
- «Basándose en el contenido del texto, clasifíquelo como ‘Deportes’, ‘Política’, ‘Entretenimiento’ o ‘Tecnología'».
- «Clasifique el siguiente texto como ‘Salud y bienestar’, ‘Negocios y finanzas’, o ‘Ciencia y tecnología’, en función de su temática».
- «Determine si el siguiente texto debe categorizarse como ‘Historia’, ‘Literatura’, ‘Filosofía’, o ‘Religión’, en función de su contenido».
Veamos el efecto de los prompts genéricos con respecto a un específico. Por ejemplo, consideremos los dos primeros párrafos de este artículo. Una pregunta genérica podría ser:
«Por favor, clasifique el siguiente texto en los temas apropiados:
El nómada digital se ha convertido en un personaje icónico de la era moderna del trabajo a distancia. Las palabras suelen evocar la imagen de un escritor profesional o un trabajador tecnológico con un ordenador, deambulando por las calles de una pintoresca ciudad extranjera o tecleando en un café frente al mar.
Ven mundo, conocen gente nueva, trabajan en su tiempo libre. Los nómadas digitales son muchos tipos diferentes de trabajadores. Algunos son autónomos o contratistas independientes; otros son emprendedores que crean su propia empresa; y otros trabajan en puestos remotos a tiempo completo para empresas de todo el mundo.
Algunos son asalariados, mientras que otros dependen de ingresos ad hoc. En general, dicen los expertos, muchos de estos trabajadores son de cuello blanco y tienen una buena formación.»
Y obtenemos:
Posibles categorizaciones para el texto dado:
- Estilo de vida nómada digital
- Cultura del trabajo a distancia
- Emprendimiento y trabajo autónomo
- Equilibrio trabajo-vida privada
- Mano de obra global y colaboración internacional
- Oportunidades económicas y diversidad de ingresos
- Factores socioeconómicos en el nomadismo digital
- Flexibilidad profesional y trabajo independiente
- Impacto de la tecnología en el trabajo y los viajes
- Diversidad de la mano de obra e inclusión en el trabajo a distancia
Ten en cuenta que las categorizaciones pueden variar en función del contexto y de los requisitos específicos de la tarea de categorización.
En realidad son muchos temas. Por lo tanto, utilicemos un estímulo específico como: «Determine si el siguiente texto debe clasificarse como ‘tecnología’ o ‘trabajo’, basándose en su tema principal«:
El nómada digital se ha convertido en un personaje icónico de la era moderna del trabajo a distancia. Las palabras suelen evocar la imagen de un escritor profesional o un trabajador tecnológico con un ordenador, deambulando por las calles de una pintoresca ciudad extranjera o tecleando en un café frente al mar.
Ven mundo, conocen gente nueva, trabajan en su tiempo libre. Los nómadas digitales son muchos tipos diferentes de trabajadores. Algunos son autónomos o contratistas independientes; otros son emprendedores que crean su propia empresa; y otros trabajan en puestos remotos a tiempo completo para empresas de todo el mundo.
Algunos son asalariados, mientras que otros dependen de ingresos ad hoc. En general, dicen los expertos, muchos de estos trabajadores son de cuello blanco y tienen una buena formación.»
Y así nos va:
Por su tema principal, el siguiente texto debería clasificarse como «trabajo».
Algunos son asalariados, mientras que otros dependen de ingresos ad hoc. En general, dicen los expertos, muchos de estos trabajadores son de cuello blanco y tienen una buena formación.»
Y así nos va:
Por su tema principal, el siguiente texto debería clasificarse como «laboral».
Clasificación de emociones
La clasificación de emociones es el arte de extraer emociones del texto, es decir, nuestro algoritmo puede etiquetar un texto según exprese sentimientos positivos o negativos.
Por ejemplo, si escribo: «Estoy contento porque hoy brilla el sol», este texto se etiquetaría como «contento».
Por tanto, unas instrucciones eficaces pueden ser:
- «Detectar y etiquetar emociones en las siguientes publicaciones en redes sociales, distinguiendo entre emociones positivas (por ejemplo, alegría) y negativas (por ejemplo, enfado)».
- «Clasificar el tono emocional (por ejemplo, humorístico, sarcástico, melancólico) de la siguiente entrada de blog basándose en su contenido textual».
Por ejemplo, utilicemos este artículo para hacer un ejemplo: «Clasifica el tono emocional, distinguiendo entre emociones positivas (por ejemplo, alegría) y negativas (por ejemplo, enfado), del siguiente texto:
«Es increíble saber que estoy por delante de ambos en Grand Slams, pero al mismo tiempo cada uno escribe su propia historia», dijo Djokovic, que también recuperó el número uno del mundo en París.
«Siento que cada gran campeón de su propia generación ha dejado una enorme huella y un legado».
«Tengo una fe, una confianza y una fe enormes en mí mismo y en todo lo que soy, en quién soy y en lo que soy capaz de hacer».
«Este trofeo es otra confirmación de la calidad del tenis que todavía soy capaz de producir».
Djokovic intentará empatar el récord de Court en Wimbledon, un lugar donde ya ha ganado siete veces y será el favorito para igualar el récord de títulos masculinos de Federer.
«Los Grand Slams son las mayores prioridades en la lista de control, no sólo esta temporada, sino cualquier temporada, especialmente en esta etapa de mi carrera», dijo Djokovic.
«El viaje aún no ha terminado. Si estoy ganando Slams, ¿por qué pensar siquiera en poner fin a una carrera que ya dura 20 años?».
«Sigo sintiéndome motivado e inspirado para jugar el mejor tenis en estos torneos».
«Estos son los que más cuentan en la historia de nuestro deporte».
Y lo conseguimos:
El tono emocional del texto es principalmente positivo. He aquí el desglose:
Emociones positivas
- Alegría/amistad: «Es increíble saber que estoy por delante de los dos en Grand Slams»
- Confianza/creencia: «Tengo una enorme fe, confianza y creencia en mí mismo»
- Confirmación/satisfacción: «Este trofeo es otra confirmación de la calidad de tenis que aún soy capaz de producir».
- Motivación/inspiración: «Sigo sintiéndome motivado e inspirado para jugar el mejor tenis en estos torneos».
- Prioridades: «Los Grand Slams son las mayores prioridades en la lista de control, no sólo esta temporada sino cualquier temporada»
Emociones neutras
- Reconocimiento: «pero al mismo tiempo cada uno escribe su propia historia» (neutral, constatando un hecho).
- Legado/marca: «cada gran campeón de su generación ha dejado una gran huella y un legado» (neutral, reconoce el impacto)
En general, el texto expresa emociones positivas como alegría, confianza, satisfacción, motivación e inspiración.
Cómo la ingeniería rápida puede acelerar el proceso de extracción de datos
La extracción de datos es una parte fundamental de un flujo de trabajo de Data Science porque, como es comprensible, nos proporciona los datos que necesitamos analizar.
Sin embargo, aunque podamos utilizar algún lenguaje de programación para automatizar la extracción de datos, a veces el proceso no es sencillo porque podemos necesitar desarrollar mucho código. Pensemos, por ejemplo, en el proceso de extracción de datos de un archivo PDF o de un sitio web (web scraping): esto puede requerir mucho tiempo y código.
Sin embargo, hoy en día existen muchas herramientas que, dada una determinada orden, pueden extraer los datos que necesitamos de diversas fuentes.
Así, imaginemos que tenemos un PDF con una tabla como ésta:
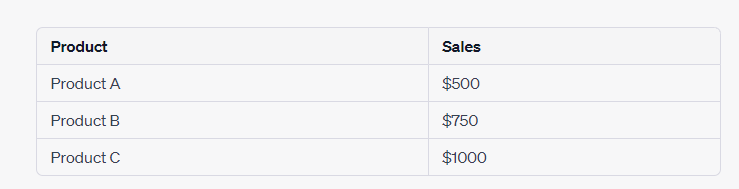
Una pregunta eficaz puede ser: «Extrae los valores de la columna ‘Ventas’ de la siguiente tabla«.
Y obtendríamos:
Claro, aquí está la salida deseada: [«$500», «$750», «$1000»]
Otra pregunta puede ser: «Extraiga los nombres y los números de teléfono del siguiente texto:
John Doe — john.doe@example.com — (555) 123–4567
Jane White — j.white@example.com — (111) 564–0981
Sam Simons — sam-simons@example.com — (123) 467–0987
Tricia Hawking — hawking.tricia@example.com — (012) 809–111”
Y obtenemos:
Aquí están los nombres y números de teléfono extraídos del texto proporcionado:
John Doe — (555) 123–4567
Jane White — (111) 564–0981
Sam Simons — (123) 467–0987
Tricia Hawking — (012) 809–111
Así que, como de costumbre, los prompts tienen que ser específicos. De hecho, en un caso como el anterior, escribir «extraer todos los datos del texto proporcionado» daría como resultado la extracción incluso de los correos electrónicos, pero en este caso no nos interesaban.
Ponerlo todo junto
Para una mejor comprensión, hemos separado las indicaciones en categorías, para poder hacer mejores ejemplos.
Pero la realidad es siempre más compleja que los ejemplos básicos, y puede que necesitemos clasificar el texto con referencias que estén «intercategorizadas».
Por ejemplo, consideremos este artículo. Queremos saber
- El día.
- La ubicación.
- Las emociones del Primer Ministro.
- El tema entre la actualidad y la crónica.
Extraiga el día, la ubicación, las emociones del Primer Ministro entre feliz y triste, y el tema entre la actualidad y la crónica en el siguiente texto:
Al menos 10 personas han muerto y otras 25 están hospitalizadas tras estrellarse un autobús de bodas en una región vinícola australiana.
Los pasajeros regresaban de una boda en una bodega el domingo por la noche en Hunter Valley, un lugar popular entre los enoturistas, cuando el autocar volcó.
La policía ha acusado al conductor del autobús, de 58 años, de 10 cargos de conducción peligrosa con resultado de muerte.
La policía informó de que aún se estaba identificando a los fallecidos.
Sin embargo, no se informó de que los recién casados estuvieran en el autobús.
La comisaria de policía Karen Webb dijo que el lugar del accidente es «todavía una escena del crimen activa». «Tenemos agentes forenses procesando la escena del crimen, tenemos agentes de la unidad de investigación de accidentes, tenemos agentes de rescate [en la escena]», añadió.
El accidente se produjo sobre las 23.30 hora local [13.30 GMT] cuando, según la policía, había niebla espesa en la zona. El autobús volcó al girar en una rotonda a la salida de una autopista. Según las autoridades, el vehículo ya ha sido puesto en posición vertical.
El subcomisario interino de la policía de Nueva Gales del Sur, Tracy Chapman, declaró que los pasajeros se dirigían a Singleton «presumiblemente para alojarse». Dos de los supervivientes fueron trasladados en helicóptero. Los medios de comunicación locales informan de que al menos uno de ellos sigue en estado crítico.
El Primer Ministro australiano, Anthony Albanese, declaró que es «tan cruel, tan triste y tan injusto» que un «día alegre en un lugar tan hermoso como éste termine con una pérdida de vidas tan terrible».»
Y obtenemos:
Día y hora: Domingo por la noche
Lugar: Hunter Valley, Australia
Emociones del Primer Ministro: Triste
Tema Crónica
Las emociones del Primer Ministro expresadas en el texto son tristes. Describe el incidente como «tan cruel, tan triste y tan injusto» que un «día alegre en un lugar tan hermoso como ese acabe con una pérdida de vidas tan terrible.»
Bueno, yo diría que esto está perfectamente clasificado. Pero, como hemos visto, la pregunta es muy específica. Si preguntáramos «las emociones del Primer Ministro», por ejemplo, la respuesta no sería tan precisa.
Por lo tanto, los prompt dan resultados precisos, solo si son precisos.
Conclusiones
En este artículo hemos visto cómo crear prompts eficaces para la recopilación de datos.
La ingeniería de prompts es una posibilidad de oro que nos brinda la IA para acelerar este proceso.
Recuerda las reglas de oro para proporcionar instrucciones breves, precisas y concisas y los resultados serán sorprendentes.
The post Diseñando prompts eficaces para la recogida de datos: estrategias y buenas prácticas first appeared on Planeta Chatbot.
]]>The post Cómo resolver problemas de dependencia de Python con Anaconda en Windows first appeared on Planeta Chatbot.
]]>En los últimos días, he tenido algunos problemas con las dependencias de Python en mi máquina Windows. Intenté instalar nuevos paquetes para probarlos.
Efectivamente, se instalaron y pude ver todos los detalles con $ pip show [nombre_de_la_biblioteca] pero cuando intenté importar la biblioteca instalada un minuto antes obtuve problemas de importación. Tuve estos problemas utilizando Jupyter Notebooks, así que pensé que era de alguna manera un problema relacionado con Anaconda. Esto es lo que hice para tratar de resolver el problema:
-
- Intenté cambiar la ruta absoluta donde todos los paquetes de Python (y Anaconda) estaban instalados, pero resultó en un bloqueo de Anaconda. Así que tuve que restaurar las rutas absolutas anteriores.
-
- Probé la «fuerza bruta»: Abrí VS CODE e instalé las librerías que quería usar en un entorno virtual. ¿Y sabéis qué? Tuve diferentes problemas de dependencias…
Así que, después de 2-3 horas de problemas, decidí usar la mayor fuerza bruta posible, y tenía tres posibilidades:
-
- Desinstalar y volver a instalar Python y Anaconda, pero esto no resolvería los problemas reales por varias razones (algunos archivos que pueden permanecer en la carpeta actual podría, de todos modos, dejar que las rutas siguen siendo las mismas y crear los mismos problemas, por ejemplo).
-
- Desinstalar y volver a instalar Windows en mi máquina.
-
- Instalar Anaconda en una máquina virtual Ubuntu.
Por supuesto, no quería reinstalar Windows, así que decidí usar la tercera forma, y te muestro cómo hacerlo, para que puedas usar esta metodología si la necesitas.
Por último, cómo utilizo Python principalmente para Data Science, quería instalar Anaconda en mi máquina Linux para tener ya todas las librerías relacionadas con datos que necesito (y mucho más que esas).
Pero antes de seguir… ten en cuenta que estaba intentando instalar algunas librerías de Python menos conocidas, pero potentes, para la manipulación de datos y el cálculo científico. Las describo en el siguiente artículo.
Paso 1: instalar una máquina virtual Linux en Windows
El primer paso que debes realizar es instalar una máquina virtual Linux en tu máquina Windows.
Describo este procedimiento en el siguiente artículo en el apartado «Cómo utilizar bash en Windows«:
No te preocupes: no necesitas ser un «mago de la informática» (¡yo no lo soy!). El procedimiento es bastante sencillo.
Paso 2: actualizar el sistema operativo
Después de haber instalado una máquina virtual Linux, inicia el terminal Linux a través de «MobaXterm» (como se describe en el artículo mencionado anteriormente), por ejemplo, y actualiza el sistema a través de:
$ sudo apt update
$ sudo apt upgrade
Paso 3: DescargA el archivo de instalación:
Ahora puedes descargar el archivo de instalación de Anaconda así:
Paso 4: ejecutar el archivo de instalación
Al ejecutar el comando wget como en el paso anterior, al final del proceso el software devolverá el nombre del archivo de instalación. Es algo así:

Copia el nombre del archivo y ejecútelo así:
$ bash Anaconda3-2023.03-1-Linux-x86_64.sh
Se pedirá que pulses «ENTER» varias veces.
A continuación, pulse «sí» para aceptar las condiciones de instalación al final del proceso.
Paso 5: reiniciar el entorno para hacer efectiva la instalación
Tras aceptar la condición en los pasos anteriores, el software te pedirá que cierres y abras tu shell (también conocido como MobaXterm si lo has utilizado) para hacer efectiva la instalación:

Cuando vuelvas a abrir el intérprete de comandos, puedes verificar la instalación de Anaconda escribiendo:
$ conda –version
Y en mi caso, lo consigo:
Paso 6: lanzar Jupyer Notebook
Ok, Anaconda está instalado, y para lanzar un Jupyter Notebook sólo tienes que escribir lo siguiente a través de MobaXterm:
$ jupyter notebook
¡y ya puedes empezar a utilizarlo!
Paso 7: instalar otras librerías
Ahora, para instalar otras librerías que puedas necesitar (¡como en mi caso!), puedes usar WSL, así todo estará «conectado», desde el punto de vista de dependencias, al entorno WSL y ya no tendrás problemas.
Esto se debe a que el entorno WSL y el entorno Windows están separados, y también lo están sus dependencias.
En otras palabras, simplemente abre tu MobaXterm (o lo que estés usando), escribe pip install [new_library] y todo funcionará bien (¡hasta que rompamos algo nuevo!).
Conclusiones
En este artículo, hemos visto cómo podemos instalar un entorno virtual Linux para instalar Python y todas sus dependencias cuando tenemos problemas al respecto en una máquina Windows.
Parece largo pero, créeme: He luchado lo suficiente con las otras formas que describí al principio de este artículo como para decirte que ésta es la forma más rápida (y segura) de hacerlo.
The post Cómo resolver problemas de dependencia de Python con Anaconda en Windows first appeared on Planeta Chatbot.
]]>The post Construyendo visualizaciones interactivas de datos con Python: una introducción a Plotly first appeared on Planeta Chatbot.
]]>En este artículo, vamos a hablar de Plotly, una biblioteca de Python para hacer visualizaciones interactivas.
La visualización de datos es una de las tareas más importantes para los profesionales de los datos. Nos ayuda, de hecho, a comprender los datos y a plantearnos más preguntas para investigaciones posteriores. Pero la visualización de datos no es sólo una tarea que tengamos que concluir en la fase de Análisis Exploratorio de Datos. También podemos necesitar presentar los datos, a menudo a un público para ayudarle a sacar algunas conclusiones.
En Python, generalmente utilizamos matplotlib y seaborn como bibliotecas para trazar nuestros gráficos. Sin embargo, a veces podemos necesitar algunas visualizaciones interactivas. En algunos casos, para una mejor comprensión de los datos. En otros casos, simplemente para presentar mejor nuestras soluciones.
¿Qué es Plotly?
Como podemos leer en su página web:
La librería de gráficos Python de Plotly crea gráficos interactivos de calidad editorial. Ejemplos de cómo hacer gráficos de líneas, gráficos de dispersión, gráficos de área, gráficos de barras, barras de error, gráficos de caja, histogramas, mapas de calor, subparcelas, múltiples ejes, gráficos polares y gráficos de burbujas.
Plotly.py es libre y de código abierto y se puede ver la fuente, informar de problemas o contribuir en GitHub. Así pues, Plotly es una biblioteca Python gratuita y de código abierto para realizar visualizaciones interactivas.
Como podemos ver en su página web, nos da la posibilidad de crear gráficos para diferentes ámbitos: AI/ML, estadístico, científico, financiero, y mucho más.
Ya que estamos interesados en Machine Learning y Data Science, vamos a mostrar algunos plots relacionados con este campo y cómo crearlos en Python.
Por último, para instalarlo, tenemos que teclear:
$ pip install plotly
1. Gráficos de burbujas interactivos
Una característica interesante y útil de Plotly que podemos utilizar es la posibilidad de gráficos de burbujas interactivos.
En el caso de los gráficos de burbujas, de hecho, a veces las burbujas pueden intersecarse, dificultando la lectura de los datos. En cambio, si el gráfico es interactivo, podemos leer los datos más fácilmente.
Veamos un ejemplo:
import plotly.express as px
import pandas as pd
import numpy as np
# Generate random data
np.random.seed(42)
n = 50
x = np.random.rand(n)
y = np.random.rand(n)
z = np.random.rand(n) * 100 # Third variable for bubble size
# Create a DataFrame
data = pd.DataFrame({‘X’: x, ‘Y’: y, ‘Z’: z})
# Create the scatter plot with bubble size with Plotly
fig = px.scatter(data, x=‘X’, y=‘Y’, size=‘Z’,
title=‘Interactive Scatter Plot with Bubble Plot’)
# Add labels to the bubbles
fig.update_traces(textposition=‘top center’, textfont=dict(size=11))
# Update layout properties
fig.update_layout(
xaxis_title=‘X-axis’,
yaxis_title=‘Y-axis’,
showlegend=False
)
# Display the interactive plot
fig.show()
Y conseguimos:
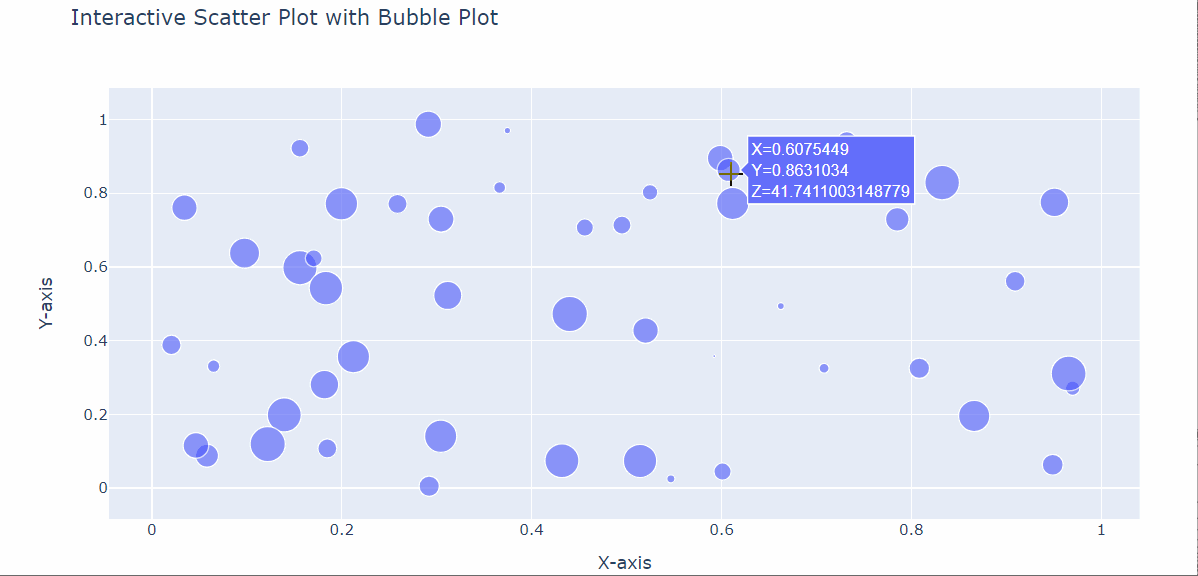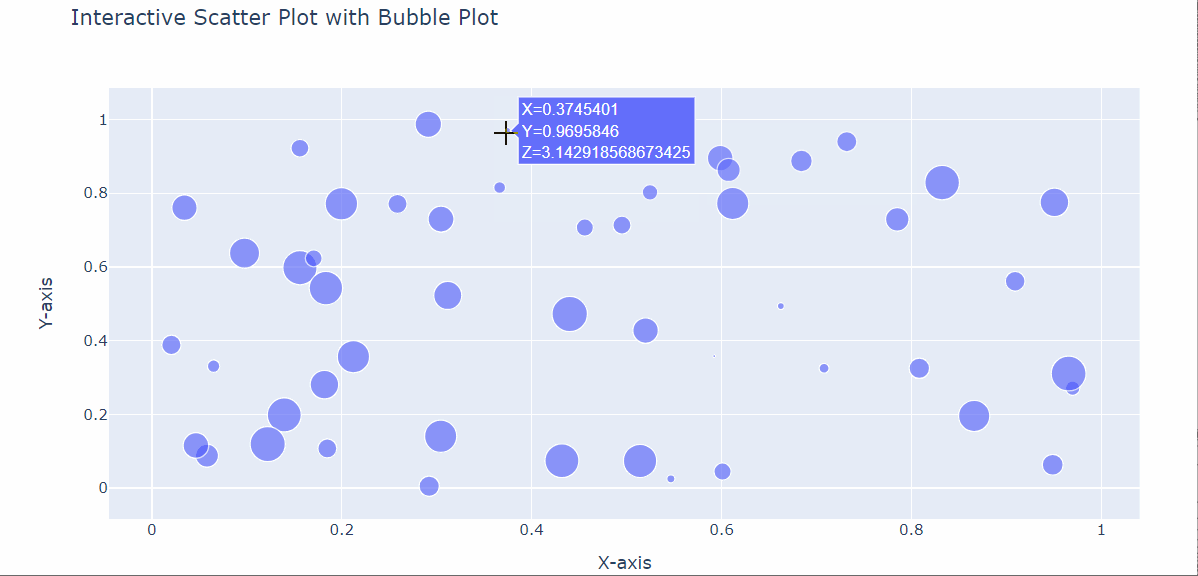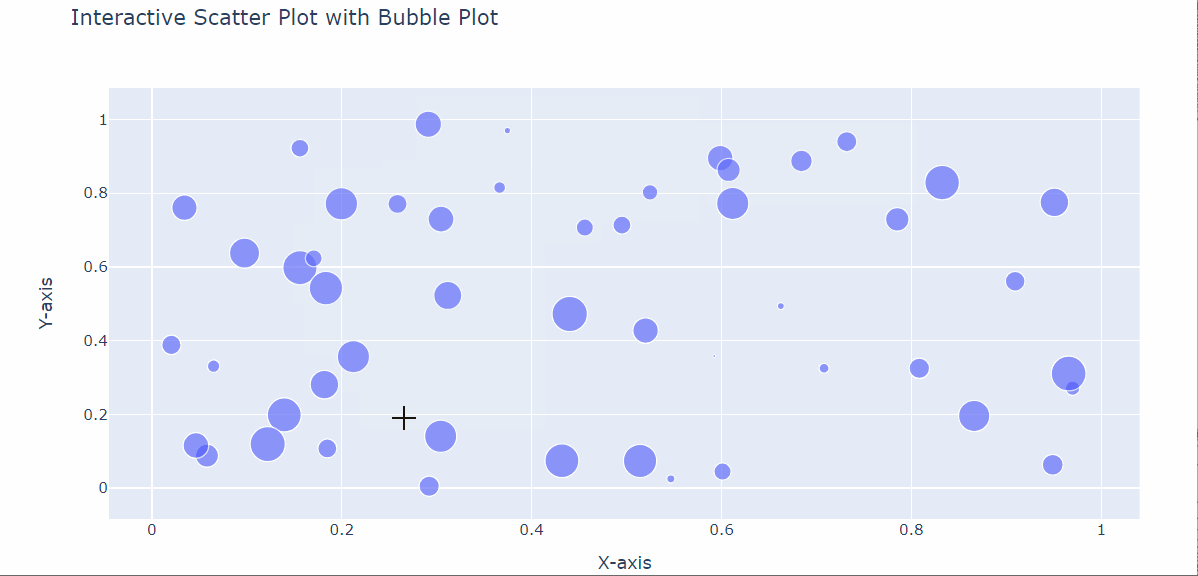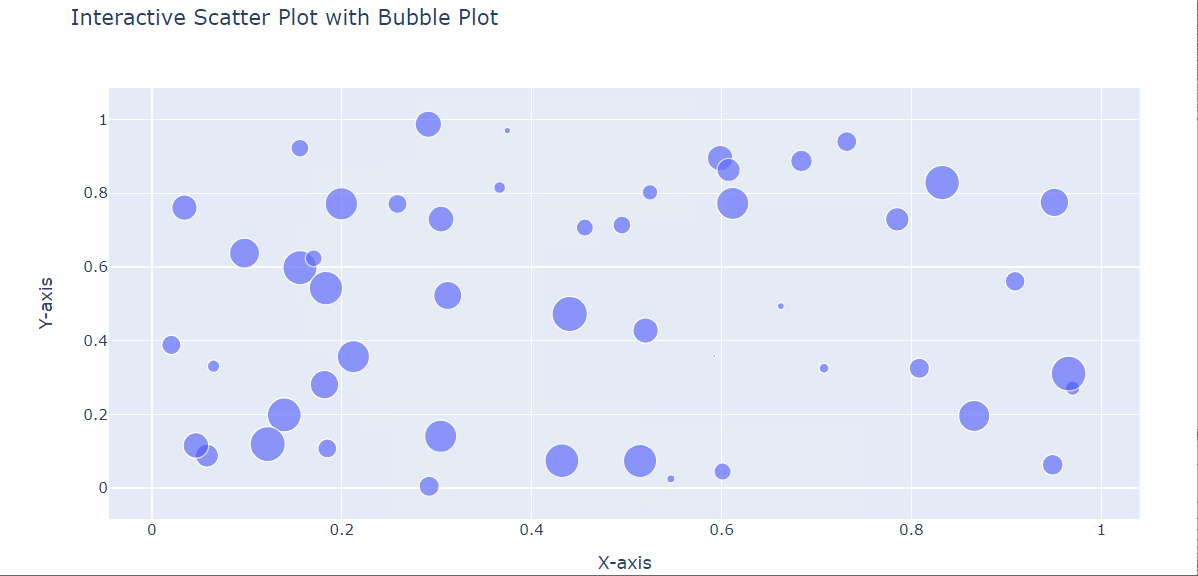
Así, hemos creado algunos datos con NumPy y los hemos almacenado en un marco de datos de Pandas. A continuación, hemos creado el gráfico interactivo con el método px.scatter() recuperando los datos del marco de datos, y especificando el título (a diferencia de Matplotlib en el que insertamos el título fuera del método utilizado para crear el propio gráfico).
2. Matrices de correlación interactivas
Una de las tareas con las que a veces lucho es la visualización adecuada de las matrices de correlación. Estas, de hecho, a veces pueden ser difíciles de leer y visualizar cuando tenemos muchos datos.
Una forma de resolver el problema es utilizar Plotly para crear una visualización interactiva.
Para el ámbito de aplicación, vamos a crear un marco de datos Pandas con 10 columnas y crear una matriz de correlación interactiva con Plotly:
import pandas as pd
import numpy as np
import plotly.figure_factory as ff
# Create random data
np.random.seed(42)
data = np.random.rand(100, 10)
# Create DataFrame
columns = [‘Column’ + str(i+1) for i in range(10)]
df = pd.DataFrame(data, columns=columns)
# Round values to 2 decimals
correlation_matrix = df.corr().round(2)
# Create interactive correlation matrix with Plotly
figure = ff.create_annotated_heatmap(
z=correlation_matrix.values,
x=list(correlation_matrix.columns),
y=list(correlation_matrix.index),
colorscale=‘Viridis’,
showscale=True
)
# Set axis labels
figure.update_layout(
title=‘Correlation Matrix’,
xaxis=dict(title=‘Columns’),
yaxis=dict(title=‘Columns’)
)
# Display the interactive correlation matrix
figure.show()
Y conseguimos:
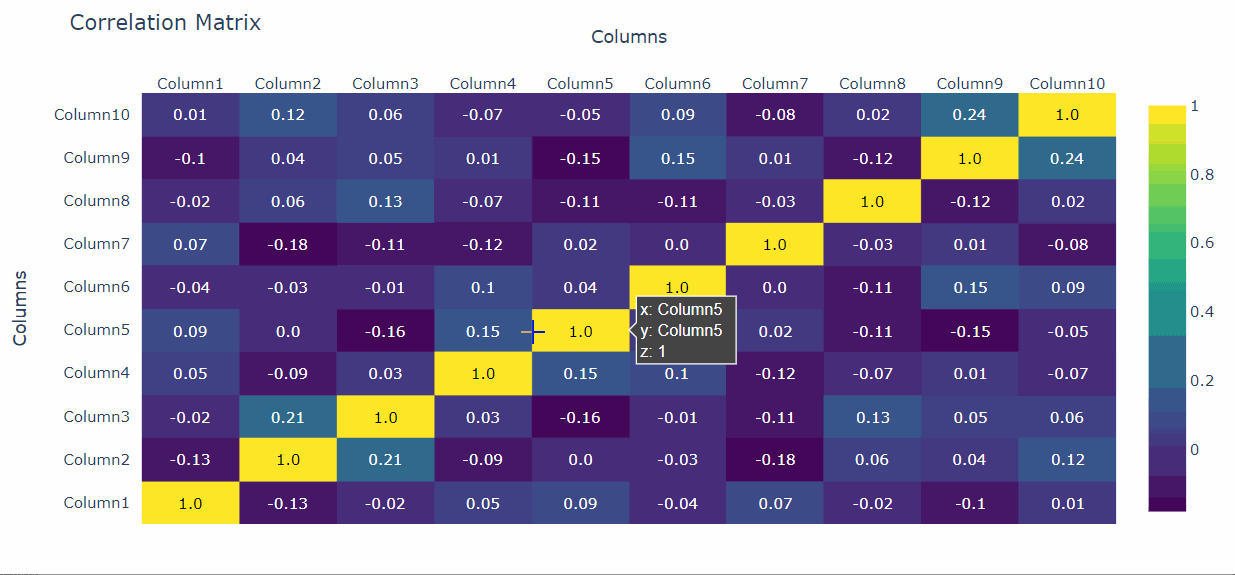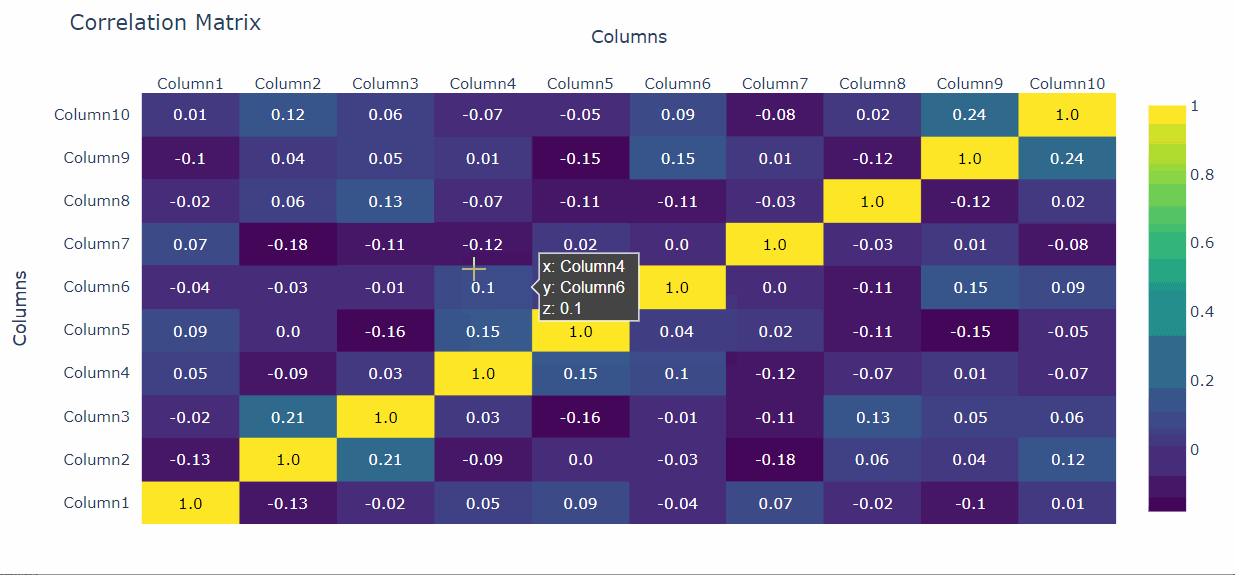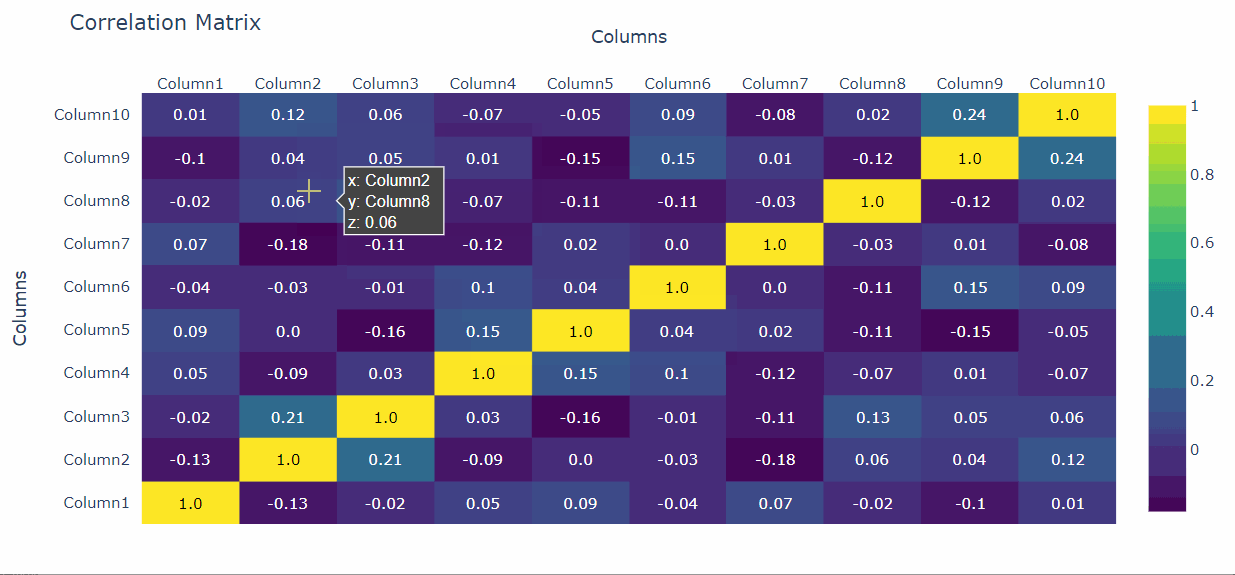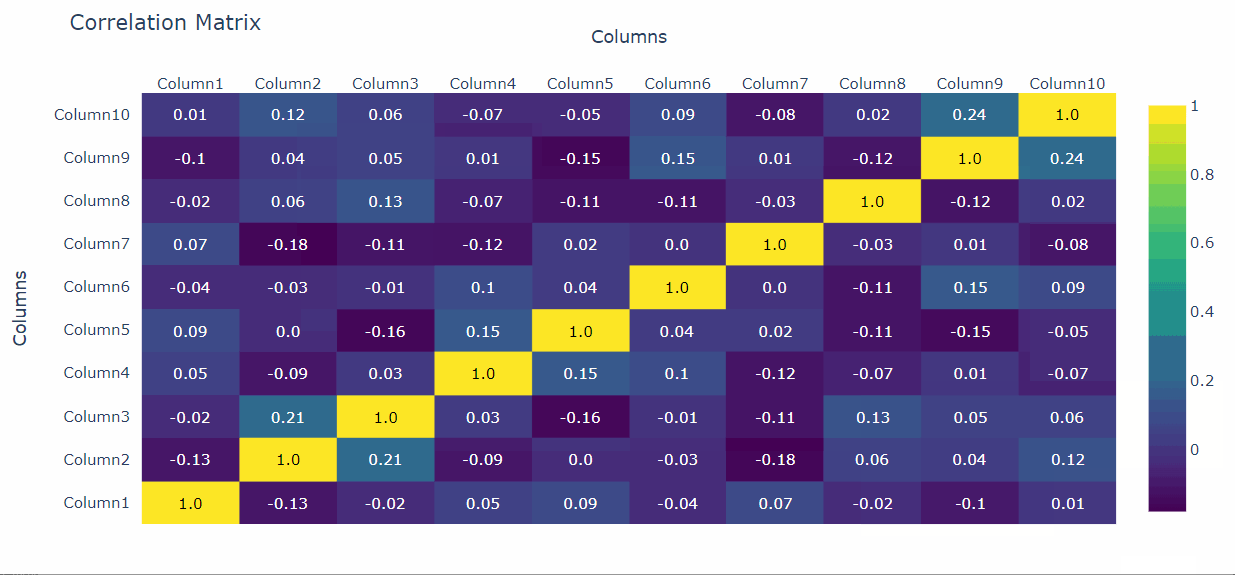
Así, de forma muy sencilla, podemos crear una matriz de correlaciones interactiva con el método ff.create_annotated_map().
3. Gráficos interactivos de ML
En Machine Learning, a veces necesitamos comparar cantidades gráficamente. Y, en estos casos, a veces es difícil leer nuestros gráficos.
El caso típico es una curva ROC/AUC donde comparamos el rendimiento de diferentes modelos ML. A veces, de hecho, las curvas se interceptan y no somos capaces de visualizarlas correctamente.
Para mejorar nuestras visualizaciones, podemos utilizar Plotly para crear una curva ROC/AUC como esta:
import pandas as pd
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import roc_curve, auc
import plotly.graph_objects as go
# Create synthetic binary classification data
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# Scale the data using StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# Initialize the models
knn = KNeighborsClassifier()
rf = RandomForestClassifier()
dt = DecisionTreeClassifier()
svm = SVC(probability=True)
# Fit the models on the train set
knn.fit(X_train, y_train)
rf.fit(X_train, y_train)
dt.fit(X_train, y_train)
svm.fit(X_train, y_train)
# Predict probabilities on the test set
knn_probs = knn.predict_proba(X_test)[:, 1]
rf_probs = rf.predict_proba(X_test)[:, 1]
dt_probs = dt.predict_proba(X_test)[:, 1]
svm_probs = svm.predict_proba(X_test)[:, 1]
# Calculate the false positive rate (FPR) and true positive rate (TPR) for ROC curve
knn_fpr, knn_tpr, _ = roc_curve(y_test, knn_probs)
rf_fpr, rf_tpr, _ = roc_curve(y_test, rf_probs)
dt_fpr, dt_tpr, _ = roc_curve(y_test, dt_probs)
svm_fpr, svm_tpr, _ = roc_curve(y_test, svm_probs)
# Calculate the AUC (Area Under the Curve) for ROC curve
knn_auc = auc(knn_fpr, knn_tpr)
rf_auc = auc(rf_fpr, rf_tpr)
dt_auc = auc(dt_fpr, dt_tpr)
svm_auc = auc(svm_fpr, svm_tpr)
# Create an interactive AUC/ROC curve using Plotly
fig = go.Figure()
fig.add_trace(go.Scatter(x=knn_fpr, y=knn_tpr, name=‘KNN (AUC = {:.2f})’.format(knn_auc)))
fig.add_trace(go.Scatter(x=rf_fpr, y=rf_tpr, name=‘Random Forest (AUC = {:.2f})’.format(rf_auc)))
fig.add_trace(go.Scatter(x=dt_fpr, y=dt_tpr, name=‘Decision Tree (AUC = {:.2f})’.format(dt_auc)))
fig.add_trace(go.Scatter(x=svm_fpr, y=svm_tpr, name=‘SVM (AUC = {:.2f})’.format(svm_auc)))
fig.update_layout(title=‘AUC/ROC Curve’,
xaxis=dict(title=‘False Positive Rate’),
yaxis=dict(title=‘True Positive Rate’),
legend=dict(x=0.7, y=0.2))
# Show plot
fig.show()
Y conseguimos:
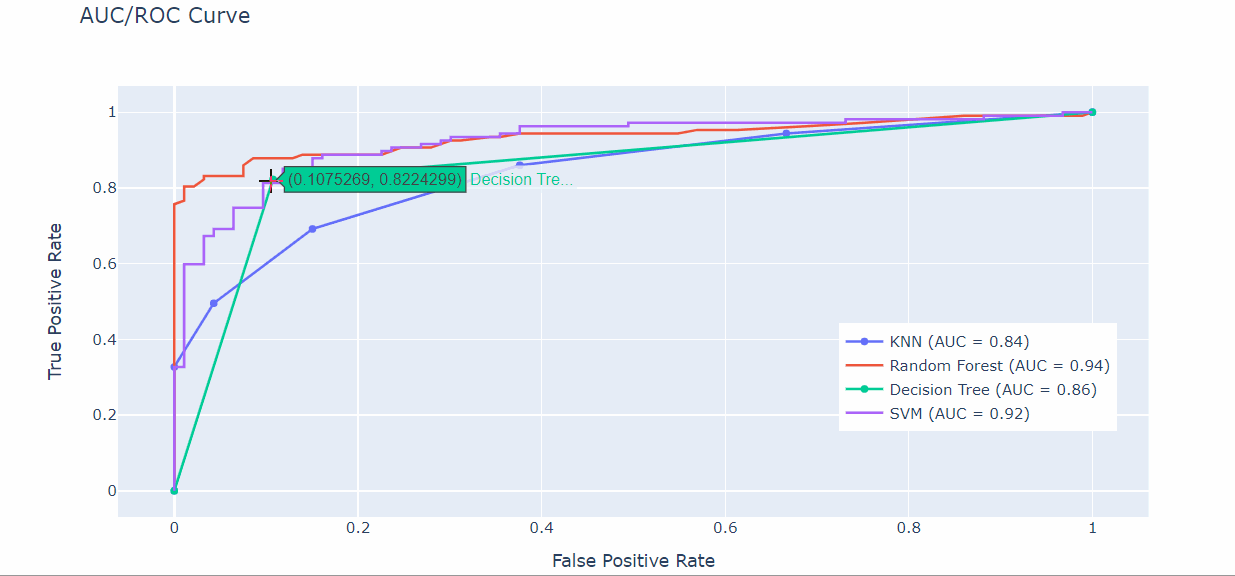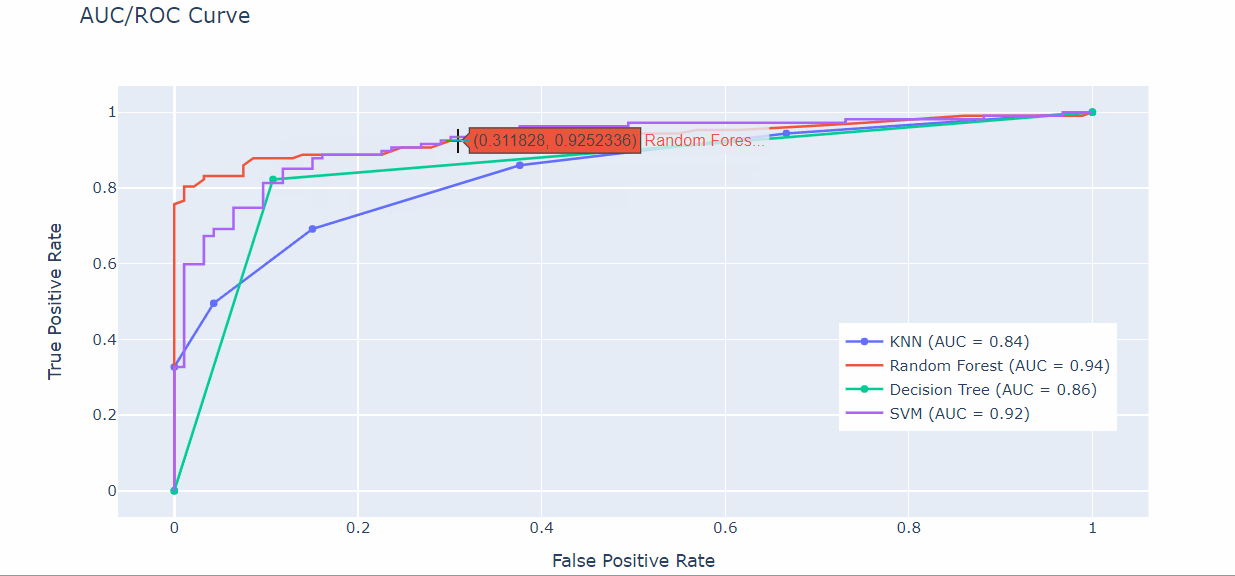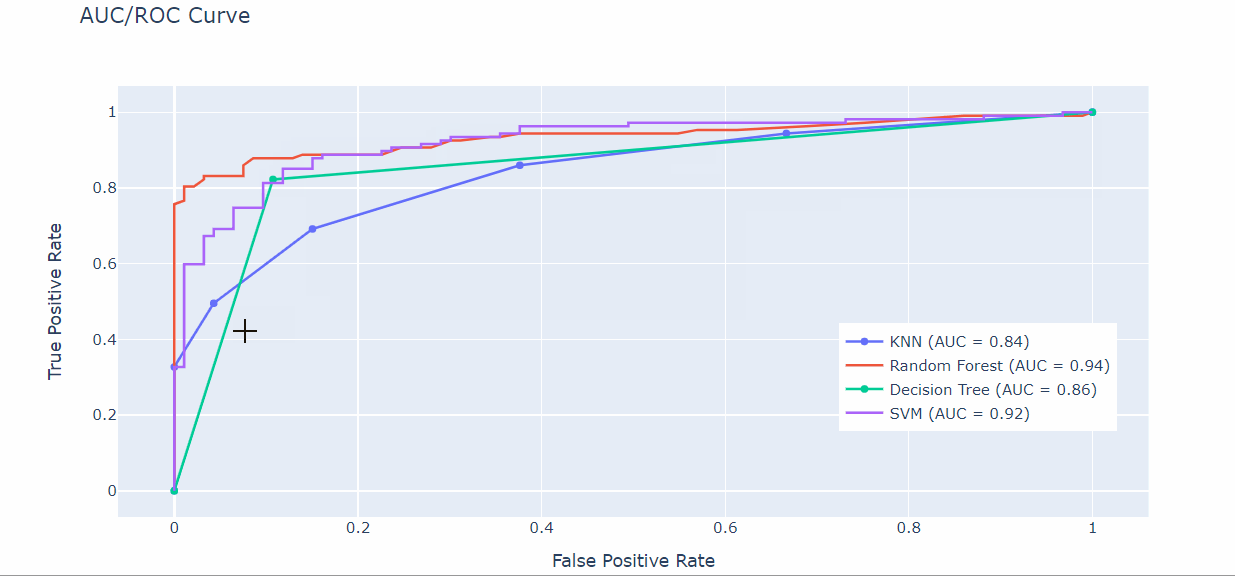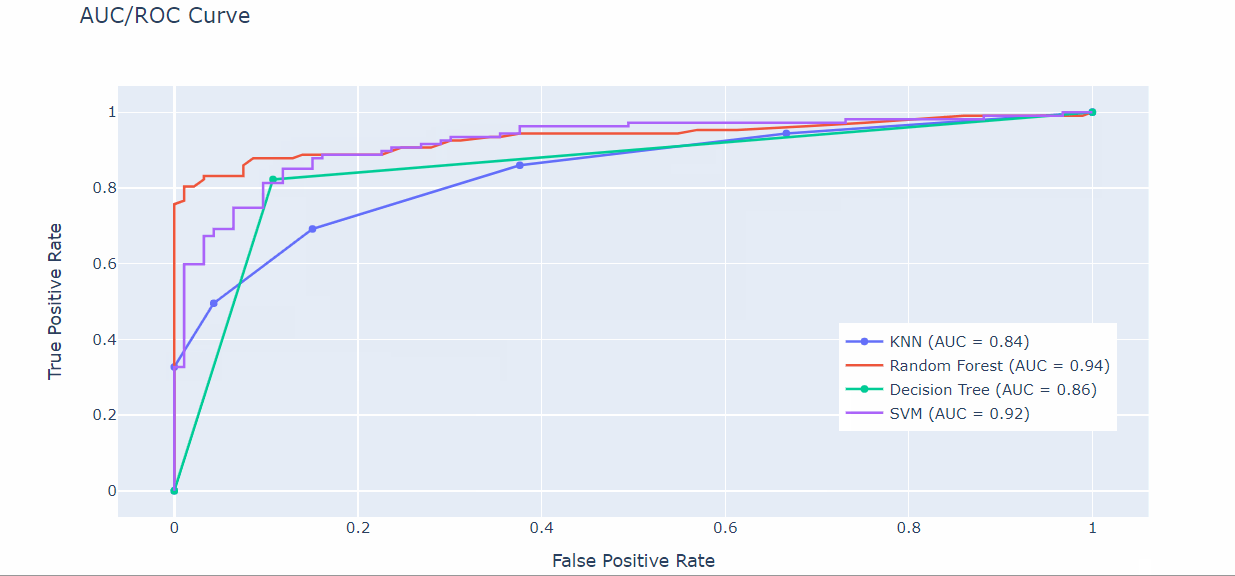
Así, con el método add.trace(go.Scatter) hemos creado gráficos de dispersión para cada modelo ML que hemos utilizado (KNN, SVM, Árbol de decisión y Random Forest).
De esta forma, es fácil visualizar los detalles y los valores de las zonas donde se interceptan las curvas.
Conclusiones
En este artículo, hemos mostrado una rápida introducción a Plotly y hemos visto cómo podemos usarlo para mejores visualizaciones en análisis de datos y Machine Learning.
Como podemos ver, se trata de una librería low-code que, efectivamente, nos ayuda a visualizar mejor nuestros datos, mejorando nuestros resultados.
Original article here
The post Construyendo visualizaciones interactivas de datos con Python: una introducción a Plotly first appeared on Planeta Chatbot.
]]>The post Liberando el potencial de las bibliotecas de Python menos conocidas first appeared on Planeta Chatbot.
]]>Python es uno de los lenguajes de programación más utilizados del mundo y proporciona a los desarrolladores una amplia gama de bibliotecas.
De todos modos, cuando se trata de manipulación de datos y computación científica, generalmente pensamos en bibliotecas como Numpy, Pandas o SciPy.
En este artículo, te presentamos 3 bibliotecas de Python que pueden interesarte.
1. Dask
Presentación de Dask
Dask es una biblioteca flexible de computación paralela que permite la computación distribuida y el paralelismo para el procesamiento de datos a gran escala.
Entonces, ¿por qué deberíamos usar Dask? Como dicen en su página web:
Python se ha convertido en el lenguaje dominante tanto en el análisis de datos como en la programación general. Este crecimiento se ha visto impulsado por bibliotecas computacionales como NumPy, pandas y scikit-learn. Sin embargo, estos paquetes no estaban diseñados para escalar más allá de una sola máquina. Dask se desarrolló para escalar de forma nativa estos paquetes y el ecosistema que los rodea a máquinas multinúcleo y clústeres distribuidos cuando los conjuntos de datos exceden la memoria.
Así, uno de los usos comunes de Dask, como dicen, es:
Dask DataFrame se utiliza en situaciones en las que pandas es comúnmente necesario, por lo general cuando pandas falla debido al tamaño de los datos o la velocidad de cálculo:
- Manipulación de grandes conjuntos de datos, incluso cuando esos conjuntos de datos no caben en la memoria.
- Aceleración de cálculos largos mediante el uso de muchos núcleos.
- Computación distribuida en grandes conjuntos de datos con operaciones estándar de pandas como groupby, join y cálculos de series temporales.
Por lo tanto, Dask es una buena opción cuando tenemos que lidiar con enormes marcos de datos Pandas. Esto se debe a que Dask:
Permite a los usuarios manipular conjuntos de datos de 100GB+ en un portátil o conjuntos de datos de 1TB+ en una estación de trabajo.
Lo cual es un resultado bastante impresionante. Lo que sucede bajo el capó, es que: Los DataFrames de Dask coordinan muchos DataFrames/Series de pandas dispuestos a lo largo del índice. Un Dask DataFrame está particionado por filas, agrupando las filas por el valor del índice para mayor eficiencia. Estos objetos pandas pueden vivir en disco o en otras máquinas.
Por lo tanto, tenemos algo así:
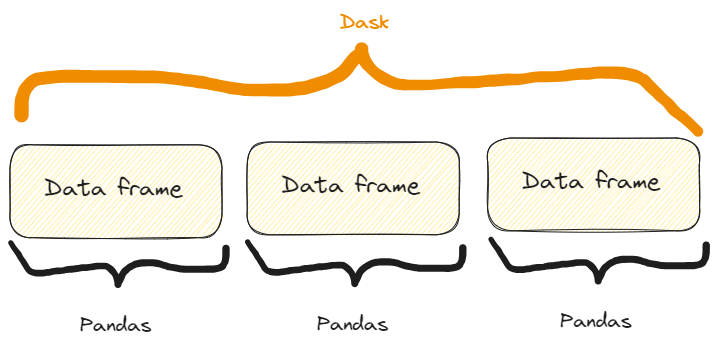
Diferencia entre un marco de datos Dask y un marco de datos Pandas. Imagen del autor, inspirada libremente en una de la web de Dask ya citada.
Algunas características de Dask en acción:
En primer lugar, necesitamos instalar Dask. Podemos hacerlo a través de pip o conda así:
$ pip install dask[complete]
or
$ conda install dask
CARACTERÍSTICA UNO: ABRIR UN ARCHIVO CSV
La primera característica que podemos mostrar de Dask es cómo podemos abrir un CSV. Podemos hacerlo así:
import dask.dataframe as dd
# Load a large CSV file using Dask
df_dask = dd.read_csv('my_very_large_dataset.csv')
# Perform operations on the Dask DataFrame
mean_value_dask = df_dask['column_name'].mean().compute()
Así, como podemos ver en el código, la forma en que usamos Dask es muy similar a Pandas. En particular:
- Usamos el método read_csv() exactamente igual que en Pandas
- Interceptamos una columna exactamente igual que en Pandas. De hecho, si tuviéramos un marco de datos Pandas llamado df interceptaríamos una columna de esta forma: df[‘nombre_columna’].
- Aplicamos el método mean() a la columna interceptada de forma similar a Pandas, pero aquí también necesitamos añadir el método compute().
Además, aunque la metodología de abrir un fichero CSV es la misma que en Pandas, bajo el capó Dask está procesando sin esfuerzo un gran conjunto de datos que excede la capacidad de memoria de una sola máquina.
Esto significa que no podemos ver ninguna diferencia real, excepto el hecho de que un marco de datos grande no se puede abrir en Pandas, pero en Dask podemos.
SEGUNDA CARACTERÍSTICA: AMPLIACIÓN DE LOS FLUJOS DE TRABAJO DE MACHINE LEARNING
También podemos utilizar Dask para crear un conjunto de datos de clasificación con un gran número de muestras. A continuación, podemos dividirlo en los conjuntos de entrenamiento y prueba, ajustar el conjunto de entrenamiento con un modelo ML y calcular las predicciones para el conjunto de prueba.
Podemos hacerlo así:
import dask_ml.datasets as dask_datasets
from dask_ml.linear_model import LogisticRegression
from dask_ml.model_selection import train_test_split
# Load a classification dataset using Dask
X, y = dask_datasets.make_classification(n_samples=100000, chunks=1000)
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y)
# Train a logistic regression model in parallel
model = LogisticRegression()
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test).compute()
Este ejemplo pone de relieve la capacidad de Dask para manejar enormes conjuntos de datos, incluso en el caso de un problema de aprendizaje automático, mediante la distribución de los cálculos a través de múltiples núcleos.
En concreto, podemos crear un «Dask dataset» para un caso de clasificación con el método dask_datasets.make_classification(), y podemos especificar el número de muestras y chunks (incluso, ¡muy enormes!).
Al igual que antes, las predicciones se obtienen con el método compute().
NOTE:
in this case, you may need to install the module dask_ml.
You can do it like so:
$ pip install dask_ml
CARACTERÍSTICA TRES: PROCESAMIENTO EFICAZ DE IMÁGENES
La potencia del procesamiento paralelo que utiliza Dask también puede aplicarse a las imágenes.
En concreto, podríamos abrir varias imágenes, redimensionarlas y guardarlas redimensionadas.
Podemos hacerlo así:
import dask.array as da
import dask_image.imread
from PIL import Image
# Load a collection of images using Dask
images = dask_image.imread.imread('image*.jpg')
# Resize the images in parallel
resized_images = da.stack([da.resize(image, (300, 300)) for image in images])
# Compute the result
result = resized_images.compute()
# Save the resized images
for i, image in enumerate(result):
resized_image = Image.fromarray(image)
resized_image.save(f'resized_image_{i}.jpg')
El proceso es el siguiente:
- Abrimos todas las imágenes «.jpg» de la carpeta actual (o de una carpeta que se pueda especificar) con el método dask_image.imread.imread(«imagen*.jpg»).
- Las redimensionamos todas a 300×300 usando una comprensión de lista en el método da.stack().
- Calculamos el resultado con el método compute(), como hicimos antes.
- Guardamos todas las imágenes redimensionadas con el ciclo for.
2. SymPy
Presentación de Sympy
Si necesitas hacer cálculos matemáticos y computaciones y quieres ceñirte a Python, puedes probar Sympy.
De hecho: ¿por qué usar otras herramientas y software, cuando podemos usar nuestro querido Python?
Según lo que escriben en su sitio web, Sympy es:
una librería Python para matemática simbólica. Su objetivo es convertirse en un completo sistema de álgebra computacional (CAS), manteniendo el código lo más simple posible para que sea comprensible y fácilmente extensible. SymPy está escrito íntegramente en Python.
Pero, ¿por qué utilizar SymPy? Ellos sugieren:
SymPy es…
- Libre: Con licencia BSD, SymPy es libre tanto para hablar como para beber cerveza.
- Basado en Python: SymPy está escrito completamente en Python y utiliza Python como lenguaje.
- Ligero: SymPy sólo depende de mpmath, una biblioteca pura de Python para aritmética arbitraria en coma flotante, lo que facilita su uso.
- Una biblioteca: Más allá de su uso como herramienta interactiva, SymPy puede incrustarse en otras aplicaciones y ampliarse con funciones personalizadas.
Así que, básicamente, ¡tiene todas las características que pueden gustar a los adictos a Python!
Ahora, veamos algunas de sus características.
Algunas características de SymPy en acción
En primer lugar, tenemos que instalarlo:
$ pip install sympy
PAY ATTENTION:
if you write $ pip install simpy you'll install another (completely
different!) library.
So, the second letter is a "y", not an "i".
PRIMERA CARACTERÍSTICA: RESOLVER UNA ECUACIÓN ALGEBRAICA
Si necesitamos resolver una ecuación algebraica, podemos utilizar SymPy de la siguiente manera:
from sympy import symbols, Eq, solve
# Define the symbols
x, y = symbols('x y')
# Define the equation
equation = Eq(x**2 + y**2, 25)
# Solve the equation
solutions = solve(equation, (x, y))
# Print solution
print(solutions)
>>>
[(-sqrt(25 - y**2), y), (sqrt(25 - y**2), y)]
Este es el proceso:
- Definimos los símbolos de la ecuación con el método symbols().
- Escribimos la ecuación algebraica con el método Eq.
- Resolvemos la ecuación con el método solve().
Cuando estaba en la Universidad utilicé diferentes herramientas para resolver este tipo de problemas, y tengo que decir que SymPy, como podemos ver, es muy legible y fácil de usar.
Pero, en efecto: es una biblioteca de Python, así que ¿cómo podría ser diferente?
SEGUNDA CARACTERÍSTICA: CÁLCULO DE DERIVADAS
Calcular derivadas es otra tarea que podemos necesitar matemáticamente, por muchas razones al analizar datos. A menudo, podemos necesitar cálculos por cualquier razón, y SympY realmente simplifica este proceso. De hecho, podemos hacerlo así:
from sympy import symbols, diff
# Define the symbol
x = symbols('x')
# Define the function
f = x**3 + 2*x**2 + 3*x + 4
# Calculate the derivative
derivative = diff(f, x)
# Print derivative
print(derivative)
>>>
3*x**2 + 4*x + 3
Como vemos, el proceso es muy sencillo y autoexplicativo:
- Definimos el símbolo de la función que estamos derivando con symbols().
- Definimos la función.
- Calculamos la derivada con diff() especificando la función y el símbolo del que estamos calculando la derivada (se trata de una derivada absoluta, pero podríamos realizar incluso derivadas parciales en el caso de funciones que tengan variables x e y).
Y si lo probamos, veremos que el resultado llega en cuestión de 2 ó 3 segundos. O sea, que también es bastante rápido.
CARACTERÍSTICA TRES: CÁLCULO DE INTEGRACIONES
Por supuesto, si SymPy puede calcular derivadas, también puede calcular integraciones. Hagámoslo:
from sympy import symbols, integrate, sin
# Define the symbol
x = symbols('x')
# Perform symbolic integration
integral = integrate(sin(x), x)
# Print integral
print(integral)
>>>
-cos(x)
Así que aquí utilizamos el método integrate(), especificando la función a integrar y la variable de integración.
¡¿No podría ser más fácil?!
3. Xarray
Presentación de Xarray
Xarray es una librería de Python que extiende las características y funcionalidades de NumPy, dándonos la posibilidad de trabajar con arrays y conjuntos de datos etiquetados.
Como dicen en su página web, de hecho
Xarray hace que trabajar con arrays multidimensionales etiquetados en Python sea sencillo, eficiente y divertido.
Y también:
Xarray introduce etiquetas en forma de dimensiones, coordenadas y atributos sobre las matrices multidimensionales de NumPy, lo que permite una experiencia de desarrollo más intuitiva, más concisa y menos propensa a errores.
En otras palabras, amplía la funcionalidad de las matrices NumPy añadiendo etiquetas o coordenadas a las dimensiones de la matriz. Estas etiquetas proporcionan metadatos y permiten un análisis y una manipulación más avanzados de los datos multidimensionales.
Por ejemplo, en NumPy, se accede a las matrices utilizando indexación basada en enteros.
En Xarray, en cambio, cada dimensión puede tener asociada una etiqueta, lo que facilita la comprensión y manipulación de los datos basándose en nombres significativos.
Por ejemplo, en lugar de acceder a los datos con arr[0, 1, 2], podemos utilizar arr.sel(x=0, y=1, z=2) en
Xarray, donde x, y, z son etiquetas de dimensión.
Esto hace que el código sea mucho más legible.
Veamos algunas características de Xarray.
Algunas características de Xarray en acción
Como siempre, para instalarlo:
$ pip install xarray
CARACTERÍSTICA UNO: TRABAJAR CON COORDENADAS ETIQUETADAS
Supongamos que queremos crear unos datos relacionados con la temperatura y queremos etiquetarlos con coordenadas como latitud y longitud. Podemos hacerlo así:
import xarray as xr
import numpy as np
# Create temperature data
temperature = np.random.rand(100, 100) * 20 + 10
# Create coordinate arrays for latitude and longitude
latitudes = np.linspace(-90, 90, 100)
longitudes = np.linspace(-180, 180, 100)
# Create an Xarray data array with labeled coordinates
da = xr.DataArray(
temperature,
dims=['latitude', 'longitude'],
coords={'latitude': latitudes, 'longitude': longitudes}
)
# Access data using labeled coordinates
subset = da.sel(latitude=slice(-45, 45), longitude=slice(-90, 0))
Y si los imprimimos obtenemos:
# Print data
print(subset)
>>>
array([[13.45064786, 29.15218061, 14.77363206, ..., 12.00262833,
16.42712411, 15.61353963],
[23.47498117, 20.25554247, 14.44056286, ..., 19.04096482,
15.60398491, 24.69535367],
[25.48971105, 20.64944534, 21.2263141 , ..., 25.80933737,
16.72629302, 29.48307134],
...,
[10.19615833, 17.106716 , 10.79594252, ..., 29.6897709 ,
20.68549602, 29.4015482 ],
[26.54253304, 14.21939699, 11.085207 , ..., 15.56702191,
19.64285595, 18.03809074],
[26.50676351, 15.21217526, 23.63645069, ..., 17.22512125,
13.96942377, 13.93766583]])
Coordinates:
* latitude (latitude) float64 -44.55 -42.73 -40.91 ... 40.91 42.73 44.55
* longitude (longitude) float64 -89.09 -85.45 -81.82 ... -9.091 -5.455 -1.818
Veamos el proceso paso a paso:
- Hemos creado los valores de temperatura como un array NumPy.
- Hemos definido los valores de latitudes y longitueas como arrays NumPy.
- Hemos almacenado todos los datos en un array Xarray con el método DataArray().
- Hemos seleccionado un subconjunto de las latitudes y longitudes con el método sel() que selecciona los valores que queremos para nuestro subconjunto.
Además, el resultado es fácilmente legible, por lo que el etiquetado es realmente útil en muchos casos.
SEGUNDA CARACTERÍSTICA: TRATAMIENTO DE LOS DATOS QUE FALTAN
Supongamos que estamos recogiendo datos relacionados con las temperaturas durante el año. Queremos saber si tenemos algunos valores nulos en nuestro array. Así es como podemos hacerlo:
import xarray as xr
import numpy as np
import pandas as pd
# Create temperature data with missing values
temperature = np.random.rand(365, 50, 50) * 20 + 10
temperature[0:10, :, :] = np.nan # Set the first 10 days as missing values
# Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50)
# Create an Xarray data array with missing values
da = xr.DataArray(
temperature,
dims=['time', 'latitude', 'longitude'],
coords={'time': times, 'latitude': latitudes, 'longitude': longitudes}
)
# Count the number of missing values along the time dimension
missing_count = da.isnull().sum(dim='time')
# Print missing values
print(missing_count)
>>>
array([[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10],
...,
[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0
Y así obtenemos que tenemos 10 valores nulos.
Además, si nos fijamos bien en el código, podemos ver que podemos aplicar métodos de Pandas a un Xarray como isnull.sum(), como en este caso, que cuenta el número total de valores perdidos.
PRIMERA CARACTERÍSTICA: MANEJO Y ANÁLISIS DE DATOS MULTIDIMENSIONALES
La tentación de manejar y analizar datos multidimensionales es alta cuando tenemos la posibilidad de etiquetar nuestras matrices. Así que, ¿por qué no intentarlo?
Por ejemplo, supongamos que seguimos recopilando datos relacionados con las temperaturas en determinadas latitudes y longitudes.
Quizá queramos calcular la media, la máxima y la mediana de las temperaturas. Podemos hacerlo así:
import xarray as xr
import numpy as np
import pandas as pd
# Create synthetic temperature data
temperature = np.random.rand(365, 50, 50) * 20 + 10
# Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50)
# Create an Xarray dataset
ds = xr.Dataset(
{
'temperature': (['time', 'latitude', 'longitude'], temperature),
},
coords={
'time': times,
'latitude': latitudes,
'longitude': longitudes,
}
)
# Perform statistical analysis on the temperature data
mean_temperature = ds['temperature'].mean(dim='time')
max_temperature = ds['temperature'].max(dim='time')
min_temperature = ds['temperature'].min(dim='time')
# Print values
print(f"mean temperature:\n {mean_temperature}\n")
print(f"max temperature:\n {max_temperature}\n")
print(f"min temperature:\n {min_temperature}\n")
>>>
mean temperature:
array([[19.99931701, 20.36395016, 20.04110699, ..., 19.98811842,
20.08895803, 19.86064693],
[19.84016491, 19.87077812, 20.27445405, ..., 19.8071972 ,
19.62665953, 19.58231185],
[19.63911165, 19.62051976, 19.61247548, ..., 19.85043831,
20.13086891, 19.80267099],
...,
[20.18590514, 20.05931149, 20.17133483, ..., 20.52858247,
19.83882433, 20.66808513],
[19.56455575, 19.90091128, 20.32566232, ..., 19.88689221,
19.78811145, 19.91205212],
[19.82268297, 20.14242279, 19.60842148, ..., 19.68290006,
20.00327294, 19.68955107]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0
max temperature:
array([[29.98465531, 29.97609171, 29.96821276, ..., 29.86639343,
29.95069558, 29.98807808],
[29.91802049, 29.92870312, 29.87625447, ..., 29.92519055,
29.9964299 , 29.99792388],
[29.96647016, 29.7934891 , 29.89731136, ..., 29.99174546,
29.97267052, 29.96058079],
...,
[29.91699117, 29.98920555, 29.83798369, ..., 29.90271746,
29.93747041, 29.97244906],
[29.99171911, 29.99051943, 29.92706773, ..., 29.90578739,
29.99433847, 29.94506567],
[29.99438621, 29.98798699, 29.97664488, ..., 29.98669576,
29.91296382, 29.93100249]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0
min temperature:
array([[10.0326431 , 10.07666029, 10.02795524, ..., 10.17215336,
10.00264909, 10.05387097],
[10.00355858, 10.00610942, 10.02567816, ..., 10.29100316,
10.00861792, 10.16955806],
[10.01636216, 10.02856619, 10.00389027, ..., 10.0929342 ,
10.01504103, 10.06219179],
...,
[10.00477003, 10.0303088 , 10.04494723, ..., 10.05720692,
10.122994 , 10.04947012],
[10.00422182, 10.0211205 , 10.00183528, ..., 10.03818058,
10.02632697, 10.06722953],
[10.10994581, 10.12445222, 10.03002468, ..., 10.06937041,
10.04924046, 10.00645499]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0
Y hemos obtenido lo que queríamos, además de una forma claramente legible.
Y de nuevo, como antes, para calcular los valores máximo, mínimo y medio de las temperaturas hemos usado las funciones de Pandas aplicadas a un array.
Conclusiones
En este artículo, hemos mostrado tres librerías para el cálculo y la computación científica
Mientras que SymPy puede ser el sustituto de otras herramientas y software, dándonos la posibilidad de utilizar código Python para realizar cálculos matemáticos, Dask y Xarray extienden las funcionalidades de otras librerías, ayudándonos en situaciones en las que podemos tener dificultades con otras librerías Python más conocidas para el análisis y manipulación de datos.
The post Liberando el potencial de las bibliotecas de Python menos conocidas first appeared on Planeta Chatbot.
]]>The post Introducción a la IA generativa para principiantes first appeared on Planeta Chatbot.
]]>Palabras como «DALL-E», «ChatGPT» e «IA Generativa» han invadido las redes sociales, los medios de comunicación, las charlas con colegas y todo lo relacionado con nuestro mundo en los últimos meses. Literalmente, todo el mundo habla de ello.
Pero, ¿qué es la IA generativa? ¿Por qué es diferente de la IA «normal»?
En este artículo, aclararemos el panorama general de la IA generativa. Así que, si has participado en debates pero no tienes las ideas claras sobre este tema, este artículo es definitivamente para ti.
Se trata de una explicación discursiva para entender lo básico de lo que hay detrás del mundo IA generativa. Así que no te preocupes: aquí no encontrarás ningún código. Sólo ideas y descripciones, que se presentarán de forma breve y concisa. En particular, nos centraremos en los grandes modelos del lenguaje y en los modelos de generación de imágenes.
¿Qué es la IA generativa y en qué se diferencia de la IA tradicional?
La IA generativa es un subcampo de la IA que consiste en crear algoritmos capaces de generar nuevos datos, como imágenes, texto, código y música.
La gran diferencia entre la IA generativa y la «IA tradicional» es que la primera genera nuevos datos basándose en los datos de entrenamiento. Además, funciona con tipos de datos que la «IA tradicional» no puede.
Digámoslo de forma un poco más técnica:
- La «IA tradicional» puede definirse como IA discriminativa. En este caso, de hecho, entrenamos modelos de Machine Learning para que puedan hacer predicciones o clasificaciones sobre datos nuevos y no vistos. Estos modelos de ML sólo pueden trabajar con números y, a veces, con texto (por ejemplo, en el caso del Procesamiento del Lenguaje Natural).
- En la IA generativa, entrenamos un modelo de ML y éste crea un resultado similar a los datos con los que ha sido entrenado. Estos tipos de modelos de ML pueden trabajar con diferentes tipos de datos como números, texto, imágenes y audio.
Visualicemos los procesos:

En la IA tradicional, entrenamos un modelo de ML para que aprenda de los datos. Entonces, lo alimentamos con datos nuevos y no vistos y puede discriminar, haciendo predicciones o clasificaciones.
En el ejemplo presentado, hemos entrenado un modelo ML para reconocer perros a partir de imágenes.
A continuación, alimentamos el modelo ML entrenado con imágenes nuevas y no vistas de perros y será capaz de clasificar si estas nuevas imágenes representan perros o no.
Esta es la tarea típica de un algoritmo de Deep Learning, en el caso de un problema de clasificación.

En el caso de la IA generativa, en cambio, entrenamos un modelo de ML con datos procedentes de diversas fuentes utilizando una gran cantidad de datos. Después, gracias a un prompt (una consulta en lenguaje natural insertada por un usuario), el modelo nos da una salida que es similar a los datos con los que ha sido entrenado.
Siguiendo con el ejemplo, nuestro modelo se ha entrenado con una enorme cantidad de datos (de texto) que, entre otras cosas, explican qué es un perro. Entonces, si un usuario consulta el modelo preguntando qué es un perro, el modelo describirá qué es un perro en lenguaje natural.
Esta es la tarea típica que realizan herramientas como ChatGPT.
Veamos ahora algunos tipos de modelos generativos de IA.
Grandes modelos lingüísticos
Empecemos a sumergirnos en los distintos tipos de subcampos de la IA generativa comenzando por los modelos lingüísticos de gran tamaño (LLM). Un LLM es (según Wikipedia):
un modelo lingüístico informatizado que consiste en una red neuronal artificial con muchos parámetros (de decenas de millones a miles de millones), entrenada con grandes cantidades de texto sin etiquetar mediante aprendizaje autosupervisado o semisupervisado.
Aunque el término gran modelo lingüístico no tiene una definición formal, a menudo se refiere a modelos de deep learning con millones o incluso miles de millones de parámetros, que han sido «pre-entrenados» en un gran corpus.
Así pues, los LLM son modelos de aprendizaje profundo (Deep Learning, DL) (también conocidos como redes neuronales) entrenados con millones de parámetros en una enorme cantidad de texto (por eso los llamamos «grandes») y son útiles para resolver algunos problemas lingüísticos como:
- Clasificación de textos
- Preguntas y respuestas
- Resumen de documentos
- Generación de textos
Así pues, otra diferencia importante entre los modelos ML estándar es que, en este caso, podemos entrenar un algoritmo DL que puede utilizarse para diferentes tareas.
Me explico mejor.
Si necesitamos desarrollar un sistema que pueda reconocer perros en imágenes como las que hemos visto antes, necesitamos entrenar un algoritmo DL para resolver una tarea de clasificación que es: decirnos si las imágenes nuevas, no vistas, representan perros o no. Nada más.
En cambio, entrenar un LLM puede ayudarnos en todas las tareas que hemos descrito anteriormente. Por lo tanto, esto también justifica la cantidad de potencia de cálculo (¡y dinero!) necesaria para entrenar un LLM (¡que requiere petabytes de datos!).
Como ya sabemos, los LLM son consultados por los usuarios gracias a prompts. Ahora tenemos que distinguir entre el diseño de las instrucciones y la ingeniería de las mismas:
- Diseño de prompts. Es el arte de crear un prompt que se adapte específicamente a la tarea que el sistema está realizando. Por ejemplo, si queremos pedirle a nuestro LLM que traduzca un texto del inglés al italiano, tenemos que escribir un prompt específico en inglés pidiéndole al modelo que traduzca el texto que estamos pegando al italiano.
- Prompt engineering. Es el proceso de crear instrucciones para mejorar el rendimiento de nuestro LLM. Esto significa utilizar nuestro conocimiento del dominio para añadir detalles al prompt como palabras clave específicas, contexto específico y ejemplos, y la salida deseada si es necesario.
Por supuesto, a veces utilizamos una mezcla de ambos. Por ejemplo, podemos querer una traducción del inglés al italiano que interese a un ámbito concreto de conocimiento, como la mecánica.
Así, por ejemplo, un prompt puede ser:» Traduzca al italiano lo siguiente:
la viga está sometida a una tensión normal.
Ten en cuenta que estamos en el campo de la mecánica, por lo que ‘tensión normal’ debe estar relacionado con ella.
Porque «normal» y «tensión» pueden ser mal entendidos por el modelo (¡pero incluso por los humanos!).
Tres tipos de LLM
Existen tres tipos de LLM:
- Modelos lingüísticos genéricos. Son capaces de predecir una palabra (o una frase) basándose en el lenguaje de los datos de entrenamiento. Piensa, por ejemplo, en la función de autocompletado de correo electrónico para entender este tipo.
- Instruction Tuned Models. Este tipo de modelos se entrenan para predecir una respuesta a las instrucciones dadas en la entrada. Resumir un texto es un ejemplo típico.
- Modelos de diálogo. Se entrenan para mantener un diálogo con el usuario, utilizando las respuestas posteriores. Un chatbot con IA es un ejemplo típico.
De todos modos, considera que los modelos que se distribuyen realmente tienen características mixtas. O, al menos, pueden realizar acciones típicas de más de uno de estos tipos. Por ejemplo, si pensamos en ChatGPT podemos decir claramente que:
- Puede predecir una respuesta a las instrucciones, dada una entrada. De hecho, por ejemplo, puede resumir textos, dar ideas sobre un determinado argumento que proporcionamos a través de prompts, etc… Por lo tanto, tiene características como un Modelo Sintonizado con las Instrucciones.
- Está entrenado para dialogar con los usuarios. Y esto es muy claro, ya que trabaja con instrucciones consecuentes hasta que estamos satisfechos con su respuesta. Por lo tanto, también tiene características de un modelo de diálogo.
Generación de imágenes
La generación de imágenes existe desde hace bastante tiempo, contrariamente a lo que podría creerse.
De todos modos, en los últimos tiempos ha ganado popularidad, sobre todo con herramientas como «DALL-E» o «difusión estable» que han despejado su uso, haciendo accesible esta tecnología a las masas de todo el mundo.
Podemos decir que la generación de imágenes puede dividirse en cuatro categorías:
- Autocodificadores variacionales (VAE). son «modelos generativos probabilísticos que requieren redes neuronales como única parte de su estructura general». En palabras operativas, codifican imágenes a un tamaño comprimido y las descodifican al tamaño original. Durante este proceso, aprenden la distribución de los datos.
- Modelos Generativos Adversariales (GAN’s). En general, son los más conocidos, al menos como palabra que resuena en el campo de la IA generativa. Un GAN es «una clase de marco de ML en el que dos Redes Neuronales se enfrentan entre sí donde la ganancia de una es la pérdida de la otra». Esto significa que una red neuronal crea la imagen mientras que la otra predice si es real o falsa.
- Modelos autorregresivos. En estadística, un modelo autorregresivo es la representación de un proceso aleatorio. En el contexto de las imágenes generativas, este tipo de modelos generan imágenes tratándolas como una secuencia de píxeles.
- Modelos de difusión. Los modelos de difusión se inspiran en la termodinámica y son sin duda los más prometedores e interesantes en el subcampo de la generación de imágenes.
Este es el proceso que se esconde tras los modelos de difusión:
- Proceso de distribución hacia delante. Tenemos un proceso inicial, iterativo, en el que la estructura de la imagen se «destruye» en una distribución de datos. En palabras sencillas, es como si añadiéramos ruido a la imagen de forma iterativa, hasta que todos los píxeles se convierten en puro ruido y la imagen no es reconocible (por el ojo humano).
- Proceso de difusión inversa. A continuación, hay un proceso de difusión inversa que es el proceso de aprendizaje real: esto restaura la estructura de los datos. Es como si nuestro modelo aprendiera a «eliminar el ruido» de los píxeles para recrear la imagen.
El poder de conectarlo todo
Si has mantenido la atención hasta ahora, una pregunta debería surgir de forma natural en tu mente: «Vale, Federico, está claro. Pero me falta algo: cuando utilizo «DALL-E» inserto un prompt y sale una imagen: no hemos hablado de eso, ¿verdad?«.
No, no lo hemos hecho.
Arriba hemos hecho una breve descripción del modelo más prometedor (y actualmente, el más utilizado) para generar imágenes, pero la parte que falta es el prompt.
Hemos discutido, de hecho, cómo funcionan a alto nivel. Es decir: hemos dado una breve explicación de cómo funciona su proceso de aprendizaje.
Pero la verdadera potencia de estos modelos llega cuando se acoplan con los LLM. Este acoplamiento, de hecho, nos da la posibilidad de combinar el poder de la ingeniería de los prompt para pedir salidas a nuestros modelos.
En otras palabras: hemos combinado la posibilidad de utilizar el lenguaje natural como entrada con modelos capaces de entenderlo y generar imágenes en función de él.
¿No se trata de un superpoder?
Conclusiones
En conclusión, podemos decir que la IA generativa es un subcampo de la IA que genera nuevos datos similares a los datos del tren.
Mientras que, por un lado, los LLM pueden generar texto a partir de los datos de entrenamiento y los modelos de generación de imágenes pueden generar nuevas imágenes a partir de las imágenes de entrenamiento, el verdadero poder de la IA generativa, al menos en el caso de las imágenes, reside en la combinación de LLM y modelos para la generación de imágenes. Esto nos da la posibilidad de crear imágenes según indicaciones como entradas.
NOTA: este artículo se ha inspirado libremente en el curso de IA Generativa impartido por Google, y algunas referencias están tomadas del mismo. Recomiendo realizar este curso, para una mejor comprensión de la IA generativa.
Original article here.
The post Introducción a la IA generativa para principiantes first appeared on Planeta Chatbot.
]]>The post Cómo empezar a programar eficazmente en la era de ChatGPT first appeared on Planeta Chatbot.
]]>Si te gustaría empezar a programar pero tienes miedo de que la IA y ChatGPT te robe el trabajo, entonces este artículo es definitivamente para ti. Especialmente si estás pensando en cambiar de carrera para convertirte en un Ingeniero de Software o un Profesional de Datos, realmente siento lo incómodo que estás ahora mismo.
Empecé a programar hace unos 3 años cuando tenía 30 sin experiencia previa, y esto me ayudó a encontrar mi primer trabajo remoto en IT.
Ahora, hace 3 años ChatGPT no existía y sé que estás atormentado con preguntas como: «¿Qué pasa si invierto meses aprendiendo y practicando a programar y luego no encuentro un trabajo real por culpa de la IA?».
Bueno, déjame decirte una cosa: no te asustes por los recientes despidos en las grandes tecnológicas: no están directamente relacionados con el aumento de la IA. Además, nadie sabe realmente si la IA sustituirá a los desarrolladores dentro de 5 años, así que esta es mi opinión: La IA sustituirá a los desarrolladores que no sepan programar. Por lo tanto, si aprendes a programar, la IA será una herramienta que te ayudará a agilizar tus tareas diarias, no un enemigo que te sustituirá.
Por lo tanto, en este artículo, vamos a ver cómo ChatGPT en realidad puede ser un valor añadido para ti si estás pensando en empezar a programar hoy, independientemente de la edad que tengas y lo que es tu estado actual de la carrera.
Regla número 1: cómo formular correctamente las preguntas a ChatGPT
Lo primero que hay que aprender es cómo hacer correctamente las preguntas adecuadas a ChatGPT.
Cuando empecé a aprender a programar pensaba que los desarrolladores eran unos empollones que empezaban a programar a los 5 años y tenían unos conocimientos enormes de programación, teniendo en mente todo el código que necesitaban.
¿Y sabes qué? No podía estar más equivocado. He aquí una cruda verdad:
- Muchos desarrolladores empezaron a aprender a programar entre los 20 y los 30 años.
- La mayoría de los desarrolladores trabajan buscando cosas en Google y StackOverflow (y hoy en día, hacen preguntas a ChatGPT).
Así que, en primer lugar, si estás empezando a programar ahora mismo no te avergüences de pasar mucho tiempo en Google, StackOverflow o ChatGPT. Es completamente normal. Sólo necesitas saber cómo hacerlo correctamente porque nunca tendrás en mente todo el código que necesitas (tendrás en mente sólo los métodos y funciones que más utilices, por supuesto).
De todos modos, la diferencia entre hoy y los 90 es que en los 90 apenas existía Internet, por lo que los desarrolladores no tenían todo el apoyo que tienen hoy gracias a las comunidades globales, los foros, los sitios web y la IA.
Esto llevó a los desarrolladores a aprender a programar por las malas, no pocas veces pasando días para resolver un problema (encontrar un bug o dar con el trozo de código adecuado).
Hoy en día, tienes una gran oportunidad: tienes un desarrollador senior disponible 24/7 y esto es ChatGPT, pero tienes que tratarlo como tal, no como un oráculo.
Así que aquí tienes algunas pautas sobre cómo deberías consultar correctamente ChatGPT si estás empezando a programar hoy:
- Aprende primero lo básico. Antes de usar ChatGPT, mi consejo es que primero aprendas lo básico por una sencilla razón: ChatGPT a menudo te da código que necesitas refactorizar, por cualquier razón. Esto significa que necesitas tener conocimientos previos de codificación: no puedes simplemente pedirle a ChatGPT que te cree un código para resolver un problema real. El tipo de desarrolladores que serán sustituidos por la IA son propiamente los que hacen preguntas a ChatGPT sin conocimientos previos (o con escasos conocimientos) de codificación. Así que, antes de preguntar, consigue un curso y empieza a practicar.
- Haz preguntas y luego aprende. Cuando somos niños somos muy curiosos y nuestras preguntas nos hacen crecer porque estamos genuinamente interesados en las respuestas. Este es el estado mental que deberíamos tener siempre como profesionales del software: tener una respuesta y simplemente copiarla y pegarla no nos hará aprender a programar. Si el código que obtenemos de ChatGPT funciona deberías, al menos, pedirle que te explique el código que ha utilizado y por qué lo ha utilizado. Como principiante, de hecho, tu papel es aprender para que en el futuro puedas usar menos ChatGPT y ser más independiente: por eso siempre debes pedir explicaciones del código.
- Resuelve problemas reales. Cuando programamos, podemos resolver el mismo problema con diferentes métodos: por eso no tiene sentido pedirle a ChatGPT que genere un código aleatorio. Es absolutamente necesario pedirle algo relacionado con un proyecto que estamos haciendo o un problema que necesitamos resolver.
- No confíes ciegamente en él. Como sistema de IA generativa, ChatGPT es propenso a errores. Aunque hoy en día con los modelos GTP-4 hemos visto muy buenas mejoras, sigue habiendo errores en el código. Además, los errores suelen deberse a que las indicaciones pueden estar incompletas o ser de algún modo engañosas. Por eso, aunque el código funcione, no puedes fiarte ciegamente de las respuestas y necesitas entender a fondo el código que obtienes.
Regla número 2: consulta siempre la documentación

Creé la imagen de arriba para un contenido que escribí en Linkedin hace unos meses (oh, y por cierto: aquí está mi perfil si quieres ponerte en contacto).
Esta es la moraleja de la historia: independientemente de dónde busques la información que necesitas para resolver tu problema de codificación, siempre tienes que leer la documentación. Siempre. Este es el evangelio para nosotros, los desarrolladores y profesionales de datos. Siempre tenemos que leer la documentación.
De hecho, si encontramos un fragmento de código que puede resolver un problema al que nos enfrentamos, si no entendemos el código no seremos capaces de generalizar el código que estamos utilizando. Esto significa que en el futuro no podremos resolver un problema similar porque no hemos aprendido nada: nos hemos limitado a copiar y pegar el código.
Y esto es particularmente cierto con ChatGPT, sobre todo porque a veces inventa bibliotecas que no existen. Sí, has leído bien: a veces ChatGPT inventa bibliotecas.
Hay que decir que, gracias a GPT-4, OpenAI hizo muchas mejoras. Pero en los últimos meses, me ha pasado al menos un par de veces que ChatGPT se ha inventado algunas librerías inexistentes.
¿Y sabes cómo podemos ver si una librería no existe? Hay algunas posibilidades:
- Tú sabes lo que estás haciendo y pidiendo a ChatGPT. Pero esto ocurrirá después de meses de práctica, cuando hayas adquirido algo de experiencia.
- Obtienes el código de ChatGPT, lo lees, intentas entenderlo, le pides a ChatGPT alguna explicación sobre el uso, vas a Internet para leer la documentación y no encuentras ninguna referencia.
- Pruebas el código y obtienes un error, y aprendes la lección por las malas. Pero no te avergüences de ello: me ha pasado incluso a mí.
Recuerda: no hay nada malo en la urgencia por resolver un problema lo antes posible. Incluso puedes probar el código y obtener un error. Bueno, la verdad es que el error puede deberse incluso a una mala indicación, y esto ocurre con mucha frecuencia.
De todas formas, recuerda: si tu trabajo está hecho porque has resuelto el problema real, entonces, por favor: ve a leer la documentación para entenderlo mejor. También puedes descubrir que tu problema se puede resolver con menos código.
Regla número 3: solución de problemas y depuración
ChatGPT es una gran herramienta incluso para solucionar problemas y depurar tu código. Sin embargo, incluso en este caso, debes aprender a usarlo correctamente, si estás empezando tu camino de aprender a codificar.
En primer lugar, si estás utilizando un IDE como VS CODE o PYCHARM para programar, utiliza sus funciones de depuración. Tienen funciones de depuración integradas gracias a las cuales puedes simplemente pulsar un botón, y depuran tu código, mostrándote (eventuales) problemas en tu código.
En esta etapa, pero incluso más tarde (todavía estoy usando este método), la mejor idea es seguir este camino:
- Escribe tu programa.
- Depura tu código en el IDE.
- Lee las eventuales advertencias que recibas del depurador si algo no funciona.
- Pega las advertencias en Google si no sabes cómo resolverlas.
- Pega las advertencias en ChatGPT si Google no resuelve tu problema.
- Pega todo el código en ChatGPT si aún no has resuelto tu problema.
- Ve a leer la documentación si el punto anterior solucionó tu problema.
Nunca me cansaré de repetirlo: siempre necesitamos consultar la documentación cuando Google o ChatGPT resuelven un problema que tenemos con nuestro código.
Así que, por favor: no pegues ciegamente el código en ChatGPT pidiendo que busque problemas en tu código: primero, esfuérzate por encontrarlos por tu cuenta de la forma más difícil, porque sólo así aprenderás cosas. No hay otra forma de aprender cosas, y sé que lo sabes.
Por último, una nota importante: recuerda que ChatGPT trabaja en la nube y, además, puede usar tus indicaciones para entrenar sus algoritmos (con los recientes cambios en el uso de la privacidad de datos deberías poder cambiar la configuración, y elegir no dar consentimiento a OpenAI para que entrene sus algoritmos con tus indicaciones).
Sin embargo, una cosa importante a tener en cuenta es no pegar en el código de ChatGPT para depurar con información sensible: debido a las violaciones de datos y otros problemas de seguridad relacionados, es mejor mantenerse a salvo.
Ejemplos en Python
Ahora, veamos algunos ejemplos de preguntas que deberíamos escribir en ChatGPT para aprender a codificar.
He preguntado a ChatGPT lo siguiente: «¿Cómo podemos imprimir en Python?»
He aquí la respuesta:
En Python, puedes utilizar la función print() para mostrar la salida en la consola o terminal. La función print() toma uno o más argumentos y los imprime como texto.
He aquí algunos ejemplos de uso de la función print():
- Impresión de una cadena simple:
print("Hello, world!")
>>>
Hello, world!
2. Variables de impresión:
name = "Alice"
age = 25
print("My name is", name, "and I am", age, "years old.")
>>>
My name is Alice and I am 25 years old.
3. Impresión de varios argumentos separados por un carácter específico:
print("One", "Two", "Three", sep="-")
>>>
One-Two-Three
4. Impresión de salida formateada utilizando cadenas f (Python 3.6 y superiores):
name = "Bob"
age = 30
print(f"My name is {name} and I am {age} years old.")
>>>
My name is Bob and I am 30 years old.
My name is Bob and I am 30 years old.:paragraph –>
Estos son sólo algunos ejemplos para demostrar el uso de la función print(). Puedes pasar varios tipos de objetos como argumentos a la función print(), y ésta los convertirá automáticamente en una representación de cadena antes de imprimirlos.
Ahora, una pregunta: ¿qué método utilizarías?
Exacto, ¡aquí está el problema! La pregunta que hicimos era demasiado genérica, así que ChatGPT nos dio una respuesta genérica.
Otra lección: las instrucciones deben ser muy específicas. Una podría ser: «Tengo una lista con algunas cadenas en Python: ¿cómo puedo imprimirlas eficientemente?»
Estos son sólo algunos ejemplos para demostrar el uso de la función print(). Puede pasar varios tipos de objetos como argumentos a la función print(), y ésta los convertirá automáticamente en una representación de cadena antes de imprimirlos.
my_list = ['Hello', 'World', 'Python']
# Using join() to concatenate the strings in the list with a space separator
result = ' '.join(my_list)
# Printing the result
print(result)
>>>
Hello World Python
En el ejemplo anterior, el método join() une las cadenas de mi_lista utilizando un espacio ‘ ‘ como separador. A continuación, se utiliza la función print() para mostrar la cadena concatenada.
Al utilizar el método join(), se evita la sobrecarga de múltiples llamadas a la función print(), lo que resulta en una concatenación de cadenas y una impresión más eficientes.
Y aquí estamos: con una pregunta específica obtuvimos una respuesta específica.
Y ahora, ¿sabes lo que tenemos que hacer? Sí, ya sabes: si no sabemos cómo funciona, tenemos que pedir a ChatGPT más explicaciones sobre el método join(). Podemos hacerlo en el mismo chat de esta manera «¿Qué es el método ‘join()‘ y cómo funciona?»
Y aquí está la respuesta:
El método join() es un método de cadena en Python que concatena los elementos de un iterable (como una lista, tupla o conjunto) en una sola cadena usando un separador especificado. Devuelve una nueva cadena que contiene todos los elementos unidos.
La sintaxis para utilizar el método join() es la siguiente:
separator.join(iterable)
Aquí, separator es la cadena que se utilizará para unir los elementos, e iterable es la colección de elementos a unir.
Cuando se llama a join() con una cadena separadora, itera sobre los elementos del iterable y los concatena, insertando la cadena separadora entre cada par de elementos. El separador no se añade ni al principio ni al final de la cadena resultante.
He aquí un ejemplo para ilustrar cómo funciona el método join():
my_list = ['Hello', 'World', 'Python']
# Using join() to concatenate the strings in the list with a space separator
result = ' '.join(my_list)
print(result)
>>>
Hello World Python
En el ejemplo anterior, se llama al método join() sobre la cadena separadora ‘ ‘. Recorre los elementos de mi_lista y los concatena, insertando un espacio entre cada par de elementos. La cadena resultante «Hola Mundo Python» se imprime.
Vale la pena señalar que el método join() es una forma más eficiente de concatenar múltiples cadenas en comparación con el uso del operador + en un bucle. Esto se debe a que join() optimiza internamente el proceso de concatenación, resultando en un mejor rendimiento, especialmente cuando se trata de un gran número de cadenas.
Ahora, en este punto, deberías hacer otras dos cosas:
Buscar «join() Python» en Google y ver algunos otros ejemplos y leer la documentación.
Como podemos ver, ChatGPT nos dice que este método es más eficiente que utilizar el operador + con un bucle para resolver este problema. Deberías continuar el chat y pedir un ejemplo (entonces, lee la documentación que puede venir con los siguientes ejemplos).
Conclusiones
Espero que encuentres útil este artículo sobre cómo empezar tu viaje de programación con la ayuda de ChatGPT.
Recuerda: no des nada por sentado. Úsalo para aprender, no como un oráculo. Y después de resolver tu problema, escribe un prompt específico, lee la documentación, aprende el código y, si es posible, haz prácticas con el código que obtengas como respuesta.
name = "Bob"
age = 30
print(f"My name is {name} and I am {age} years old.")
>>>
My name is Bob and I am 30 years old.
My name is Bob and I am 30 years old.:paragraph –>
Estos son sólo algunos ejemplos para demostrar el uso de la función print(). Puedes pasar varios tipos de objetos como argumentos a la función print(), y ésta los convertirá automáticamente en una representación de cadena antes de imprimirlos.
Ahora, una pregunta: ¿qué método utilizarías?
Exacto, ¡aquí está el problema! La pregunta que hicimos era demasiado genérica, así que ChatGPT nos dio una respuesta genérica.
Otra lección: las instrucciones deben ser muy específicas. Una podría ser: «Tengo una lista con algunas cadenas en Python: ¿cómo puedo imprimirlas eficientemente?»
Estos son sólo algunos ejemplos para demostrar el uso de la función print(). Puede pasar varios tipos de objetos como argumentos a la función print(), y ésta los convertirá automáticamente en una representación de cadena antes de imprimirlos.
my_list = ['Hello', 'World', 'Python']
# Using join() to concatenate the strings in the list with a space separator
result = ' '.join(my_list)
# Printing the result
print(result)
>>>
Hello World Python
En el ejemplo anterior, el método join() une las cadenas de mi_lista utilizando un espacio ‘ ‘ como separador. A continuación, se utiliza la función print() para mostrar la cadena concatenada.
Al utilizar el método join(), se evita la sobrecarga de múltiples llamadas a la función print(), lo que resulta en una concatenación de cadenas y una impresión más eficientes.
Y aquí estamos: con una pregunta específica obtuvimos una respuesta específica.
Y ahora, ¿sabes lo que tenemos que hacer? Sí, ya sabes: si no sabemos cómo funciona, tenemos que pedir a ChatGPT más explicaciones sobre el método join(). Podemos hacerlo en el mismo chat de esta manera «¿Qué es el método ‘join()‘ y cómo funciona?»
Y aquí está la respuesta:
El método join() es un método de cadena en Python que concatena los elementos de un iterable (como una lista, tupla o conjunto) en una sola cadena usando un separador especificado. Devuelve una nueva cadena que contiene todos los elementos unidos.
La sintaxis para utilizar el método join() es la siguiente:
separator.join(iterable)
Aquí, separator es la cadena que se utilizará para unir los elementos, e iterable es la colección de elementos a unir.
Cuando se llama a join() con una cadena separadora, itera sobre los elementos del iterable y los concatena, insertando la cadena separadora entre cada par de elementos. El separador no se añade ni al principio ni al final de la cadena resultante.
He aquí un ejemplo para ilustrar cómo funciona el método join():
my_list = ['Hello', 'World', 'Python']
# Using join() to concatenate the strings in the list with a space separator
result = ' '.join(my_list)
print(result)
>>>
Hello World Python
En el ejemplo anterior, se llama al método join() sobre la cadena separadora ‘ ‘. Recorre los elementos de mi_lista y los concatena, insertando un espacio entre cada par de elementos. La cadena resultante «Hola Mundo Python» se imprime.
Vale la pena señalar que el método join() es una forma más eficiente de concatenar múltiples cadenas en comparación con el uso del operador + en un bucle. Esto se debe a que join() optimiza internamente el proceso de concatenación, resultando en un mejor rendimiento, especialmente cuando se trata de un gran número de cadenas.
Ahora, en este punto, deberías hacer otras dos cosas:
Buscar «join() Python» en Google y ver algunos otros ejemplos y leer la documentación.
Como podemos ver, ChatGPT nos dice que este método es más eficiente que utilizar el operador + con un bucle para resolver este problema. Deberías continuar el chat y pedir un ejemplo (entonces, lee la documentación que puede venir con los siguientes ejemplos).
Conclusiones
Espero que encuentres útil este artículo sobre cómo empezar tu viaje de programación con la ayuda de ChatGPT.
Recuerda: no des nada por sentado. Úsalo para aprender, no como un oráculo. Y después de resolver tu problema, escribe un prompt específico, lee la documentación, aprende el código y, si es posible, haz prácticas con el código que obtengas como respuesta.
The post Cómo empezar a programar eficazmente en la era de ChatGPT first appeared on Planeta Chatbot.
]]>