The post Agentic RAG With Llama-index | Capacidad de razonamiento multipaso sobre múltiples documentos #04 first appeared on Planeta Chatbot.
]]>En esta continuación de nuestra serie Agentic RAG, nos sumergiremos en el uso de las capacidades de razonamiento multipaso que exploramos anteriormente, pero esta vez a través de una colección diversa de documentos.
Ésta es la parte emocionante: Imagina un agente inteligente capaz de examinar un tesoro de información. Tú formulas una pregunta y este agente te dirige sin problemas al documento más relevante para obtener la respuesta. Agentic RAG lo hace realidad.
Desvelaremos los secretos de este enfoque. Veremos cómo crear una red de «information vaults» específicas para cada documento y cómo capacitar a un agente para navegar por ellas. Por último, seremos testigos de cómo este potente sistema aprovecha los procedimientos tradicionales de RAG para desenterrar las respuestas que busca, independientemente del documento que contenga la clave.
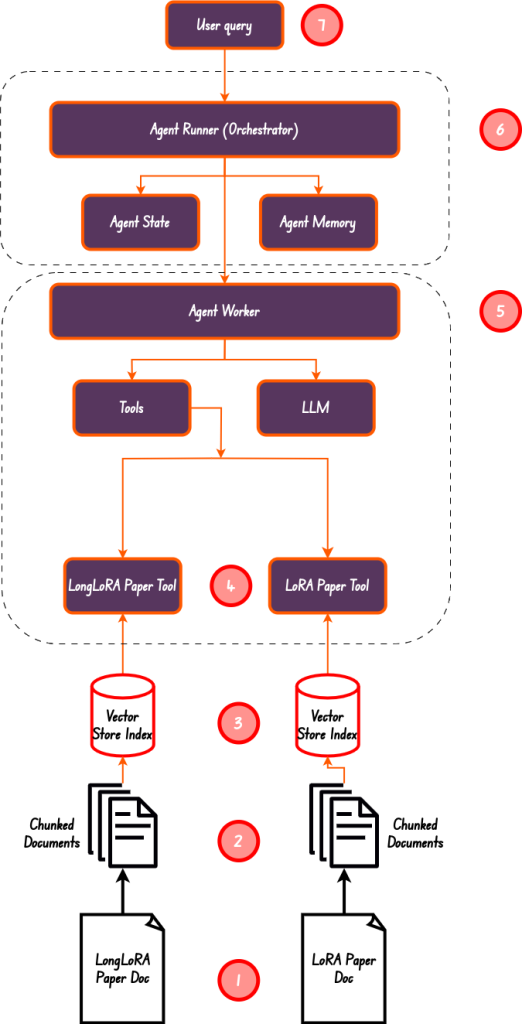
Comencemos con la implementación de una canalización RAG de Agentic para chatear con múltiples documentos.
Configurar el entorno
El primer paso que daremos es configurar nuestro entorno de desarrollo y prepararlo para codificar. Usaremos el mismo entorno que configuramos en el primer artículo. Simplemente crearé un nuevo archivo ipynb para esta lección en particular.
Nuevo archivo de descarga
También vamos a utilizar un nuevo archivo que se puede descargar desde aquí, este archivo en mi caso se llama longlora_efficient_fine_tuning.pdf
Utils.py actualizado
También tendremos que actualizar el archivo utils.py para alojar una nueva función: create_docs_tool . Esta nueva función nos permitirá crear motores de consulta para un resumen y motores de consulta vectoriales.
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SummaryIndex, VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
from typing import Tuple
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the the Lora paper."
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
async def create_doc_tools(
document_fp: str,
doc_name: str,
verbose: bool = True,
) -> Tuple[QueryEngineTool, QueryEngineTool]:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_summary_query_engine_tool",
query_engine=summary_query_engine,
description=(
f"Useful for summarization questions related to the {doc_name}."
),
)
vector_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_vector_query_engine_tool",
query_engine=vector_query_engine,
description=(
f"Useful for retrieving specific context from the the {doc_name}."
),
)
return vector_tool, summary_tool
Creación de vectores y la herramienta de resumen
Vamos a utilizar la función que acabamos de crear para generar vectores y herramientas de resumen para cada uno de los documentos que hemos configurado.
import dotenv %load_ext dotenv %dotenv
import nest_asyncio nest_asyncio.apply()
papers = [
"./datasets/lora_paper.pdf",
"./datasets/longlora_efficient_fine_tuning.pdf"
]
from utils import create_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
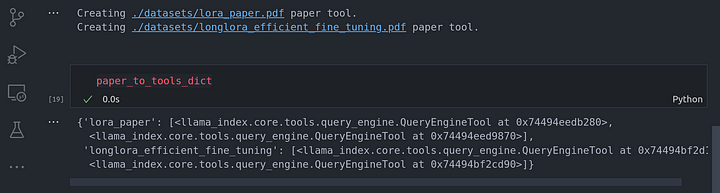
for paper in papers:
print(f"Creating {paper} paper tool.")
path = Path(paper)
vector_tool, summary_tool = await create_doc_tools(doc_name=path.stem, document_fp=path)
paper_to_tools_dict[path.stem] = [vector_tool, summary_tool]
paper_to_tools_dict
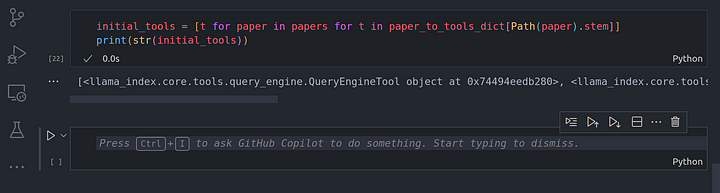
initial_tools = [t for paper in papers for t in paper_to_tools_dict[Path(paper).stem]]
print(str(initial_tools))
len(initial_tools)

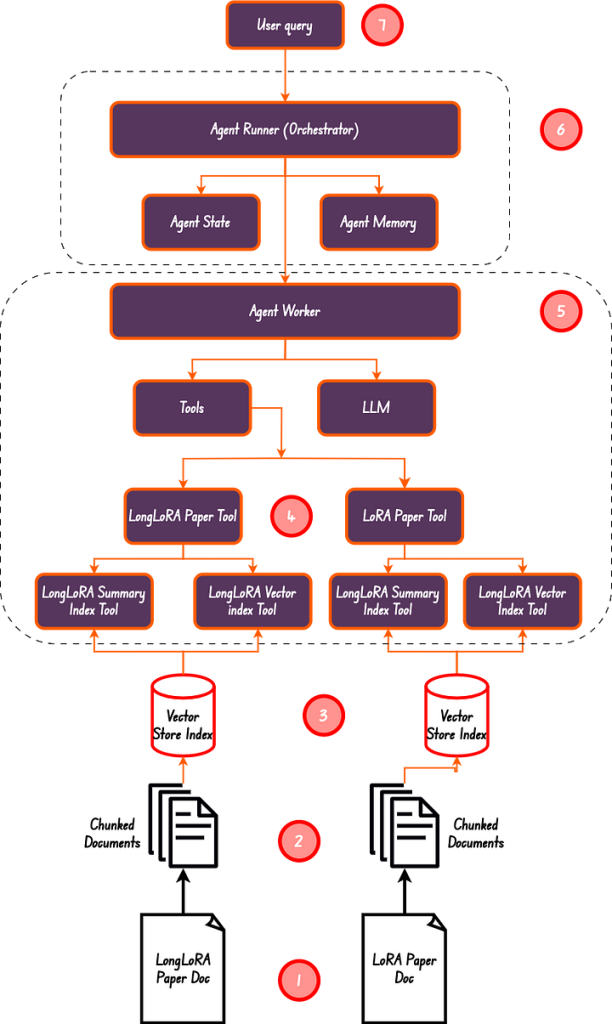
En el diagrama anterior, hemos realizado del paso 1 al paso 5. Hemos creado un resumen y un índice vectorial, asegurándonos de que tenemos 4 herramientas en total, que es también la longitud de la lista de herramientas.
Creando el Agente Trabajador
El trabajador agente es el Orquestador responsable de asignar tareas al trabajador agente. Este es el paso número 6 en el diagrama anterior.
from llama_index.llms.openai import OpenAI llm = OpenAI(model="gpt-3.5-turbo")
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
initial_tools,
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Explain to me what is Lora and why it's being used."
"Explain to me what is LongLoRA and why it's being used."
"Compare and contract LongLoRA and Lora."
)
print(str(response))
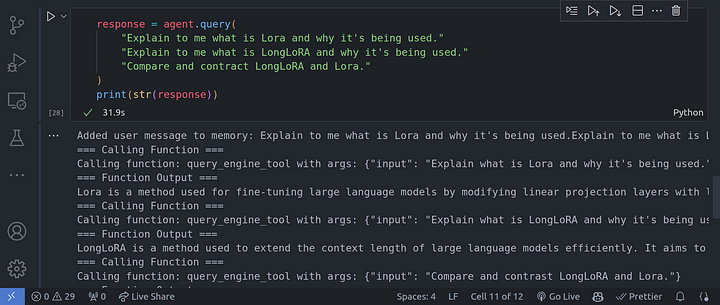
Canalización RAG Agentic Multi-Documento más avanzada
Hasta ahora hemos podido utilizar dos documentos y todo funciona correctamente. Esto lleva a un problema con más documentos que se añaden. Imagina que tuviéramos 20 documentos que serían 40 herramientas diferentes, eso es un poco salvaje:
- Desbordamiento de la ventana de contexto: Al añadir más documentos a la ventana de contexto se añaden más herramientas, lo que puede provocar un desbordamiento de la ventana de contexto. La forma más sencilla de solucionar este problema es añadir una especie de RAG a la sección de herramientas, de forma que primero realicemos algún tipo de recuperación de las herramientas para ver qué herramienta(s) es(son) la(s) más adecuada(s) para la tarea en cuestión y, a continuación, alimentar el LLM sólo con los resultados de esa herramienta. No queremos pasar demasiadas herramientas a la ventana de contexto, es mejor recuperar primero las herramientas más relevantes y luego pasarlas al LLM.
- Aumento de los costes: Meter muchas herramientas en la ventana de contexto significa más uso de tokens por tu parte. No sé hasta dónde llega tu bolsillo, pero es mejor que me envíes ese dinero a mí.
- LLM puede confundirse: La investigación ha demostrado que en la mayoría de los casos, los LLM recuerdan principalmente las cosas al principio de la ventana de contexto y las del final, el concurso en el medio puede ser olvidado por el LLM. Esto significa que a pesar de las grandes ventanas de contexto que los LLMs tienen hoy en día como Gemini con su 1 millón de tokens, todavía puede sufrir de esto.
La solución a esto es realizar una recuperación de las herramientas para obtener las más relevantes y pasar estas herramientas relevantes al bucle de razonamiento del agente. Al menos esto es lo que Llama-index ha hecho en segundo plano. Proporcionan una recuperación de herramientas que ayuda en esta tarea.
Implementación de RAG multidocumento con recuperación de herramientas
Para implementar esto, te aconsejo que descargues más documentos. En mi caso, sólo utilizaré los documentos existentes con los que hemos estado trabajando hasta ahora. Si lo deseas, puedes utilizar este código para descargar más documentos.
urls = [
"https://arxiv.org/pdf/2106.09685"
]
papers = [
"lora_paper.pdf",
]
# poetry add wget
import wget
for url, paper in zip(urls, papers):
!wget "{url}" -O "{paper}"
Asegúrate de ejecutar el comando para instalar wget
$ poetry add wget
Pero en aras de la simplicidad y para ahorrar tiempo a todo el mundo, me ceñiré a los documentos que ya hemos estado utilizando:
papers = [
"./datasets/lora_paper.pdf",
"./datasets/longlora_efficient_fine_tuning.pdf"
]
from utils import create_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Creating {paper} paper tool.")
path = Path(paper)
vector_tool, summary_tool = await create_doc_tools(doc_name=path.stem, document_fp=path)
paper_to_tools_dict[path.stem] = [vector_tool, summary_tool]
tools_list = [t for paper in papers for t in paper_to_tools_dict[Path(paper).stem]]
print(str(tools_list))
Crea el ObjectIndex que utilizaremos para recuperar las herramientas más adecuadas:
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
tools_list,
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_tools = obj_retriever.retrieve(
"Write me a summary of the LoRA paper."
"Write me a summary of the LongLoRA paper."
"Compare and contract LongLoRA and Lora."
)
print(str(retrieved_tools))
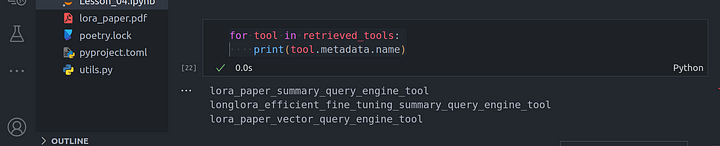
From these set of questions, we can view the tools that have been selected through retrieval:
for tool in retrieved_tools:
print(tool.metadata.name)
Creación del agente
Necesitaremos crear el agente runner y el agente worker:
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt=""" \
You are an AI agent programmed to respond to questions based on a
specified collection of documents. Always utilize the tools available
to generate answers, ensuring that responses are based directly on the
provided materials rather than on any pre-existing knowledge. All your responses should be formatted in markdown text
""",
verbose=True
)
agent = AgentRunner(agent_worker)
We can then go ahead and call the agent:
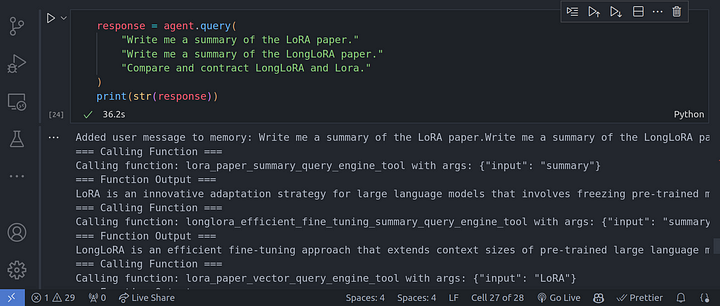
response = agent.query(
"Write me a summary of the LoRA paper."
"Write me a summary of the LongLoRA paper."
"Compare and contract LongLoRA and Lora."
)
print(str(response))
Conclusión
Enhorabuena por haber llegado hasta aquí. En este artículo hemos visto cómo trabajar con un bucle de razonamiento multipaso sobre múltiples documentos en un sistema RAG agéntico. No sólo hemos visto la implementación de alto nivel, sino también el funcionamiento de bajo nivel del bucle de razonamiento multipaso.
Esperamos que este artículo te proporcione una clara comprensión de la capacidad de razonamiento multipaso sobre múltiples documentos.
Otras plataformas en las que puedes ponerte en contacto conmigo:
The post Agentic RAG With Llama-index | Capacidad de razonamiento multipaso sobre múltiples documentos #04 first appeared on Planeta Chatbot.
]]>The post RAG Agentic Con Llama-index | Capacidad de Razonamiento Multipaso #03 first appeared on Planeta Chatbot.
]]>En este artículo, exploraremos cómo implementar un bucle de razonamiento multipaso en nuestra arquitectura Agentic RAG. Prepárate para una emocionante inmersión profunda en el poder de los agentes y su capacidad para manejar intrincadas tareas de múltiples pasos con precisión y eficiencia. Puedes consultar los anteriores también en nuestra web, Planeta Chatbot:
- Agentic RAG con Llama-index | Llamada a función #02
- Agentic RAG con Llama-index | Motor de consulta del enrutador #01
Qué son los agentes
Hasta ahora hemos estado trabajando con Llama-index.
Los data agents son trabajadores del conocimiento potenciados por LLM en LlamaIndex que pueden realizar de forma inteligente diversas tareas sobre sus datos, tanto en función de «lectura» como de «escritura». Son capaces de lo siguiente:
- Realizar búsquedas y recuperaciones automatizadas sobre diferentes tipos de datos: no estructurados, semiestructurados y estructurados.
- Llamar a cualquier API de servicio externo de forma estructurada, y procesar la respuesta + almacenarla para más tarde.
En ese sentido, los agentes van un paso más allá de nuestros motores de consulta, ya que no sólo pueden «leer» de una fuente estática de datos, sino que pueden ingerir y modificar dinámicamente datos de una variedad de herramientas diferentes.
Construir un agente de datos requiere los siguientes componentes básicos:
- Un bucle de razonamiento
- Abstracciones de herramientas
Un data agent se inicializa con un conjunto de APIs, o Herramientas, con las que interactuar; el agente puede llamar a estas APIs para devolver información o modificar el estado. Dada una tarea de entrada, el data agent utiliza un bucle de razonamiento para decidir qué herramientas utilizar, en qué secuencia, y los parámetros para llamar a cada herramienta.
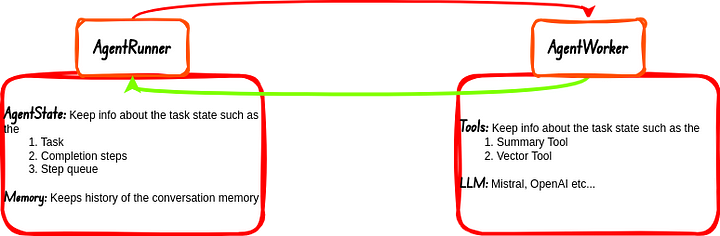
Por defecto los agentes en Llama-index se componen de dos cosas principales:
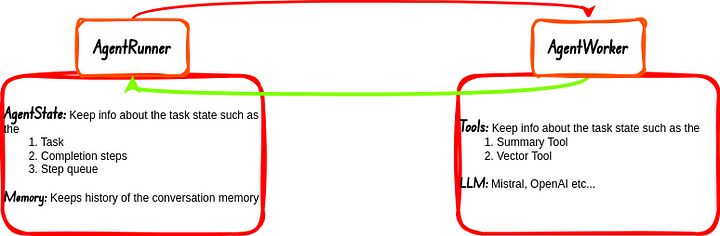
- AgentRunner: Esta es la parte del agente que se encarga de la orquestación de tareas aka Task Orchestrator. Esta sección del agente también maneja el Estado y la Memoria. El AgentWorker responde a esta sección del agente después de completar cada tarea que se le asigna, la respuesta se comunica al usuario si es necesario.
- AgentWorker: Es lo que realmente ejecuta y razona las tareas. Las tareas son delegadas a esta sección del flujo de trabajo del agente por el AgentRunner. Se ocupa de las Herramientas y LLMs.
Recursos de vídeo
Si te gusta ver vídeos en lugar de leer, también tengo algo para ti.
Configuración del entorno
Utilizaremos el mismo entorno que configuramos en el artículo anterior. Lo único que crearé es un archivo .ipynb, este archivo se llama Lesson_03.ipynb:
Creando Herramientas
Vamos a seguir adelante y crear dos herramientas principales como ya hemos hecho en los últimos artículos.
import dotenv %load_ext dotenv %dotenv import nest_asyncio nest_asyncio.apply()
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=["./datasets/lora_paper.pdf"]).load_data()
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
from llama_index.core import SummaryIndex, VectorStoreIndex
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the the Lora paper."
),
)
Bucle de razonamiento
El bucle de razonamiento depende del tipo de agente.
Tenemos soporte para los siguientes agentes:
- Agentes de llamada a función (se integra con cualquier LLM de llamada a función).
- Agente ReAct (funciona a través de cualquier endpoint de finalización de chat/texto).
«Agentes avanzados: LLMCompiler (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-llm-compiler?from=), Chain-of-Abstraction (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-coa?from=), Language Agent Tree Search (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-lats?from=), y más.
AgentWorker
Como hemos comentado anteriormente, el agent worker es el responsable de ejecutar todas las herramientas y los LLMs. Vamos a crear un agent worker pasándole todas las herramientas que hemos creado anteriormente:
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tools=[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
Para ello, utilicemos una pregunta que requiera un razonamiento de varios pasos.
response = agent.query(
"Explain to me what is Lora and why it's being used. Are existing solutions not good enough?"
)
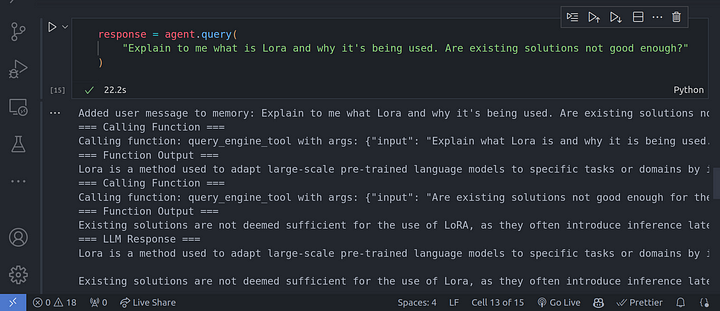
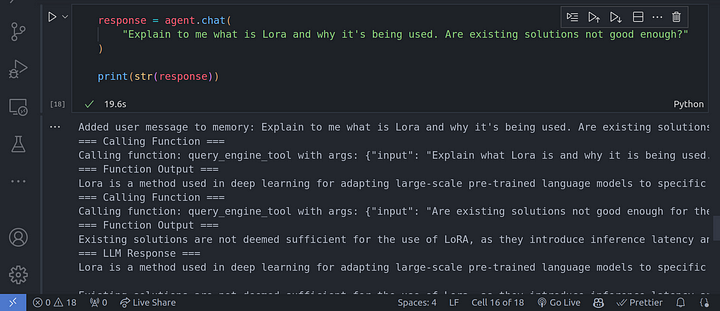
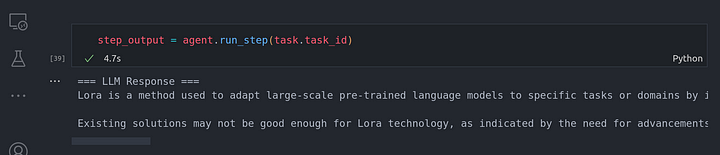
En la imagen de arriba, se puede ver que el LLM está haciendo uso de una cadena de razonamiento CoT para responder a todas las preguntas que le habíamos planteado, una tras otra, basándose en la anterior.
Memoria de conversaciones
Hasta ahora, la arquitectura de agentes RAG funciona bien. Una limitación es que no recuerda conversaciones anteriores. Tenemos la capacidad de mantener una memoria tal que las acciones que realiza el agente no sólo dependen de la consulta del usuario, sino que también se tiene en cuenta el historial de las conversaciones anteriores con los agentes.
La memoria no es más que una lista plana de conversaciones que el agente ha mantenido con el usuario. Esta lista es un buffer de memoria conversacional, la razón es que no queremos tener demasiada conversación almacenada en memoria de tal forma que desbordemos la ventana de contexto de los LLMs. Esta lista actúa como un buffer rodante dependiendo del tamaño de la ventana de contexto del LLM subyacente que estemos usando.
Para utilizar la capacidad de memoria del agente, tenemos que llamar al método chat() en lugar del método query() que hemos utilizado hasta ahora. El método query() no conserva el estado, por lo que no se conserva el historial de la conversación.
response = agent.chat(
"Explain to me what is Lora and why it's being used. Are existing solutions not good enough?"
)
print(str(response))
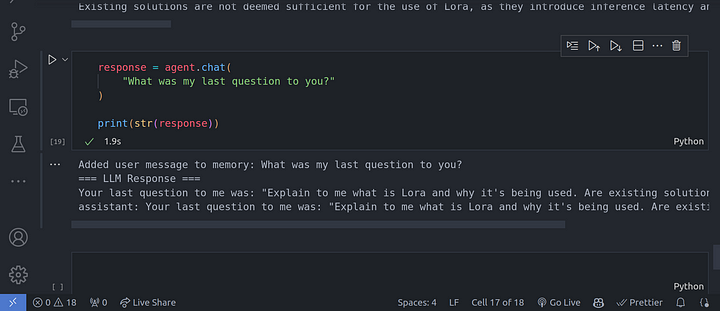
response = agent.chat(
"What was my last question to you?"
)
print(str(response))
Cómo funciona a bajo nivel
Hemos visto cómo funciona el agente desde una perspectiva de alto nivel. Echemos un vistazo a cómo funciona en un nivel inferior y obtengamos más control sobre la ejecución del agente y cómo se llevan a cabo las tareas. Esto nos da algunas ventajas añadidas como:
- Programar nuestras propias tareas: Podemos controlar y programar nuestras propias tareas y establecer cuando se ejecutará cada tarea.
- Incorporar feedback humano: Entendiendo cómo funciona el agente a un nivel inferior, podemos ser capaces de proporcionar manualmente feedback humano al agente para hacerle saber si está dando los pasos correctos que queremos o no, en caso contrario podemos especificar manualmente al agente qué acciones queremos que realice.
- Ayuda a la resolución de problemas
En primer lugar, vamos a seguir adelante y crear un agente de ejecución, que se ejecuta el agente de trabajo como hemos discutido anteriormente.
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
Ahora vamos a crear manualmente una tarea para el agentrunner Orchestrator:
task = agent.create_task(
"Explain to me what is Lora and why it's being used."
"Are existing solutions not good enough?"
)
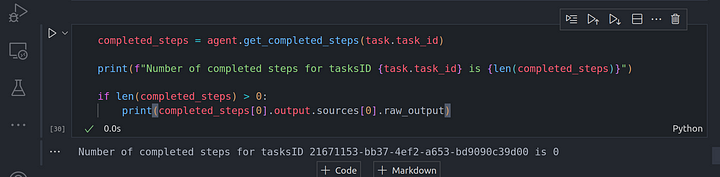
Una vez que tenemos esta tarea creada, recuerda que no pasamos esta tarea al agent worker por lo que no se ejecuta. Así que si comprobamos si se ha completado alguna tarea, deberíamos obtener cero, veamos esto en acción:
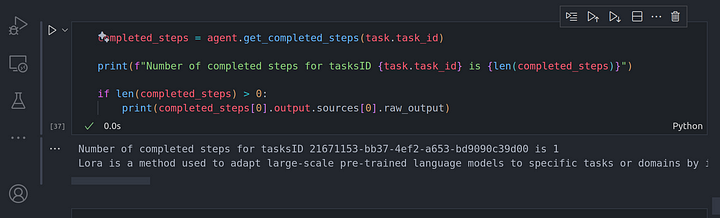
completed_steps = agent.get_completed_steps(task.task_id)
print(f"Number of completed steps for tasksID {task.task_id} is {len(completed_steps)}")
if len(completed_steps) > 0:
print(completed_steps[0].output.sources[0].raw_output)
Ahora, vamos a comprobar si el agentrunner ha orquestado algunas tareas para que las ejecute el agent worker. Podemos ver esto viendo las próximas tareas:
upcoming_steps = agent.get_upcoming_steps(task.task_id)
print(f"Number of completed steps for tasksID {task.task_id} is {len(upcoming_steps)}")
if len(upcoming_steps) > 0:
print(upcoming_steps[0].input)
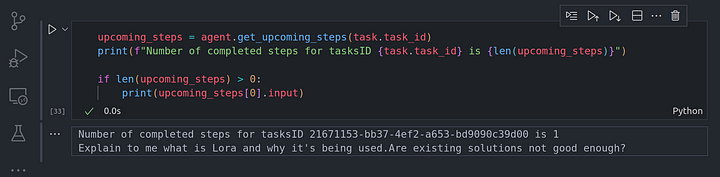
Desde aquí podemos ver la entrada que el agentrunner debe pasar al agent worker para que la ejecute. La entrada es la pregunta original que pasamos a la tarea que acabamos de crear. Ahora, vamos a seguir adelante y ejecutar la próxima tarea programada para ver y volvemos.
step_output = agent.run_step(task.task_id)
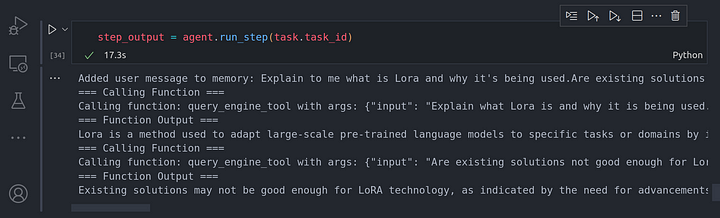
Se puede ver que el agent worker fue capaz de razonar sobre la tarea e identificó que necesitaba dividir la tarea en dos subtareas separadas. Cada subtarea se resolvió mediante el uso de la herramienta de llamada aka función de llamada a la herramienta de motor de consulta en este caso particular.
Una vez hecho esto, podemos seguir adelante para comprobar si hay otras tareas que tenemos que completar y cuáles son sus entradas:
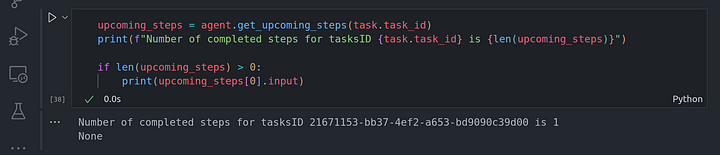
También podemos comprobar si este es el último paso que necesitábamos ejecutar:
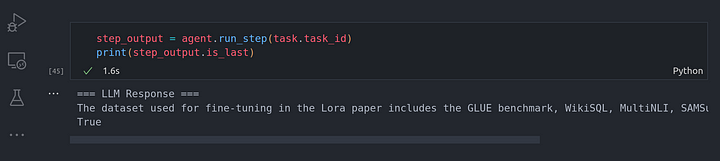
print(step_output.is_last)

Se puede ver que hemos obtenido True, concretamente, un Python true indicando que era el último paso en la ejecución de la tarea.
También podemos sobreescribirlo proporcionando nuestras tareas personalizadas, esto puede actuar como un humano corrigiendo al agente sobre lo que necesita hacer, una especie de feedback guía humano.
Para ello, voy a crear una nueva tarea, y luego añadir la retroalimentación humana en el bucle y cambiar la pregunta de la tarea.
task = agent.create_task(
"Explain to me what is Lora and why it's being used."
"Are existing solutions not good enough?"
)
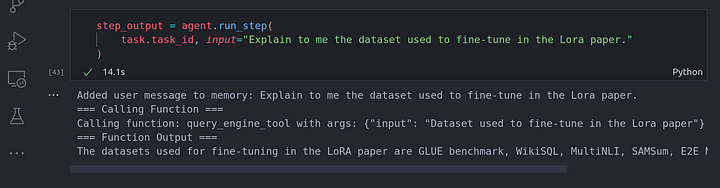
step_output = agent.run_step(
task.task_id, input="Explain to me the dataset used to fine-tune in the Lora paper."
)
Tenemos que comprobar si es el último paso, esto es importante o te dará un error. No sé por qué tuvieron que hacer eso.
Una vez hecho esto, podemos pasar a obtener la respuesta definitiva:
response = agent.finalize_response(task.task_id)
print(str(response))

Conclusión
Enhorabuena por haber llegado hasta aquí. En este artículo hemos repasado cómo trabajar con un bucle de razonamiento multipaso en un sistema RAG agéntico. No sólo hemos visto la implementación de alto nivel, sino también el funcionamiento a bajo nivel del bucle de razonamiento multipaso y la posibilidad de proporcionar feedback al agente (feedback humano en el bucle).
Espero que este artículo te proporcione una clara comprensión de la capacidad de razonamiento multipaso de un agente. En el próximo artículo, veremos cómo realizar capacidades RAG utilizando múltiples documentos.
Otras plataformas en las que puedes ponerte en contacto conmigo:
Referencias
The post RAG Agentic Con Llama-index | Capacidad de Razonamiento Multipaso #03 first appeared on Planeta Chatbot.
]]>The post Agentic RAG con Llama-index | Llamada a función #02 first appeared on Planeta Chatbot.
]]>Qué es una herramienta
Una herramienta es esencialmente una función Python que pasamos a los LLMs, permitiéndoles interactuar con el mundo externo. Puedes escribir una herramienta que interactúe con tu API personal, y el LLM puede entonces llamar a esta herramienta, pasando los argumentos necesarios basados en la consulta del usuario. Esto permite interacciones dinámicas y poderosas entre el LLM y sistemas externos.
Por qué la llamada a herramientas
Puede que al principio te preguntes por qué necesitamos la llamada a herramientas. Al fin y al cabo, la función principal del LLM en un sistema RAG es la síntesis. Entonces, ¿por qué necesita llamar a una función, también conocida como herramienta?
Bueno, si leíste el último artículo, ¿recuerdas cómo determinamos el mejor motor de rutas a ejecutar cuando trabajamos con el motor de consultas del enrutador? El LLM, utilizando un selector (LLMSingleSelector), fue capaz de elegir qué herramienta de motor de enrutamiento utilizar. Este es sólo un ejemplo de por qué necesitamos la llamada a herramientas.
Imagina que estamos construyendo un sistema de reservas con un LLM o queremos escribir automáticamente la salida de un pipeline RAG en un fichero usando un sistema basado en LLM. Tenemos que definir una función que se encargue de escribir el contenido en un archivo y, a continuación, pasar esta función al LLM. El LLM puede entonces determinar los argumentos necesarios para pasar al llamar a esta función. Esa función es una herramienta. Esperamos que estos ejemplos nos aclaren por qué necesitamos llamar a funciones.
Configuración e inicializaciones
Usaremos el entorno que configuramos en el último artículo. La única diferencia es que voy a crear un nuevo .ipynb que vamos a utilizar para este artículo de llamada a la herramienta.
Funciones de ejemplo para herramientas
Vamos a definir un par de funciones que podremos utilizar más adelante como herramientas. En este caso pueden ser cualquier tipo de funciones. Sólo asegúrate de tener dos cosas muy importantes en tus funciones:
- Anotaciones de tipo: Esto ayudará al LLM a saber qué tipo de datos o tipo de datos necesita pasar tu función o herramienta.
- Función do-strings: Esto le dará una descripción de la herramienta o función al LLM para que sepa para que puede ser usada la función o herramienta.
def add(x: int, y: int) -> int:
«»»Add two numbers together.»»»
return x + y
# substraction function
def sub(x: int, y: int) -> int:
«»»Substract two numbers.»»»
return x – y
# multiplication function
def mul(x: int, y: int) -> int:
«»»Multiply two numbers.»»»
return x * y
# get user information
def get_user_info(name: str) -> str:
«»»Get user information.»»»
data = {
«John Doe»: {
«age»: 30,
«location»: «USA»
},
«Jane Doe»: {
«age»: 25,
«location»: «UK»
}
}
return f’User name {name}, age is {data[name][«age»]} and location is {data[name][«location»]}’
Creando herramientas a partir de Funciones Python
Una vez que tenemos estas funciones definidas, podemos pasar a convertir estas funciones en herramientas que el LLM puede invocar. Para ello podemos utilizar el siguiente bloque de código:
from llama_index.core.tools import FunctionTool
addition_tool = FunctionTool.from_defaults(fn=add)
get_user_info_tool = FunctionTool.from_defaults(fn=get_user_info)
multiplication_tool = FunctionTool.from_defaults(fn=mul)
substraction_tool = FunctionTool.from_defaults(fn=sub)
tools = [addition_tool, get_user_info_tool, multiplication_tool, substraction_tool]
Probando la Llamada a Herramientas
Ahora que hemos conseguido convertir nuestras funciones Python en herramientas, vamos a probarlas pasándoles una consulta que requiera el uso de una de las herramientas.
from llama_index.llms.openai import OpenAI
llm = OpenAI(model=»gpt-3.5-turbo»)
response = llm.predict_and_call(
tools,
«What is the product of 4 and 5»,
verbose=True
)
print(str(response))
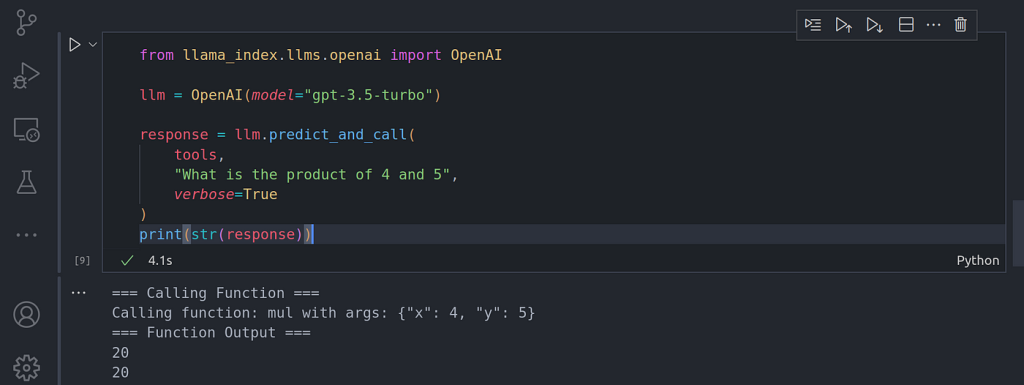
response = llm.predict_and_call(
tools,
«Give more the details of John Doe»,
verbose=True
)
print(str(response))
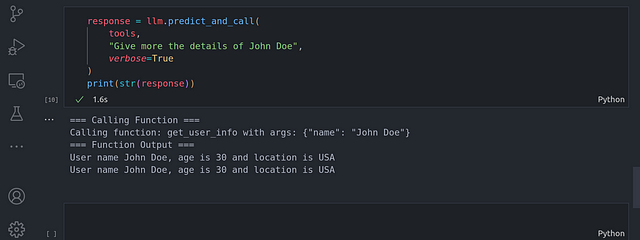
Aquí podemos ver no sólo que el LLM es capaz de saber a qué función llamar y a qué herramientas llamar, sino también qué parámetros pasar a esas funciones y herramientas llamadas.
Búsqueda vectorial con metadatos
Ya que el LLM es capaz de saber qué herramienta llamar y qué función pasar, podemos utilizar esto para pasar a la herramienta de búsqueda vectorial metadatos tales como el número de página del documento en el que queremos buscar.
Para crear la búsqueda con capacidad de filtrado de metadatos, primero necesitaremos construir una búsqueda vectorial simple, implementaremos todo lo que vimos en el primer artículo.
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[«./datasets/lora_paper.pdf»]).load_data()
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
from llama_index.core import VectorStoreIndex
# vector store index
vector_index = VectorStoreIndex(nodes)
Añadir capacidad de filtrado de metadatos:
from llama_index.core.vector_stores import MetadataFilters
# Create vector search query engine
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
[
{«key»: «page_label», «value»: «2»}
]
)
)
response = query_engine.query(
«Tell me about the Problem statement as explained»,
)
print(str(response))
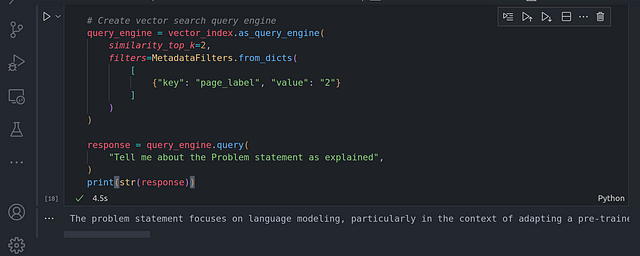
En el código anterior, limitamos la búsqueda únicamente a la página 2, donde se habla del planteamiento del problema en el documento de investigación. Podemos confirmar que la búsqueda sólo se realizó en la página 2 utilizando:
for n in response.source_nodes:
print(n.metadata)
print(«=============Text=============»)
print(n.get_text())
print(«=============Text=============»)
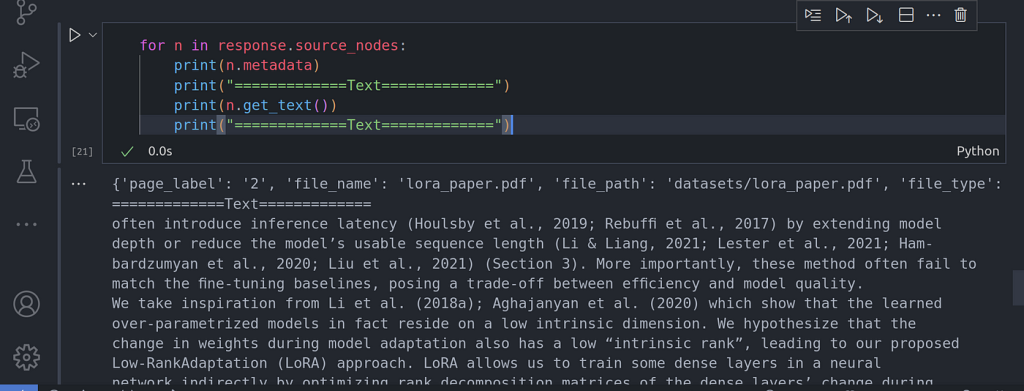
En la imagen de la ejecución del código anterior, puede ver que la búsqueda de los nodos se limita únicamente a la página número dos. También puede introducir otros metadatos.
Herramienta de recuperación automática
Ahora que somos capaces de recuperar contenido especificando otros metadatos. Una cosa que puede notar es que tuvimos que especificar manualmente el filtro de metadatos. En la mayoría de los casos, esto no es lo ideal. ¿Podemos obtener el LLM especificar en el propio filtro basado en lo que la consulta del usuario se pasó. Ejemplo:
«¿Qué se mencionó sobre el planteamiento del problema en la página 2?».
A partir de esta consulta, el LLM debería ser capaz de pasar en el filtro de metadatos el número de página como 2. Implementemos esto:
Primero implementemos la búsqueda vectorial:
from typing import List
from llama_index.core.vector_stores import FilterCondition
def vector_search_query(
query: str,
page_numbers: List[str]
) -> str:
«»»Conduct a vector search across an index using the following parameters:
query (str): This is the text string you want to embed and search for within the index.
page_numbers (List[str]): This parameter allows you to limit the search to
specific pages. If left empty, the search will encompass all pages in the index.
If page numbers are specified, the search will be filtered to only include those pages.
«»»
metadata_dicts = [
{«key»: «page_label», «value»: p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
condition=FilterCondition.OR
)
)
response = query_engine.query(query)
return response
vector_query_tool = FunctionTool.from_defaults(
name=»vector_search_tool»,
fn=vector_search_query
)
response = llm.predict_and_call(
[vector_query_tool],
«What was mentioned about the problem statement in page 2?»,
verbose=True
)
Ahora puede ver que la llamada a la función se realiza automáticamente pasando los metadatos correctos como página 2. El LLM fue capaz de inferir el filtro de metadatos de número de página. Hay otros filtros de metadatos que podemos utilizar, como los filtros de metadatos de pie de página.
Podemos confirmar que los datos fueron recuperados de la página 2 usando lo siguiente:
for n in response.source_nodes:
print(n.metadata)
print(«=============Text=============»)
print(n.get_text())
print(«=============Text=============»)
Ahora, incorporemos la herramienta de resumen para asegurarnos de que el enrutador es capaz de elegir la herramienta de motor de consulta correcta que debe utilizar.
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
name=»summary_tool»,
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
response = llm.predict_and_call(
[vector_search_query_tool, summary_tool],
«What was mentioned about the problem statement in page 2?»,
verbose=True
)
response = llm.predict_and_call(
[vector_search_query_tool, summary_tool],
«Give me a summary of the paper.»,
verbose=True
)
for n in response.source_nodes:
print(n.metadata)
print(«=============Text=============»)
print(n.get_text()[:10])
print(«=============Text=============»)
Conclusión
Enhorabuena por haber llegado hasta aquí. Hemos hecho una inmersión profunda en la llamada a herramientas. Hasta ahora todo lo que hemos hecho desde el primer artículo ha girado en torno a la llamada de herramientas de un solo paso donde todo se hace en un solo bucle.
Esto tiene algunas limitaciones, vamos a abordar esto en el próximo artículo cuando nos sumergimos en el bucle de razonamiento con el razonamiento de varios pasos.
Otras plataformas donde puedes ponerte en contacto conmigo:
¡Feliz codificación! Y hasta la próxima, que el mundo sigue girando.
The post Agentic RAG con Llama-index | Llamada a función #02 first appeared on Planeta Chatbot.
]]>The post Agentic RAG con Llama-index | Motor de consulta del enrutador #01 first appeared on Planeta Chatbot.
]]>El año pasado la palabra de moda eran los sistemas RAG, este año las cosas han dado un giro, ahora todo gira en torno a los agentes. Si echas de menos la era de la palabra de moda RAG, no pasa nada porque también podemos introducir agentes en los sistemas RAG. Lo bueno es que es incluso mejor.
En este artículo, repasaremos cómo implementar una aplicación RAG Agentic básica usando Llama-index. Este es el primer artículo de una serie de artículos que publicaré en las próximas semanas sobre arquitecturas RAG Agentic.
Canal básico de generación mejorada de recuperación (RAG)
Antes de continuar, quiero refrescar un poco cómo es y cómo funciona una arquitectura RAG tradicional. Este conocimiento será útil más adelante y también para los principiantes que no sepan cómo funciona una canalización RAG básica.

De la imagen anterior de un sistema RAG sencillo, tenemos simplemente lo siguiente con lo que trabajamos:
- Documentos: Este es el contexto en el que quieres aumentar tu LLM con información externa que alimenta a un LLM. Puede ser un PDF o cualquier otro documento de texto o incluso imágenes para un LLM multimodal.
- Trozos: El documento más grande se divide en tamaños más pequeños que normalmente se llaman trozos, a veces también llamados nodos.
- Incrustaciones: Una vez que tenemos los trozos de menor tamaño, creamos incrustaciones vectoriales para ellos. Una vez recibida la consulta del usuario, se realiza una búsqueda de similitudes y se recuperan los documentos más parecidos. Estos fragmentos de documento recuperados se envían junto con la consulta del usuario al LLM, y los documentos recuperados actúan como contexto. A partir de ahí, el LLM genera una respuesta.
La explicación anterior es el funcionamiento típico de un sistema tradicional de RAG.
Por qué RAG Agentic
Hemos visto la implementación de una RAG simple desde arriba, este enfoque es adecuado para tareas simples de GC sobre uno o pocos documentos. No es adecuado para tareas complejas de control de calidad y resumen de grandes conjuntos de documentos.
Aquí es donde los agentes pueden entrar en juego, para ayudar a llevar la simple implementación de la RAG a otro nivel. Con los sistemas RAG agénticos, las tareas más complejas, como el resumen de documentos, el control de calidad complejo y muchas otras tareas, pueden llevarse a cabo mucho más fácilmente. Agentic RAG también le ofrece la posibilidad de incorporar llamadas a herramientas en su sistema RAG y estas herramientas pueden ser funciones personalizadas que usted mismo defina.
En esta serie de artículos, repasaremos lo siguiente:
- Motores de consulta de enrutadores: Esta es la forma más simple de un RAG agéntico. Esto nos da la habilidad de añadir sentencias lógicas que pueden ayudar al LLM a decidir sobre qué ruta enrutar una tarea específica dependiendo de la(s) tarea(s) que necesite(n) ser llevada(s) a cabo y del conjunto de herramientas que hayamos puesto a disposición del LLM.
- Llamada a Herramientas: Aquí veremos cómo añadir nuestras propias herramientas personalizadas a la arquitectura agentic RAG. Aquí implementaremos interfaces para que los agentes seleccionen una herramienta de entre un conjunto de herramientas que les proporcionaremos y luego dejaremos que el LLM proporcione los argumentos necesarios que hay que pasar para llamar a estas herramientas, ya que estas herramientas son simplemente funciones de Python, al menos las que tú mismo has definido.
- RAG Agentico con Capacidades de Razonamiento Multipaso
- RAG Agenética con Capacidades de Razonamiento Multipaso con Múltiples Documentos
Motor de consulta del enrutador
Esta es la forma más simple de RAG agentic, al menos en Llama-index. En este enfoque simplemente tenemos un motor de enrutamiento que, con la ayuda de un LLM, determina qué herramienta o motor de consulta utilizar para abordar una consulta de usuario dada.
Esta es la implementación básica de cómo funciona un motor de consulta de enrutador.

Configuración del entorno del proyecto
Para configurar tu entorno de desarrollo, crea una carpeta llamada agentic_rag, dentro de esta carpeta, crea otra carpeta llamada basics. Una vez hecho esto, navega dentro de la carpeta basics e inicializa un Python Poetry project
$ poetry init
Para empezar, asegúrate de que tienes tu clave API OpenAI lista, puedes obtener tu clave desde aquí si aún no la tienes. Una vez que tengas tu clave api lista, añádela a tu archivo .env:
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Entonces, ¿dónde está este archivo .env? Bueno, he creado una configuración env desarrollo de la siguiente manera:


Sigue esta estructura de directorios y añada sus archivos como se muestra en las imágenes anteriores.
Instalación de paquetes
Usaremos Llama-index para esto. Vamos a instalarlo junto con otras librerías que utilizaremos:
$ poetry add python-dotenv ipykernel llama-index nest_asyncio
Descarga del conjunto de datos
Necesitaremos un archivo PDF para experimentar. Puedes descargar este PDF desde aquí. De nuevo, siéntete libre de utilizar cualquier archivo PDF de su agrado.

Cargar y escupir el documento en los nodos
Ahora estamos listos para empezar, primero vamos a cargar nuestras variables de entorno utilizando la biblioteca python-dotenv que acabamos de instalar:
import dotenv
%load_ext dotenv
%dotenv
También usaremos la biblioteca nest-asyncio ya que Llama-index usa muchas funciones asyncio en segundo plano:
import nest_asyncio
nest_asyncio.apply()
Ahora, carguemos nuestros datos:
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[«./datasets/lora_paper.pdf»]).load_data()
Crear fragmentos de documentos
Una vez que hayamos cargado los datos correctamente, avancemos para dividir el documento más grande en fragmentos de 1024 tamaños de fragmentos:
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
Podemos obtener más información sobre cada uno de estos nodos usando:
node_metadata = nodes[1].get_content(metadata_mode=True)
print(node_metadata)

Creación de LLM e incorporación de modelos
Usaremos el modelo OpenAI gpt-3.5-turbo como LLM y el modelo de incrustación text-embedding-ada-002 para crear las incrustaciones.
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
Creando índices
Como se muestra en las imágenes anteriores, tendremos dos índices principales que usaremos:
- Índice resumido: obtuve esta explicación de los documentos oficiales de Llamaindex:
El índice resumido es una estructura de datos simple donde los nodos se almacenan en una secuencia. Durante la construcción del índice, los textos del documento se fragmentan, se convierten en nodos y se almacenan en una lista.
Durante el tiempo de consulta, el índice de resumen recorre los nodos con algunos parámetros de filtro opcionales y sintetiza una respuesta de todos los nodos.
- Índice vectorial: este es solo un almacén de índice normal creado a partir de incrustaciones de palabras desde el cual podemos realizar búsquedas de similitud para obtener el n índice más similar.
Podemos usar el siguiente código para crear estos dos índices:
from llama_index.core import SummaryIndex, VectorStoreIndex
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
Convertir índices vectoriales en motores de consulta
Una vez que tengamos los índices vectoriales creados y almacenados, tendremos que continuar con la creación de los motores de consulta que convertiremos en herramientas, también conocidas como herramientas de consulta, que nuestros agentes podrán usar más adelante.
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
En el caso anterior, tenemos dos motores de consulta diferentes. Colocaremos cada uno de estos motores de consulta debajo de un motor de consulta de enrutador que luego decidirá a qué motor de consulta enrutar según la consulta del usuario.

En el código anterior, especificamos el parámetro use_async para realizar consultas más rápidas; esta es una de las razones por las que también tuvimos que usar la biblioteca next_asyncio.
Herramientas de consulta
Una herramienta de consulta es simplemente un motor de consulta con metadatos, específicamente una descripción de para qué se puede utilizar o para qué sirve la herramienta de consulta. Esto ayuda al motor de consultas del enrutador a poder decidir a qué herramienta del motor de consultas enrutar dependiendo de la consulta que recibe.
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
«Useful for retrieving specific context from the the Lora paper.»
),
)
Motor de consulta de enrutador
Finalmente, podemos continuar con la creación de la herramienta del motor de consulta del enrutador. Esto nos permitirá utilizar todas las herramientas de consulta que creamos a partir de los motores de consulta que definimos anteriormente, específicamente summary_tool y vector_tool.

from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=True
)
LLMSingleSelector: este es un selector que utiliza LLM para seleccionar una única opción de una lista de opciones. Puedes leer más al respecto desde aquí.
Probando el motor de consulta del enrutador
Sigamos adelante y usemos el siguiente código para probar el motor de consulta del enrutador:
response = query_engine.query(«What is the summary of the document?»)
print(str(response))

Arriba está el resumen del artículo que se resume en todo el contexto en el documento Lora dado que pasamos al motor de consulta de resumen.
Dado que estamos utilizando el índice de resumen que almacena todos los nodos en una lista secuencial, se visitan todos los nodos y se genera un resumen general de todos los nodos para obtener el resumen final.
Puedes confirmar esto comprobando la longitud de la respuesta, el atributo source_nodes nos devuelve las fuentes utilizadas para generar el resumen.
print(len(response.source_nodes))

Puedes notar que el número 38 es el mismo que el número de nodos que obtuvimos después de realizar la fragmentación del documento. Esto significa que todos los nodos fragmentados se han utilizado para generar el resumen.
Hagamos otra pregunta que no implique el uso de la herramienta de resumen.
response = query_engine.query(«What is the long from of Lora?»)
print(str(response))

Esto utiliza la herramienta de índice de vectores; sin embargo, la respuesta no es tan precisa.
Poniendolo todo junto
Ahora que hemos entendido esta canalización básica, avancemos para convertirla en una función de canalización que llamaremos utilizar más adelante.
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
«Useful for retrieving specific context from the the Lora paper.»
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
Entonces podemos llamar a esta función de la siguiente manera:
query_engine = await create_router_query_engine(«./datasets/lora_paper.pdf»)
response = query_engine.query(«What is the summary of the document?»)
print(str(response))

Sigamos adelante y creemos un archivo utils.py y tengamos lo siguiente dentro de él:

from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SummaryIndex, VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model=»gpt-3.5-turbo»)
# embedding model
Settings.embed_model = OpenAIEmbedding(model=»text-embedding-ada-002″)
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode=»tree_summarize»,
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
«Useful for summarization questions related to the Lora paper.»
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
«Useful for retrieving specific context from the the Lora paper.»
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
Luego podremos utilizar esta llamada de función desde este archivo más adelante:
from utils import create_router_query_engine
query_engine = await create_router_query_engine(«./datasets/lora_paper.pdf»)
response = query_engine.query(«What is the summary of the document?»)
print(str(response))

Conclusión
Felicitaciones por llegar hasta aquí. Eso es todo lo que cubriremos en este artículo; en el próximo artículo, veremos cómo usar una llamada de herramienta, también conocida como llamada de función.
Otras plataformas donde puedes comunicarte conmigo:
¡Feliz codificación! Y hasta la próxima, el mundo sigue girando.
Referencias
The post Agentic RAG con Llama-index | Motor de consulta del enrutador #01 first appeared on Planeta Chatbot.
]]>