

Tabla de contenidos
Introducción
AWS Sagemaker es la suite de Machine Learning de AWS. Con la llegada de la IA, AWS ha añadido inteligentemente capacidades LLM a Sagemaker.
Sagemaker admite una amplia gama de LLM, incluidos Dolly, Falcon, Llama2 y Mistral-7B. Sin embargo, aún no admite Claude, al que se debe acceder a través de AWS Bedrock.
Para los profesionales de Analytics, averiguar cómo acceder a LLM y otros modelos de Machine Learning desde almacenes de datos como Snowflake y conectar trabajos de extremo a extremo con marcos de modelado de datos como dbt es imprescindible para activar la IA generativa en la capa de Analytics. En este artículo, te mostraremos cómo.
Una canalización de datos básica
Una canalización de datos básica para el ajuste fino de LLM implicaría mover datos a Snowflake o S3, transformarlos utilizando dbt o Coalesce y ejecutar pruebas de calidad de datos. Esto se representa a continuación:
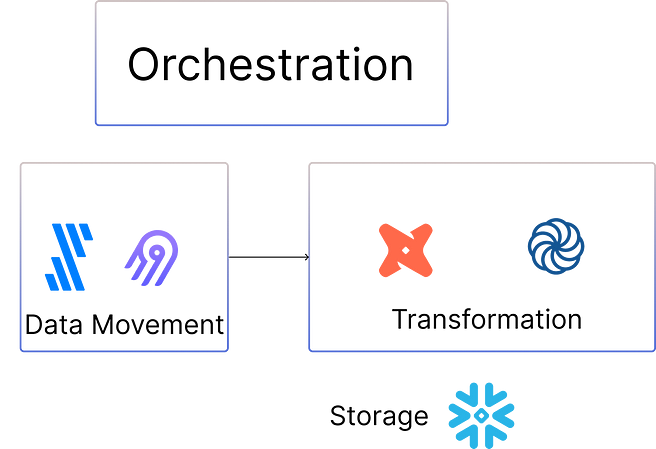
Estos conjuntos de datos limpios se pueden utilizar para ajustar los LLM.
Utilizar Snowflake como fuente de datos para entrenar modelos ML con Amazon SageMaker
Aquí me baso en gran medida en el blog de arquitectura de soluciones de AWS. En este ejemplo, utilizaremos un modelo ML normal como ejemplo y podremos ver cómo se compara con un trabajo de ajuste fino de LLM.
La arquitectura general se muestra a continuación:
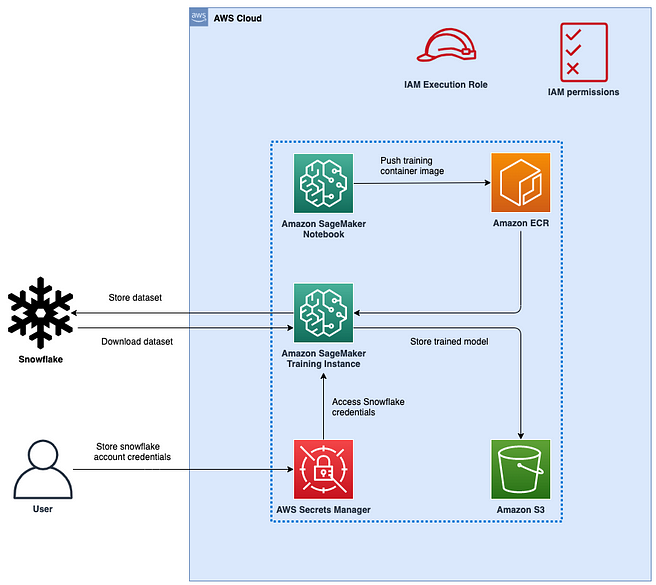
Paso 1: configurar el AWS SageMaker Notebook
El SageMaker Notebook es un repositorio python controlado por git que es el código que tiene tanto la lógica de obtención de datos como la de entrenamiento. A continuación se muestra un ejemplo del código a utilizar:
import pandas as pd import snowflake.connector def data_pull(ctx: snowflake.connector.SnowflakeConnection, table: str, hosts: int) -> pd.DataFrame: # Query Snowflake table for number of table records sql_cnt = f"select count(*) from {table};" df_cnt = pd.read_sql(sql_cnt, ctx) # Retrieve the total number of table records from dataframe for index, row in df_cnt.iterrows(): num_of_records = row.astype(int) list_num_of_rec = num_of_records.tolist() tot_num_records = list_num_of_rec[0] record_percent = str(round(100/hosts)) print(f"going to download a random {record_percent}% sample of the data") # Query Snowflake HOUSING table sql = f"select * from {table} sample ({record_percent});" print(f"sql={sql}") # Get the dataset into Pandas df = pd.read_sql(sql, ctx) print(f"read data into a dataframe of shape {df.shape}") # Prepare the data for ML df.dropna(inplace=True) print(f"final shape of dataframe to be used for training {df.shape}") return df Aquí definimos un método data_pull que se conecta a Snowflake y obtiene los datos como un marco de datos. Se trata de una muestra aleatoria de los datos, ya que es lo que debe aprovecharse para el ajuste fino o la formación de modelos en general.
Paso 2: configuración de credenciales y preparación de datos
Hay algunos pasos adicionales en el código que se puede encontrar en el repositorio de código Github de AWS Sagemaker. Estos incluirían:
- Obtención de los secretos de Snowflake desde AWS Secrets Manager
- Definición de los pasos de preparación de datos después de que los datos se hayan obtenido de Snowflake
- Determinar cosas como Hyperparameters
Paso 3: configurar el paso AWS SageMaker Fit
El paso final, que es de nuestro interés, es el comando donde el cuaderno entrena el modelo:
import boto3 import sagemaker from sagemaker import image_uris from sagemaker import get_execution_role from sagemaker.inputs import TrainingInput from sagemaker.xgboost.estimator import XGBoost role = get_execution_role() sm_session = sagemaker.Session() bucket = None #optionally specify your bucket here, eg: 'mybucket-us-east-1'; Otherwise, SageMaker will use #the default acct bucket to upload model artifacts if bucket is None and sm_session is not None: bucket = sm_session.default_bucket() print(f"bucket={bucket}, role={role}") prefix = "sagemaker/sagemaker-snowflake-example" output_path = "s3://{}/{}/{}/output".format(bucket, prefix, "housing-dist-xgb") custom_img_name = "xgboost-ddp-training-custom" custom_img_tag = "latest" account_id = boto3.client('sts').get_caller_identity().get('Account') # collect default subnet IDs to deploy Sagemaker training job into ec2_session = boto3.Session(region_name=region) ec2_resource = ec2_session.resource("ec2") subnet_ids = [] for vpc in ec2_resource.vpcs.all(): # here you can choose which subnet based on the id if vpc.is_default == True: for subnet in vpc.subnets.all(): if subnet.default_for_az == True: subnet_ids.append(subnet.id) # Retrieve XGBoost custom container from ECR registry path xgb_image_uri = image_uris.retrieve('xgboost', region, version='1.5-1') print(f"\nusing XGBoost image: {xgb_image_uri}") # Create Sagemaker Estimator xgb_script_mode_estimator = sagemaker.estimator.Estimator( image_uri = xgb_image_uri, role=role, instance_count=instance_count, instance_type=instance_type, output_path="s3://{}/{}/output".format(bucket, prefix), sagemaker_session=sm_session, entry_point="train.py", source_dir="./src", hyperparameters=hyperparams, environment=env, subnets = subnet_ids, ) # Estimator fitting xgb_script_mode_estimator.fit() Esta es la parte jugosa de Sagemaker – aprovechando un modelo para el entrenamiento (en este caso XGBoost) que está en una imagen de contenedor y pasando esto como un parámetro al estimador sagemaker, simplemente necesitas proporcionar los parámetros relevantes (para el entrenamiento del modelo y la infraestructura) y llamar al método «fit()» para producir un modelo.
El resultado es que el modelo entrenado estará disponible en el bucket de S3 elegido.
Cómo ejecutar un trabajo de AWS Sagemaker de forma programada
Un caso de uso común una vez que los modelos están funcionando bien es ejecutar trabajos de entrenamiento en un horario.
Los modelos decaen: si llegan nuevos datos en el transcurso de la semana que significan que un modelo de hace una semana ya no es un buen predictor, será necesario entrenar e implementar un nuevo modelo para garantizar que los modelos en producción no decaigan también, lo que llevaría a resultados empresariales subóptimos.
Afortunadamente, al anidar todo el código anterior en un único archivo python, esto es esencialmente un trabajo de entrenamiento de Sagemaker, que puede ser llamado en cualquier momento usando este endpoint.
Esto se puede hacer en Python, lo que naturalmente significa que debe estar utilizando una herramienta de orquestación basada en Python como Airflow, o un servicio gestionado con una integración Sagemaker como Orchestra.
A continuación se muestra una ilustración de la nueva canalización de datos que conecta AWS Sagemaker con la canalización de datos existente:
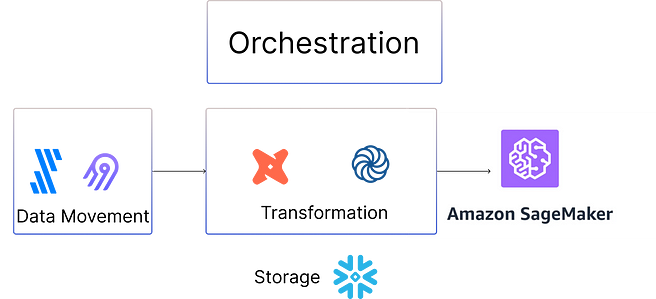
¿Qué ocurre con los LLM?
Los LLMs no están disponibles bajo el endpoint antes mencionado, sin embargo un trabajo de ajuste fino sigue la misma estructura arquitectónica.
En lugar de llamar al trabajo SageMaker Training, usted llamaría al endpoint CreateAutoMLJob.
Conclusión
En este artículo, hemos cubierto cómo conectar Amazon Sagemaker a Snowflake que es un almacén de datos popular. Con la IA Generativa prometiendo democratizar los LLM para todas las organizaciones, la pregunta ya no es si, cuándo, sino cómo.
Un enfoque consiste en utilizar los datos que poseen los equipos de análisis como base para afinar los LLM. Esto sería muy útil para casos de uso como el análisis de correo electrónico, la documentación interna o el escaneo de código.
Demostramos cómo estos datos pueden importarse desde Snowflake directamente a un contenedor en AWS y utilizarse para entrenar un modelo de aprendizaje automático o ajustar un LLM. Esto puede ocurrir periódicamente mediante el acceso a AWS Sagemaker a través de la API, que sería gestionado por una herramienta de orquestación.
Esto supone una gran oportunidad para los analistas e ingenieros de datos. En lugar de limitarse a proporcionar datos como un producto, estos equipos tienen ahora todo lo que necesitan para implementar modelos de ML y LLM. Siempre que las organizaciones estén preparadas para ello, es un momento apasionante para trabajar en el sector de los datos🚀.
Sobre mi
Soy Hugo Lu – Empecé mi carrera trabajando en fusiones y adquisiciones en Londres antes de pasar a JUUL y caer en la ingeniería de datos. Tras un breve paso por el mundo de las finanzas, dirigí la función de datos en Codat, una fintech con sede en Londres. Ahora soy CEO en Orchestra, que es una herramienta de canalización de liberación de datos que ayuda a los equipos de datos a liberar datos en producción de forma fiable y eficiente 🚀.
Consulta también mi Substack y mi blog interno ⭐️
¿Quieres ver cómo Orchestra está cambiando el juego mediante la entrega de ahorro de costes y visibilidad sin precedentes? Prueba ahora nuestra capa gratuita.