The post Los tensores son todo lo que necesitas first appeared on Planeta Chatbot.
]]>En este artículo, aprenderemos sobre una biblioteca llamada Hummingbird, creada para cerrar esta brecha. Hummingbird acelera la inferencia en los modelos tradicionales de machine learning convirtiéndolos en modelos basados en tensores. Esto nos permite usar modelos como los árboles de decisión de scikit-learn y el bosque aleatorio incluso en GPU y aprovechar las capacidades del hardware.
¿Qué es Hummingbird?
Como se mencionó anteriormente, Hummingbird es una biblioteca para acelerar la inferencia en modelos tradicionales de machine learning. Hummingbird logra esto compilando estas canalizaciones tradicionales de machine learning en cálculos de tensor. Esto significa que puede aprovechar la aceleración de hardware como GPU y TPU, incluso para modelos tradicionales de machine learning, sin rediseñar los modelos.
Esto es beneficioso en varios aspectos. Con la ayuda de Hummingbird, los usuarios pueden beneficiarse de:
- las optimizaciones implementadas en marcos de redes neuronales;
- aceleración de hardware nativo;
- tener una plataforma única para admitir modelos de redes tradicionales y neuronales;

Arquitectura de alto nivel de la biblioteca Hummingbird | Fuente: documento oficial
Además de las ventajas anteriores, Hummingbird también ofrece muchas funciones convenientes, algunas de las cuales se enumeran a continuación.
1️⃣. API de «inferencia» uniforme y conveniente
Hummingbird proporciona una API de «inferencia» uniforme y conveniente que imita de cerca la API de sklearn. Esto permite intercambiar modelos sklearn con modelos generados por Hummingbird sin tener que cambiar el código de inferencia.
2️⃣. Soporte para los principales modelos y características.
Esta versión actual de Hummingbird actualmente admite los siguientes operadores:
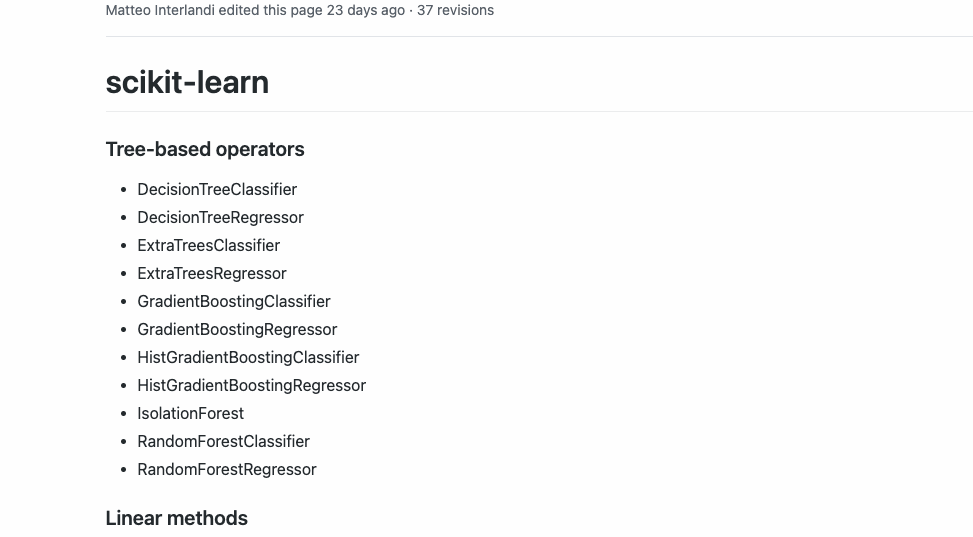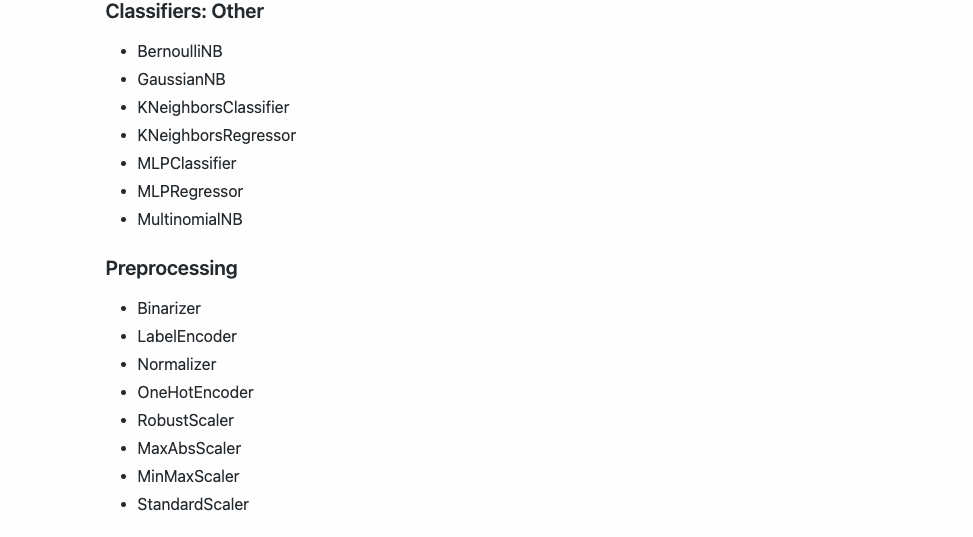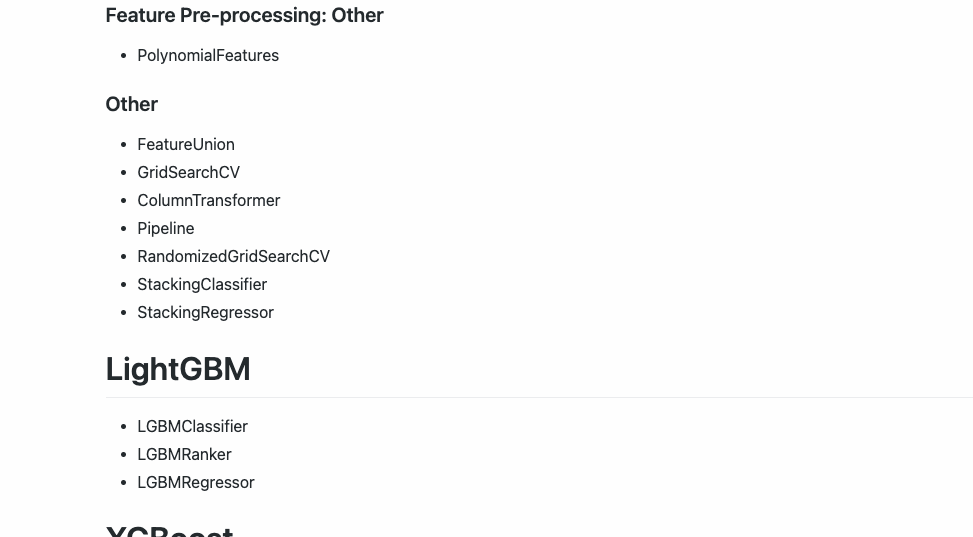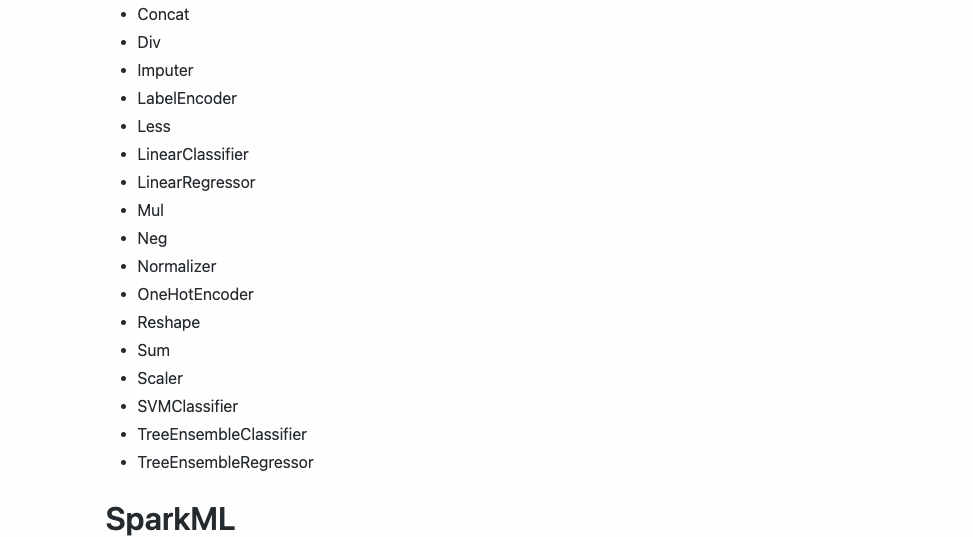
3️⃣. Capacidades de conversión
Actualmente, puedes usar Hummingbird para convertir tus modelos ML tradicionales entrenados en PyTorch, TorchScript, ONNX y TVM)

Hummingbird puede convertir tu machine learning tradicional entrenado | Imagen del autor
Trabajando
El objetivo principal de la biblioteca Hummingbird es acelerar la inferencia de los modelos tradicionales de machine learning. Se han desarrollado muchos sistemas especializados, como ONNX Runtime, TensorRT y TVM. Sin embargo, muchos de estos sistemas se centran en el Deep Learning. El problema con los modelos tradicionales es que se expresan utilizando código imperativo de una manera ad hoc. Entendamos esto a través de alguna representación visual.

Cómo funcionan los modelos tradicionales de machine learning | Imagen del autor | Reproducido de la sesión Hummingbird.
Los modelos tradicionales se expresan usando código imperativo de una manera ad hoc
Pensemos en un marco de datos que contiene cuatro columnas, de las cuales dos son categóricas y el resto dos numéricas. Estos se introducen en un modelo de machine learning, digamos regresión logística, para identificar si pertenecen a la clase 0 o la clase 1. Este es un caso clásico de un problema de clasificación binaria. Si miramos bajo el capó, tenemos un DAG o gráfico acíclico dirigido de operadores llamado pipeline. La canalización consta de características que preprocesan los datos y luego los introducen en un predictor, que generará la predicción.
Esta es solo una representación simple de cómo se vería un modelo tradicional. En todos los marcos tradicionales de machine learning, hay cientos y cientos de estas características y predictores. Como resultado, resulta difícil representarlos de una manera que tenga sentido en todos los marcos diferentes.
Los modelos de Deep Learning se expresan como DAG of Tensor Operations
Por otro lado, confiamos principalmente en la abstracción de los tensores en el Deep Learning que es solo una matriz multidimensional. Los modelos de Deep Learning también se expresan como un DAG, pero se centran explícitamente en los operadores de tensores. En el siguiente diagrama, tenemos operaciones matriciales muy genéricas que se pueden representar fácilmente en una amplia variedad de sistemas.
 Cómo funcionan los modelos de Deep Learning | Imagen del autor | Reproducido de la sesión Hummingbird.
Cómo funcionan los modelos de Deep Learning | Imagen del autor | Reproducido de la sesión Hummingbird.
Los sistemas de servicio de predicción de Deep Learning pueden capitalizar estas operaciones de tensores y explotar esta abstracción para trabajar en muchos entornos de destino diferentes.
Hummingbird convierte las tuberías tradicionales en operaciones tensoriales mediante la reconfiguración de operadores algorítmicos. El siguiente ejemplo de su blog oficial explica una de las estrategias de Hummingbird para traducir un árbol de decisiones en tensores que involucran GEMM (Multiplicación de matrices genéricas).

Transformar un árbol de decisiones simple en redes neuronales | Reproducido del blog oficial de Hummingbird
Demo
La sintaxis de Hummingbird es muy intuitiva y mínima. Para ejecutar tu modelo ML tradicional en marcos DNN, solo necesita importar hummingbird.ml y agregar convert (model, ‘dnn_framework’) a tu código. A continuación se muestra un ejemplo que utiliza un modelo de bosque aleatorio de scikit-learn y PyTorch como marco de destino.
Enlace para acceder a todo el código y el conjunto de datos
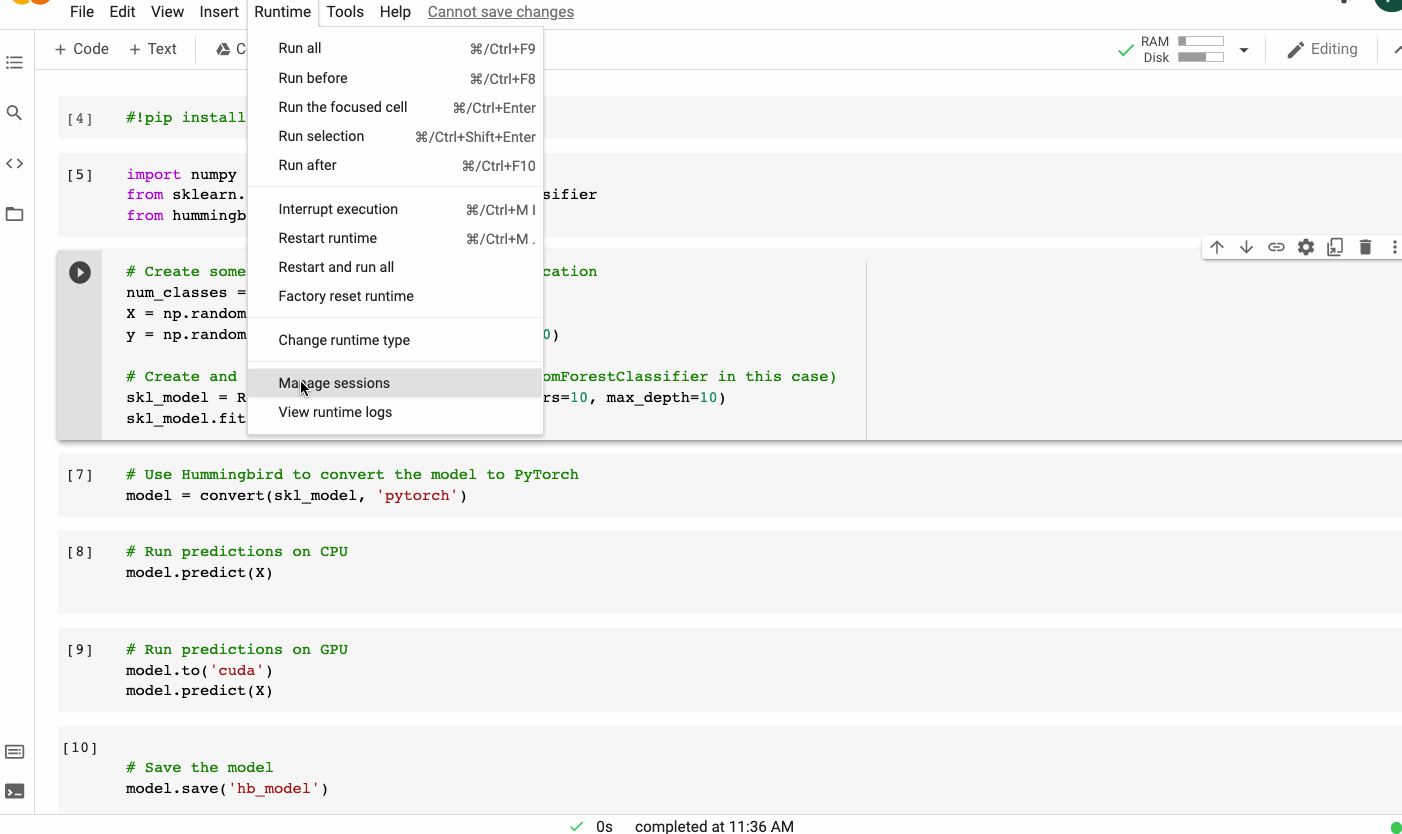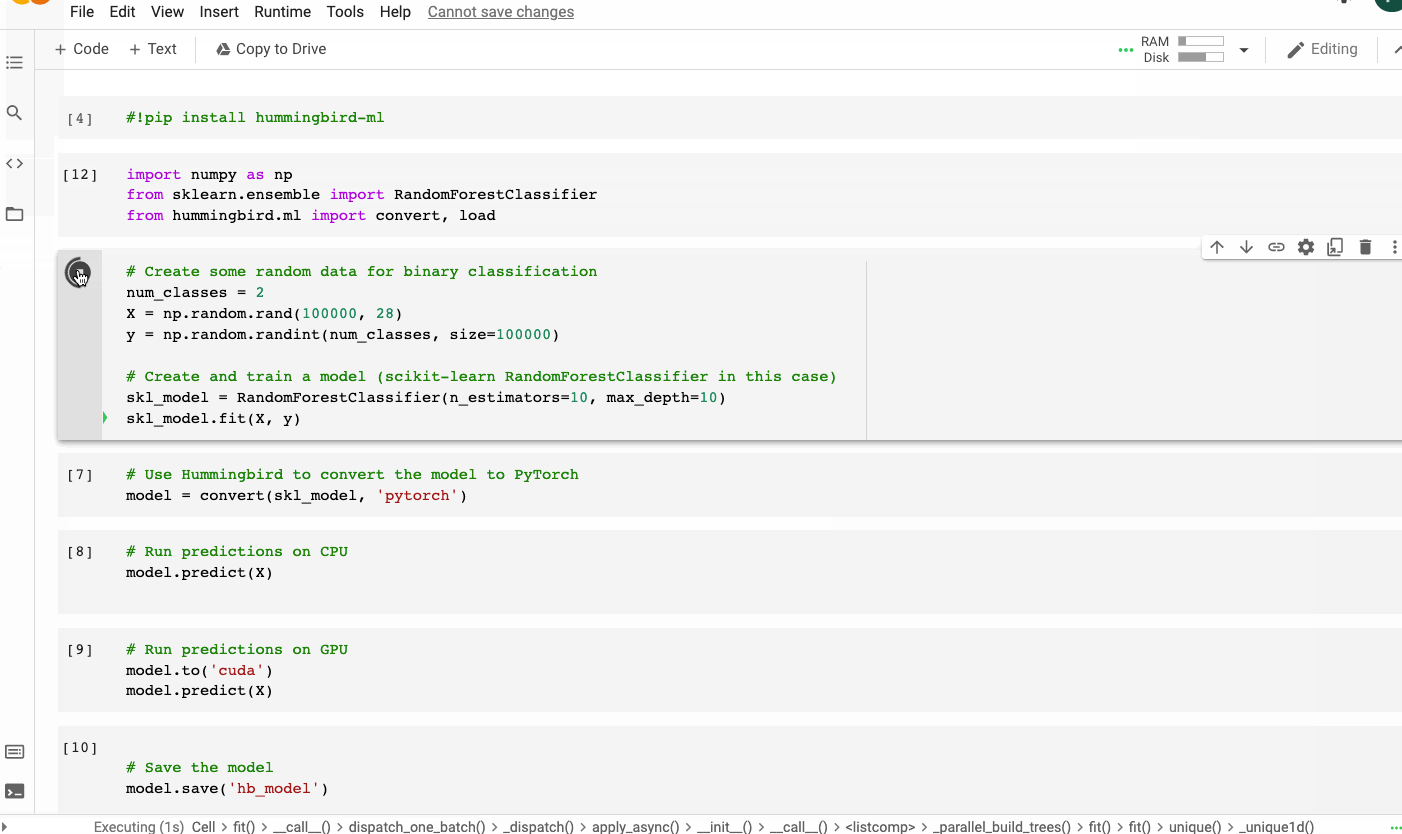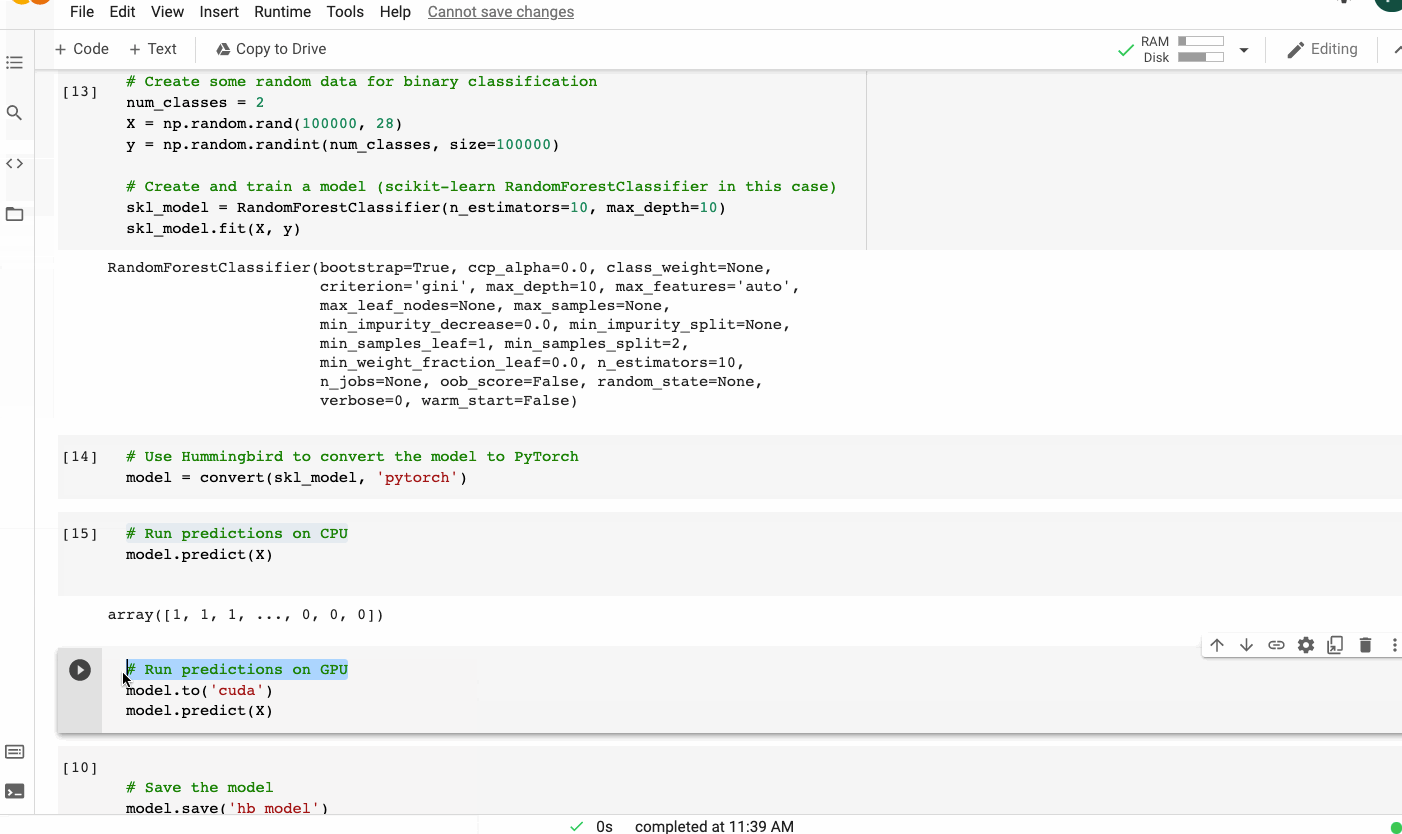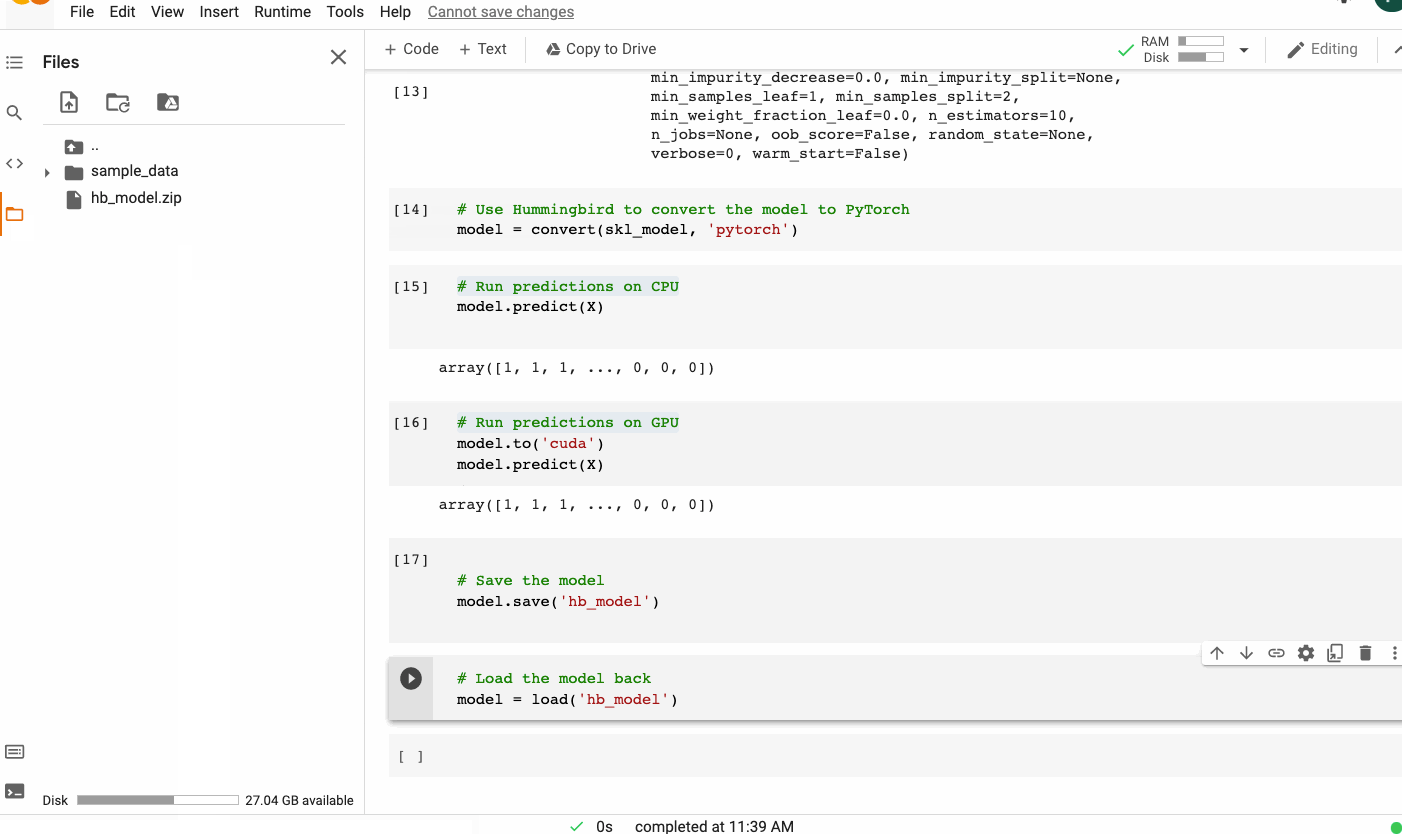
Usando un modelo de bosque aleatorio scikit-learn y PyTorch como marco de destino usando Hummingbird | Imagen del autor

Comparación en tiempos de un regresor de bosque aleatorio en CPU vs. GPU | Imagen del autor | Enlace al código
Conclusión
Hummingbird es una biblioteca prometedora y trabaja en un problema central en el espacio de machine learning. Dar la capacidad a los usuarios de realizar una transición fluida de la CPU a la GPU y aprovechar el acelerador de hardware para acelerar la inferencia ayudará a enfocarse directamente en los problemas en lugar del código. Si deseas ir más allá, asegúrate de consultar los recursos a continuación. Este artículo se basa en estas referencias y también las encontrará útiles si decide profundizar en las explicaciones subyacentes de la biblioteca.
Referencias
- https://github.com/microsoft/hummingbird
- Tensors Are All You Need: Faster Inference with Hummingbird
- A Tensor Compiler for Unified Machine Learning Prediction Serving.
- Compiling Classical ML Pipelines into Tensor Computations for One-size-fits-all Prediction Serving.
The post Los tensores son todo lo que necesitas first appeared on Planeta Chatbot.
]]>The post Cinco bibliotecas de Machine Learning de código abierto interesantes first appeared on Planeta Chatbot.
]]>Cada año se agregan más y más bibliotecas a este ecosistema. En este artículo, presento un recorrido rápido por algunas de las bibliotecas que encontré recientemente y que podrían ser un gran complemento para tu pila de Machine Learning.
1⃣. HummingBird
Humminbird es una biblioteca para compilar modelos de Machine Learning tradicionales entrenados en cálculos de tensores. Esto significa que puedes aprovechar la aceleración de hardware como GPU y TPU, incluso para los modelos tradicionales de Machine Learning. Esto es beneficioso en varios niveles.
- El usuario puede beneficiarse de las optimizaciones actuales y futuras implementadas en marcos de redes neuronales;
- El usuario puede beneficiarse de la aceleración de hardware nativo;
- El usuario puede beneficiarse de tener una plataforma única para admitir modelos de redes tradicionales y neuronales;
- El usuario no tiene que rediseñar sus modelos.

Además, Hummingbird también proporciona una API de «inferencia» uniforme y conveniente siguiendo la API de Sklearn. Esto permite intercambiar modelos de Sklearn con modelos generados por Hummingbird sin tener que cambiar el código de inferencia.

 Github
Github
- https://github.com/microsoft/hummingbird
 Papers
Papers
- Un compilador de tensor para el servicio de predicción de Machine Learning unificado.
- Compilación de canalizaciones de ML clásicas en cálculos de tensor para un servicio de predicción único para todos.
 Blog
Blog
 Demo
Demo
La sintaxis de Hummingbird es muy intuitiva y mínima. Para ejecutar tu modelo ML tradicional en marcos DNN, solo necesitas import hummingbird.ml y agregar convert(model, ‘dnn_framework’) a tu código. A continuación, se muestra un ejemplo que utiliza un modelo de bosque aleatorio de scikit-learn y PyTorch como marco de destino.
2⃣. Top2Vec
Los documentos de texto contienen mucha información. Examinarlos manualmente es difícil. El modelado de temas es una técnica ampliamente utilizada en la industria para descubrir temas en una gran colección de documentos de forma automática. Algunos de los métodos tradicionales y más utilizados son la asignación de Dirichlet latente (LDA) y el análisis semántico latente probabilístico (PLSA). Sin embargo, estos métodos adolecen de inconvenientes como no considerar la semántica o el orden de las palabras. Top2vec es un algoritmo que aprovecha la incrustación semántica conjunta de documentos y palabras para encontrar vectores de temas. Esto es lo que tienen que decir los autores:
Este modelo no requiere listas de palabras vacías, derivación o lematización, y encuentra automáticamente el número de temas. Los vectores de tema resultantes se incrustan conjuntamente con los vectores de documento y palabra y la distancia entre ellos representa la similitud semántica. Nuestros experimentos demuestran que top2vec encuentra temas que son significativamente más informativos y representativos del corpus entrenado que los modelos generativos probabilísticos. Incluso, los codificadores de oraciones universales pre-entrenados y el transformador de oraciones BERT están disponibles en codificación.
Una vez que se entrena un modelo Top2Vec, podemos hacer lo siguiente:

Github
Papers
 Documentation
Documentation
https://top2vec.readthedocs.io/en/latest/index.html
Demo
Aquí hay una demostración del entrenamiento de un modelo Top2Vec en el conjunto de datos de 20newsgroups. El ejemplo se ha tomado de su repositorio oficial de Github.
3⃣. BERTopic
BERTopic es otra técnica de modelado de temas que aprovecha las incrustaciones de BERT y un TF-IDF basado en clases para crear grupos densos que permiten temas fácilmente interpretables mientras se mantienen palabras importantes en las descripciones de los temas. También admite visualizaciones similares a LDAvis. Aquí hay un resumen rápido de las capacidades de BERTopic.

Github
https://github.com/MaartenGr/BERTopic
Documentación
https://maartengr.github.io/BERTopic/
Blog
Demo
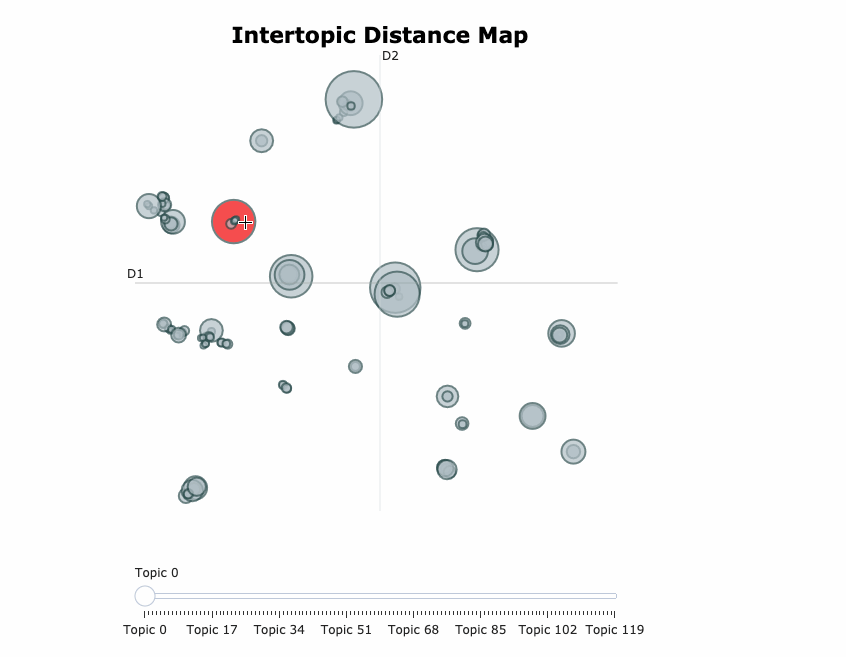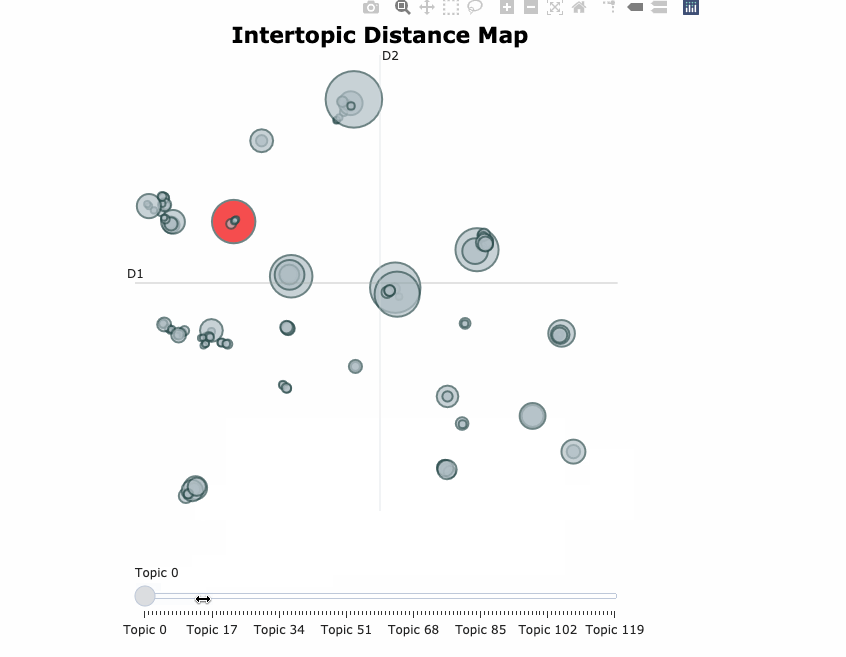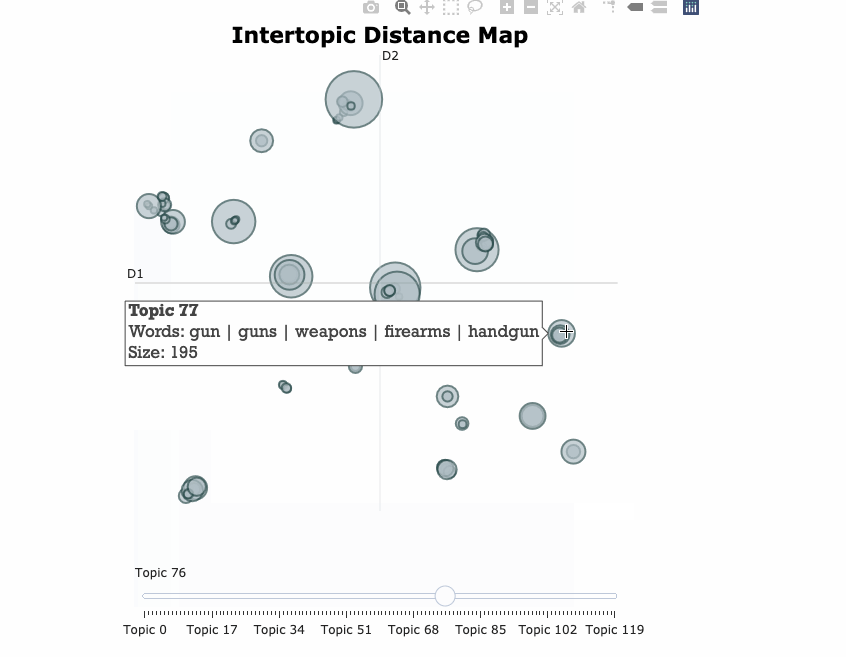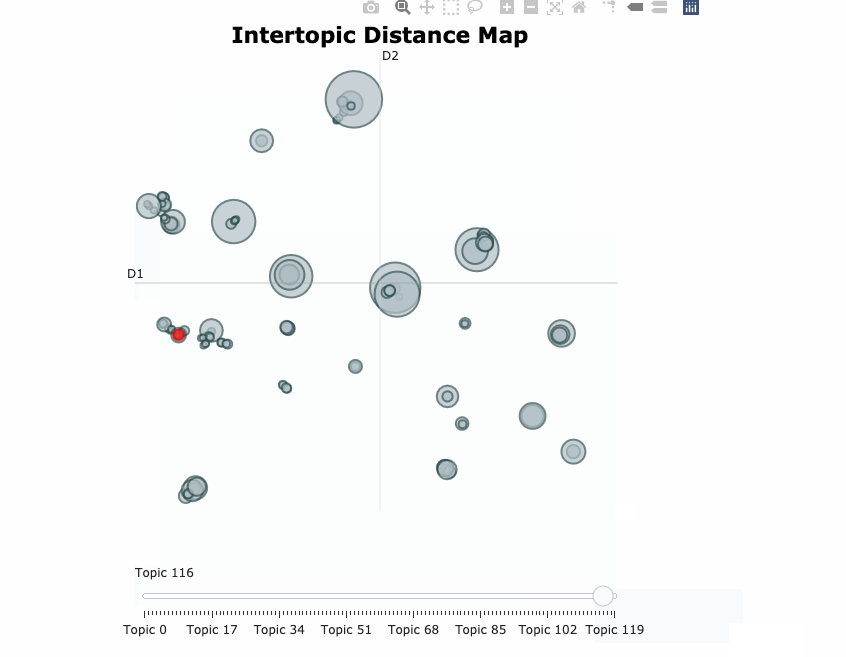
A visualization of the topics generated after training aBERTopic model on 20newsgroups dataset
Una visualización de los temas generados después de entrenar el modelo BERTopic en un conjunto de datos de 20 grupos de noticias.
4⃣. Captum
Captum es una biblioteca de interpretación y comprensión de modelos para PyTorch. Captum significa comprensión en latín y contiene implementaciones de propósito general de gradientes integrados, mapas de prominencia, smoothgrad, vargrad y otros para modelos PyTorch. Además, tiene una integración rápida para modelos creados con bibliotecas específicas de dominio como torchvision, torch text y otros. Captum también proporciona una interfaz web llamada Insights para facilitar la visualización y el acceso a varios de nuestros algoritmos de interpretación.
¡Captum se encuentra actualmente en fase beta y en desarrollo activo!
Github
https://github.com/pytorch/captum
Documentación
 Diapositivas
Diapositivas
- Las diapositivas de NeurIPS 2019 se pueden encontrar aquí.
- Las diapositivas del tutorial de KDD 2020 se pueden encontrar aquí.
Demo
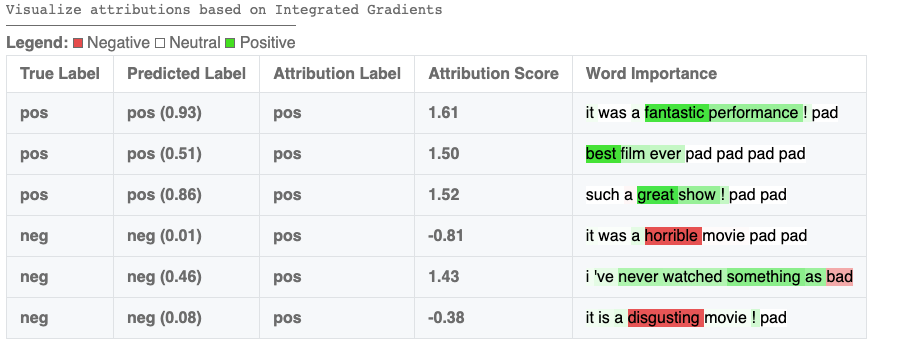
Así es como podemos analizar un modelo de muestra en CIFAR10 a través de Captum Insights:
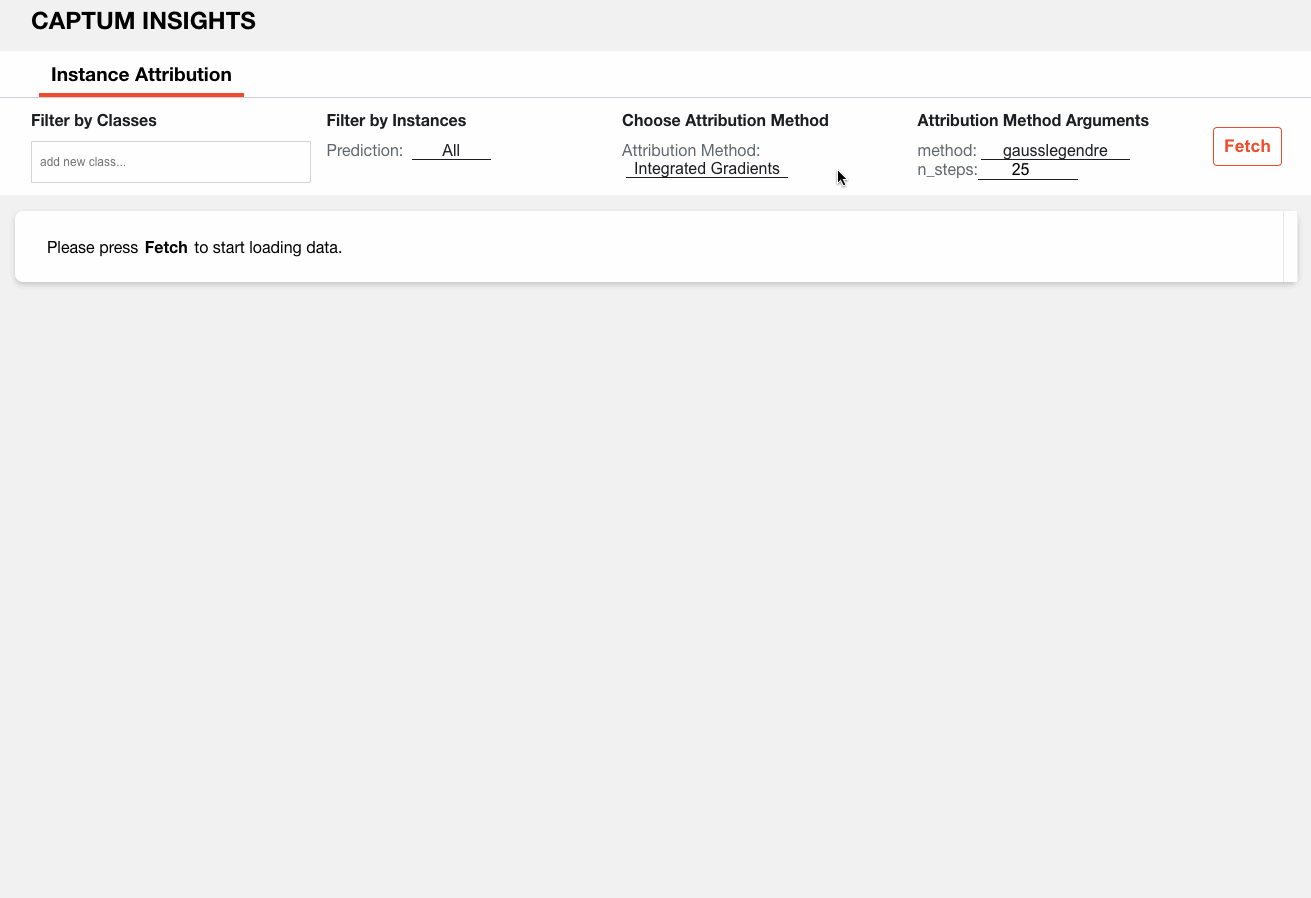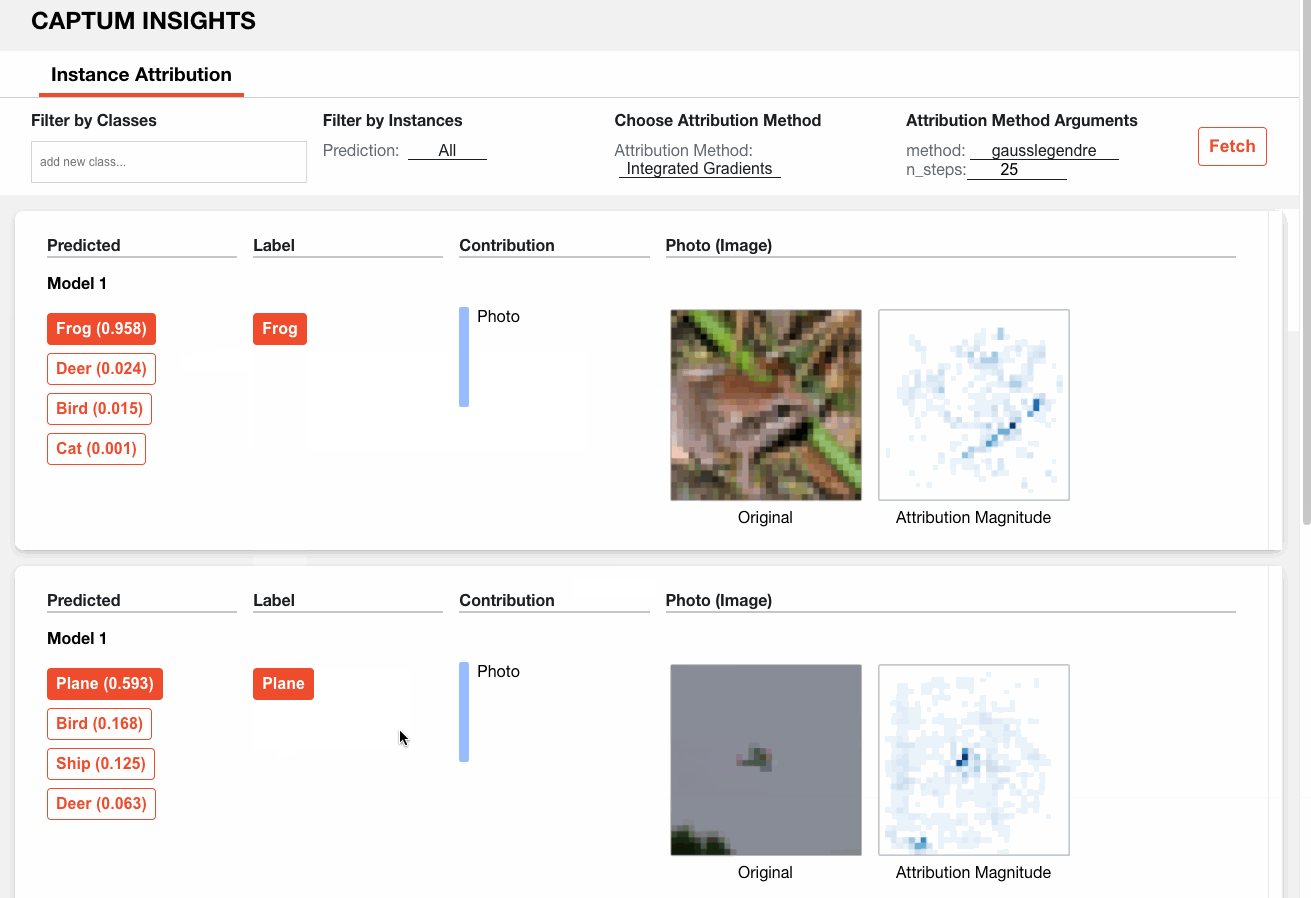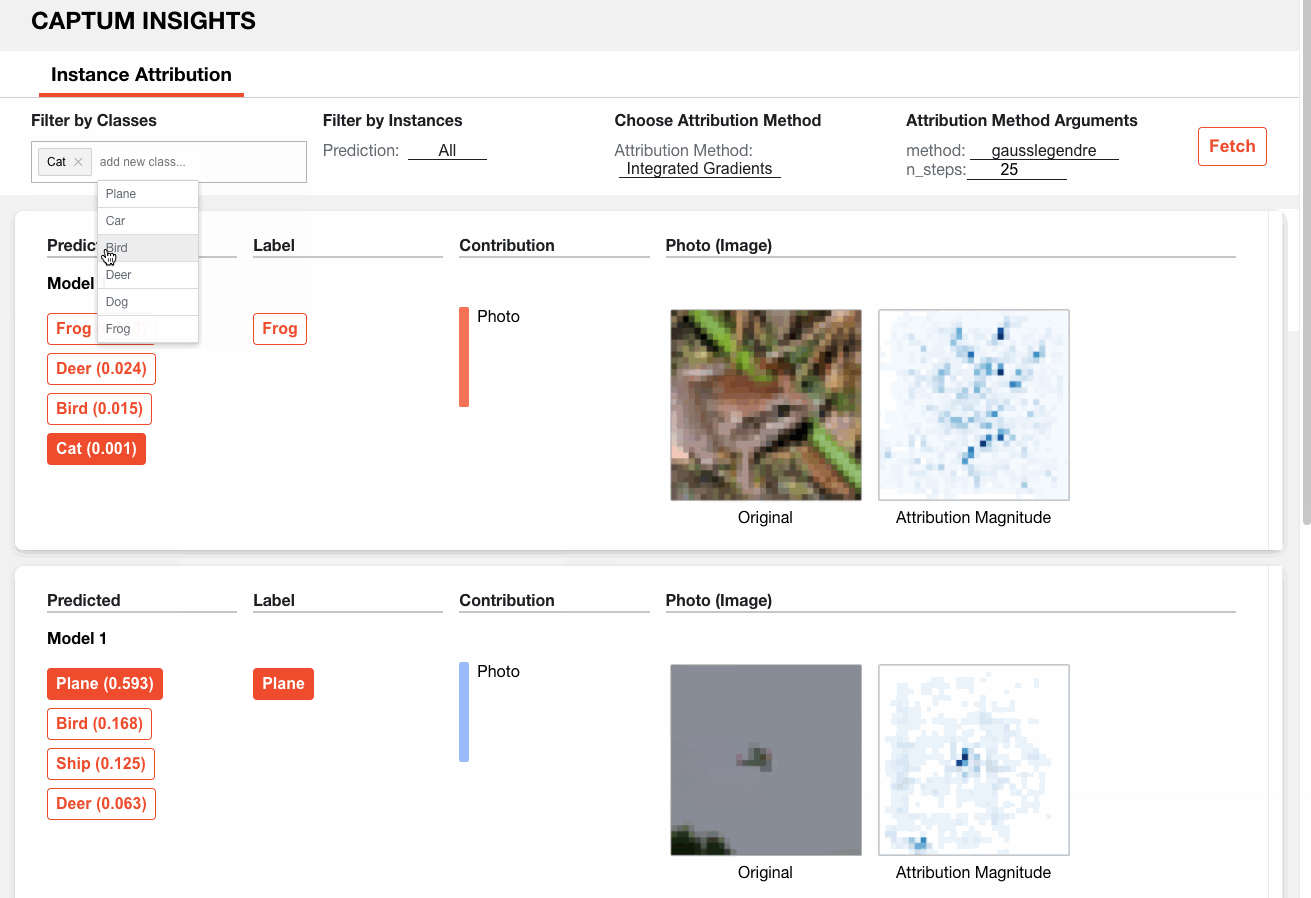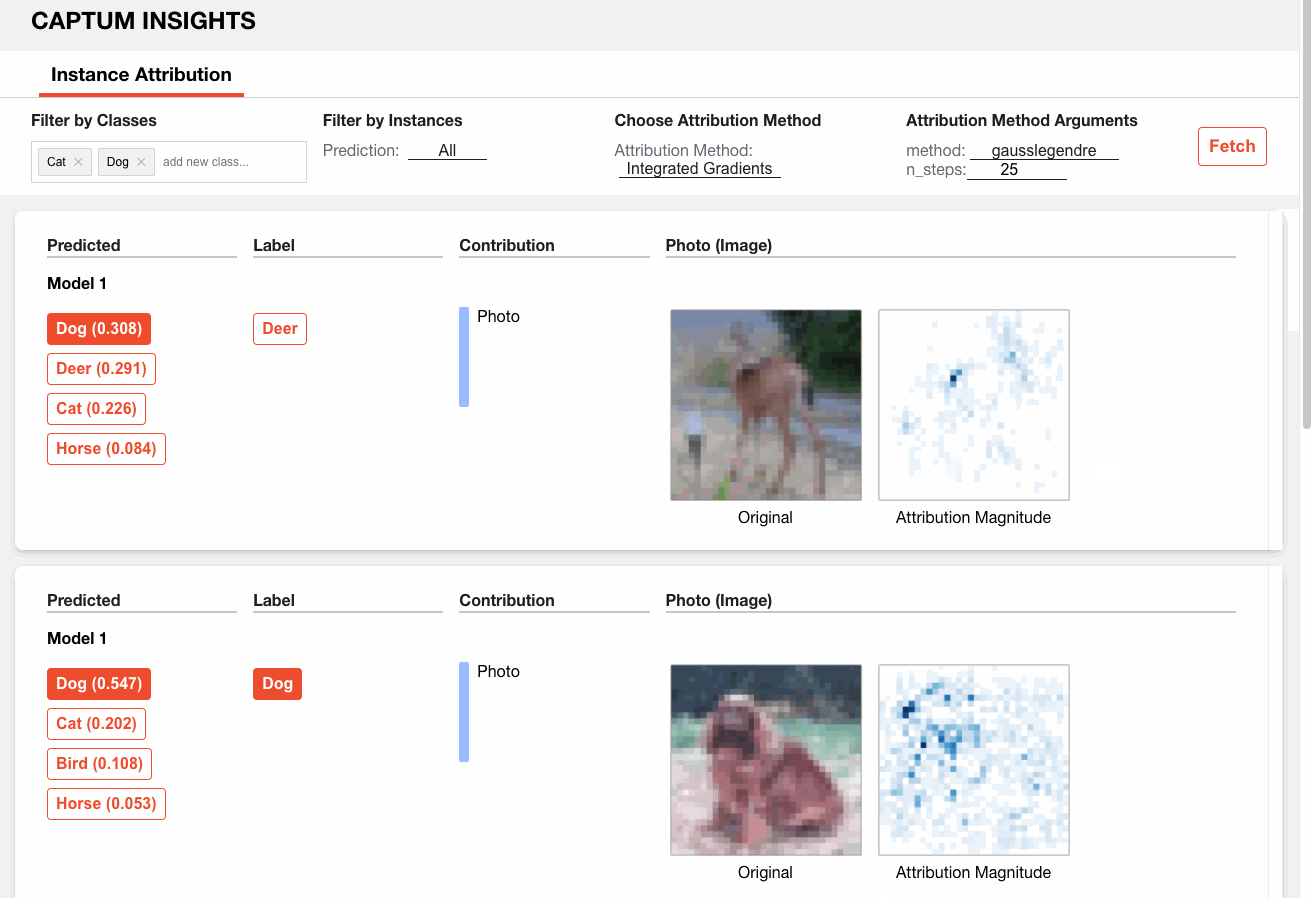
5⃣. Annoy
Molestar es sinónimo de vecinos más cercanos aproximados. Está construido en C ++ pero viene con enlaces en Python, Java, Scala, R y Ruby. Molestar se usa para hacer (aproximadas) consultas de vecinos más cercanos en espacios de alta dimensión. Aunque muchas otras bibliotecas realizan la misma operación, molestar viene con algunos complementos geniales. Crea grandes estructuras de datos basadas en archivos de solo lectura que se mmapean en la memoria para que muchos procesos puedan compartir los mismos datos. Annoy, creado por Erik Bernhardsson, se usa en Spotify para recomendaciones musicales, donde se usa para buscar usuarios / elementos similares.
Tenemos muchos millones de pistas en un espacio de alta dimensión, por lo que el uso de la memoria es una preocupación principal – Spotify
Github
https://github.com/spotify/annoy
Diapositivas
- Presentación de New York Machine Learning meetup sobre Annoy
Demo
Así es cómo podemos usar Molestar para encontrar los 100 vecinos más cercanos.

Resumen
Así que estas fueron las bibliotecas que encontré interesantes, útiles y que valía la pena compartir. Estoy seguro de que te gustaría explorarlas y ver cómo podrías utilizarlos en tu área de trabajo. Aunque ya tenemos innumerables bibliotecas con las que jugar, explorar otras nuevas siempre es divertido y así te aseguras que estás bien informado.
The post Cinco bibliotecas de Machine Learning de código abierto interesantes first appeared on Planeta Chatbot.
]]>The post Automatiza la estructura de tu proyecto de Data Science en 3 sencillos pasos first appeared on Planeta Chatbot.
]]>Good Code es tu mejor documentación
La Dra. Rachael Tatman, en una de sus presentaciones, destacó la importancia de la reproducibilidad del código de una manera muy sutil:
“¿Por qué debería preocuparse por la reproducibilidad? Porque la persona que más probablemente necesitará reproducir su trabajo … es usted «.
Esto es cierto en muchos niveles. ¿Alguna vez te has encontrado en una situación en la que resultaba difícil descifrar tu base de código? ¿Sueles tener varios archivos como untitled1.py o untitled2.ipynb? Bueno, si no todos, algunos de nosotros indudablemente debemos haber enfrentado la peor parte de las malas prácticas de codificación en pocas ocasiones. La situación es aún más común en data science. A menudo, limitamos nuestro enfoque en el análisis y el producto final, ignorando la calidad del código responsable del análisis.
¿Por qué la reproducibilidad es un ingrediente vital en el proceso de data science? He tocado este tema en otra publicación de blog y tomaré prestadas algunas líneas de allí. Un ejemplo reproducible le permite a otra persona recrear su análisis utilizando los mismos datos. Esto tiene mucho sentido, ya que publicas tu trabajo para que lo usen. Este propósito se vence si otros no pueden reproducir tu trabajo. En este artículo, vemos tres herramientas útiles que pueden simplificarlo y ayudarte a crear proyectos estructurados y reproducibles.
Creando una buena estructura de proyecto
Supongamos que deseas crear un proyecto que contenga código para analizar los sentimientos de las reseñas de películas. Hay tres pasos esenciales para crear una buena estructura de proyecto:

1. Automatización de la creación de plantillas de proyectos con Cookiecutter Data Science

No existe un consenso claro en la comunidad sobre las mejores prácticas para organizar proyectos de aprendizaje automático. Por eso hay una plétora de opciones y esta falta de claridad conduce a la confusión. Afortunadamente, hay una solución, gracias a la gente de DrivenData. Han creado una herramienta llamada Cookiecutter Data Science, que es una estructura de proyecto estandarizada pero flexible para hacer y compartir trabajos de data science. Unas pocas líneas de código configuran una serie completa de subdirectorios y facilitan el inicio, la estructura y el intercambio de análisis. Puede leer más sobre la herramienta en la página de inicio de su proyecto. Vayamos a la parte interesante y veamos cómo funciona.
Instalación
pip install cookiecutterorconda config --add channels conda-forge
conda install cookiecutter
Comenzando un nuevo proyecto
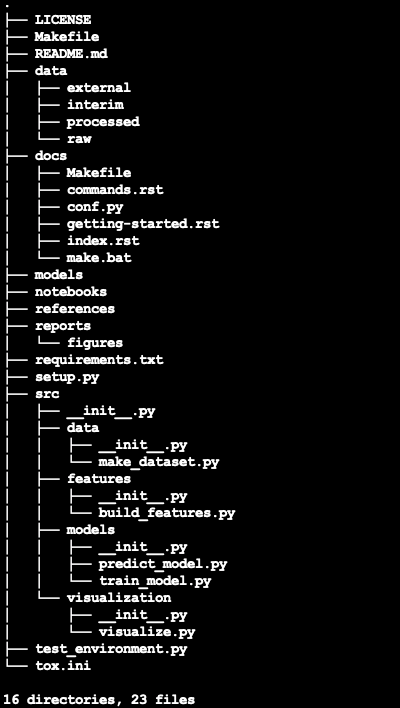
Dirígete a tu terminal y ejecuta el siguiente comando. Completarás automáticamente un directorio con los archivos necesarios.
cookiecutter https://github.com/drivendata/cookiecutter-data-science

Se crea un directorio de análisis de opinión en la ruta especificada, que en el caso anterior es el escritorio.
Nota: La ciencia de datos de Cookiecutter se moverá pronto a la versión 2 y, por lo tanto, habrá un ligero cambio en cómo se usa el comando en el futuro. Esto significa que tendrá que usar ccds … en lugar de cortador de galletas … en el comando anterior. Según el repositorio de Github, esta versión de la plantilla seguirá estando disponible, pero habría que usar explícitamente -c v1 para seleccionarla. Esté atento a la documentación, cuando ocurra el cambio.
Crear un buen archivo Léame con readme.so

Después de crear el esqueleto del proyecto a continuación, debes completarlo. Pero antes de eso, hay un archivo importante que debe actualizarse: el archivo README. Un archivo README es un archivo de rebajas que comunica información esencial sobre tu proyecto. Les dice a otros de qué se trata el proyecto, la licencia del proyecto, cómo otros pueden contribuir al proyecto, etc. He visto a muchas personas que hacen un gran esfuerzo en sus proyectos pero no logran crear archivos READMEs decentes. Si eres uno de ellos, hay buenas noticias en forma de un proyecto llamado readme.so.
Un alma buena acaba de poner fin a la escritura de archivos README manualmente. Katherine Peterson creó recientemente un editor simple que le permite crear y personalizar el archivo Léame de tu proyecto rápidamente.
El editor es bastante intuitivo. Solo necesitas hacer clic en una sección para editar el contenido y la sección se agregará a tu archivo Léame. Elige los que más le gusten de una extensa colección. También puedes mover las secciones dependiendo de la ubicación donde las desee en la página. Una vez que tengas todo en su lugar, continua y copia el contenido o descarga el archivo y agrégalo a tu proyecto existente.
{kind=link}
Envía tu código a Github
Casi terminamos. Lo único que queda es enviar el código a Github (o cualquier plataforma de control de versiones de su elección). Puedes hacerlo fácilmente a través de Git. Aquí hay una práctica hoja de trucos que contiene los comandos de Git más importantes y más utilizados para una fácil referencia.
Alternativamente, si usas Visual Studio Code (VS Code), como yo, ya está resuelto. VS Code hace posible publicar cualquier proyecto directamente en GitHub sin tener que crear un repositorio primero. VS Code creará el repositorio para usted y controlará si debe ser público o privado. Lo único que se requiere por su parte es proporcionar autenticación a GitHub a través de VS Code.
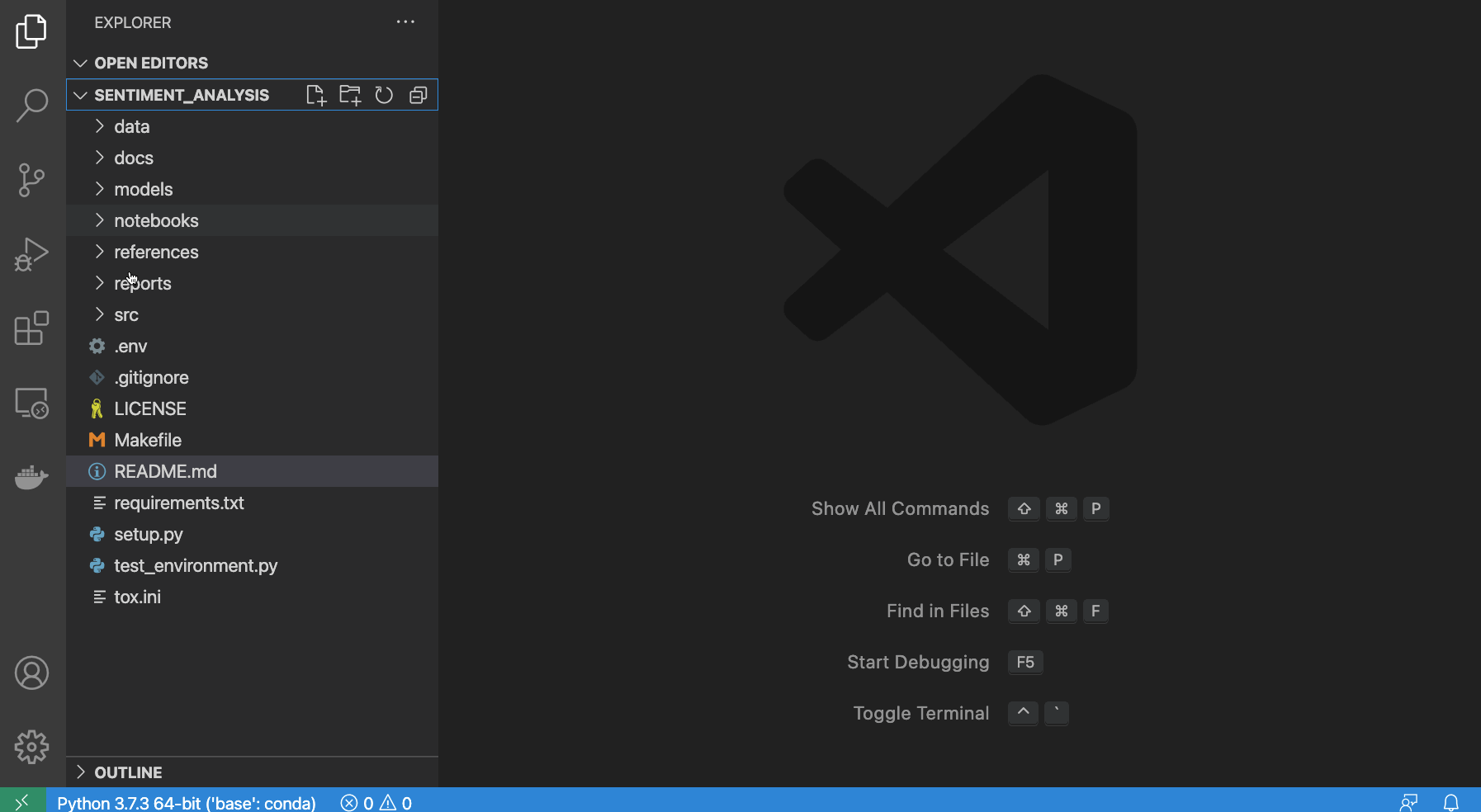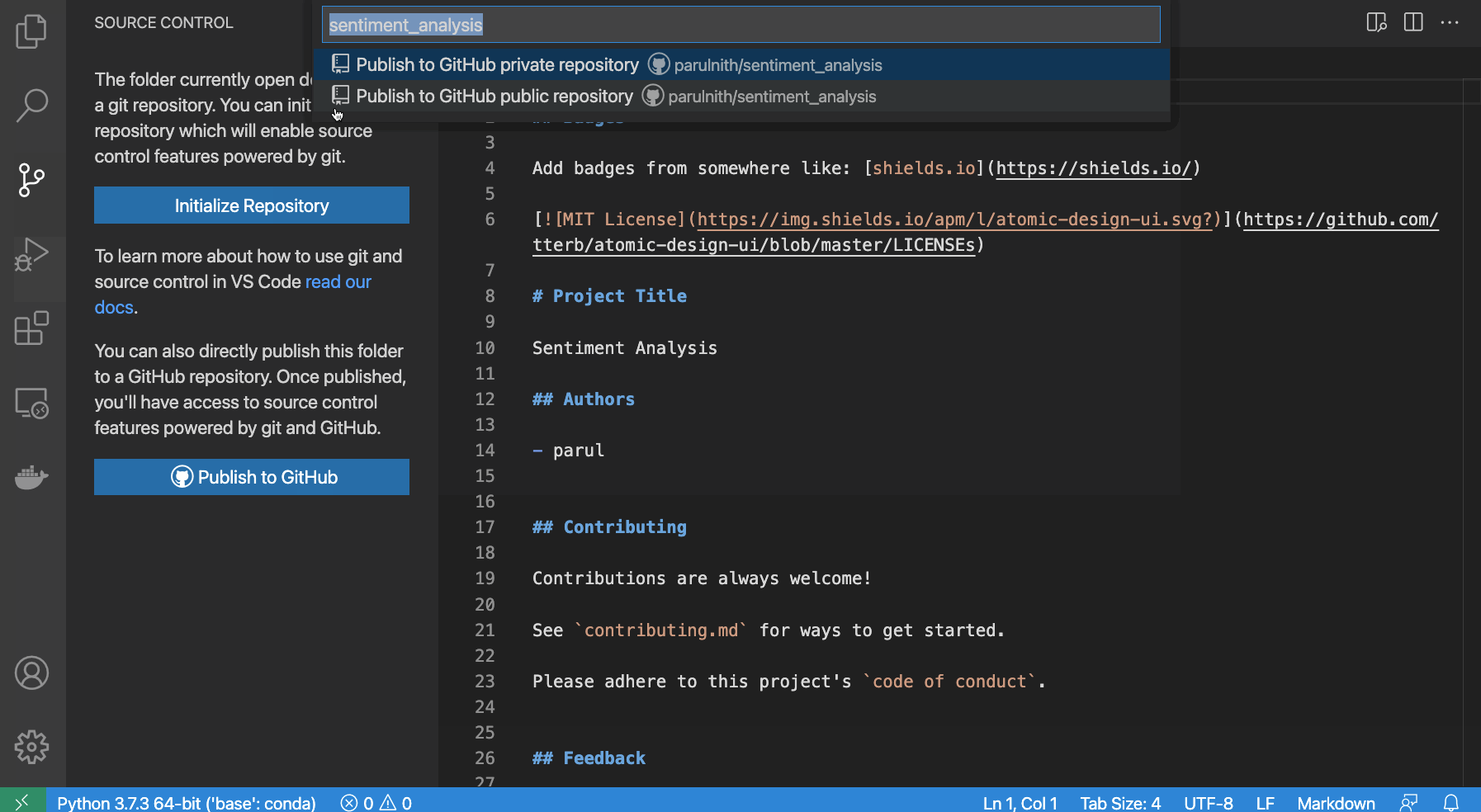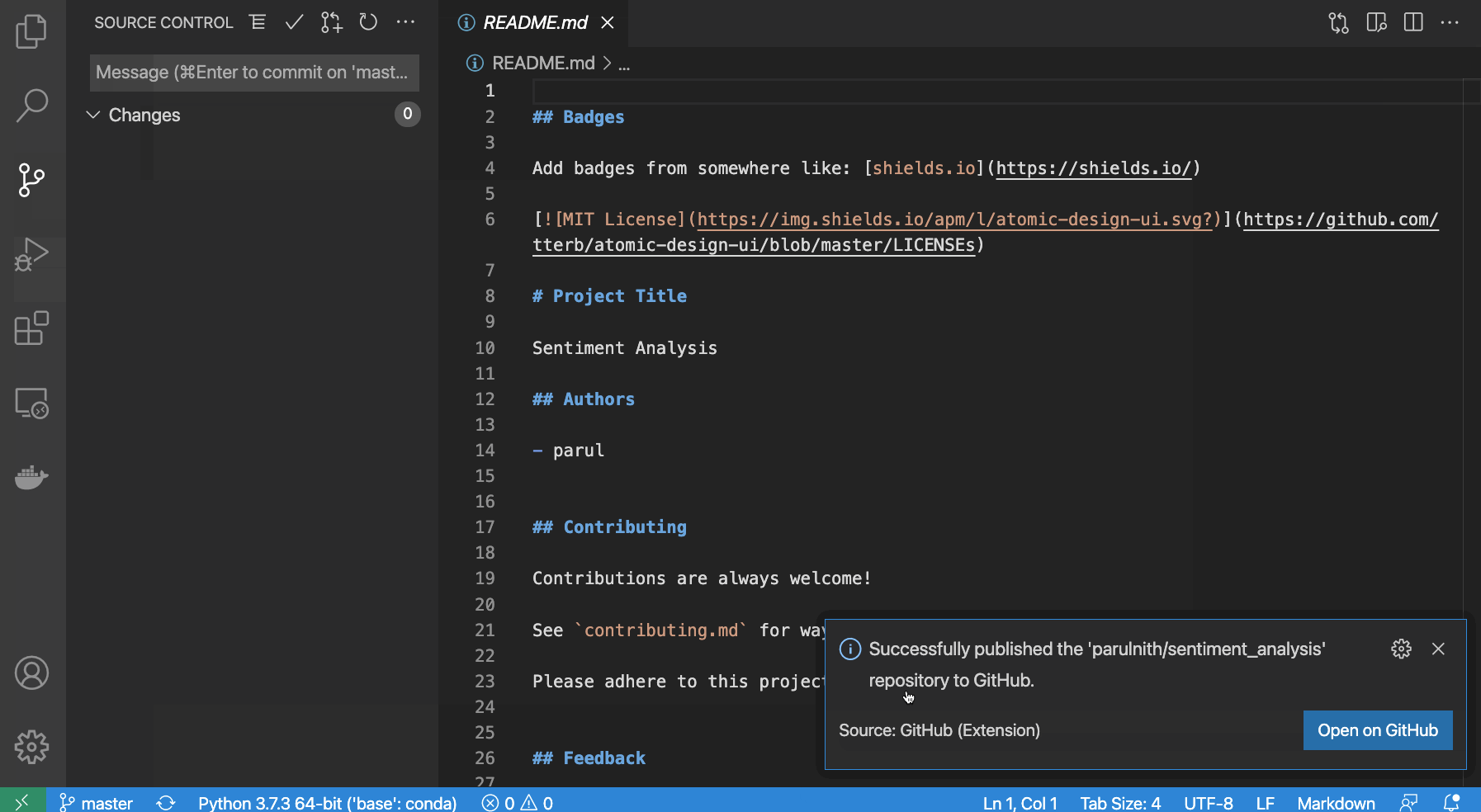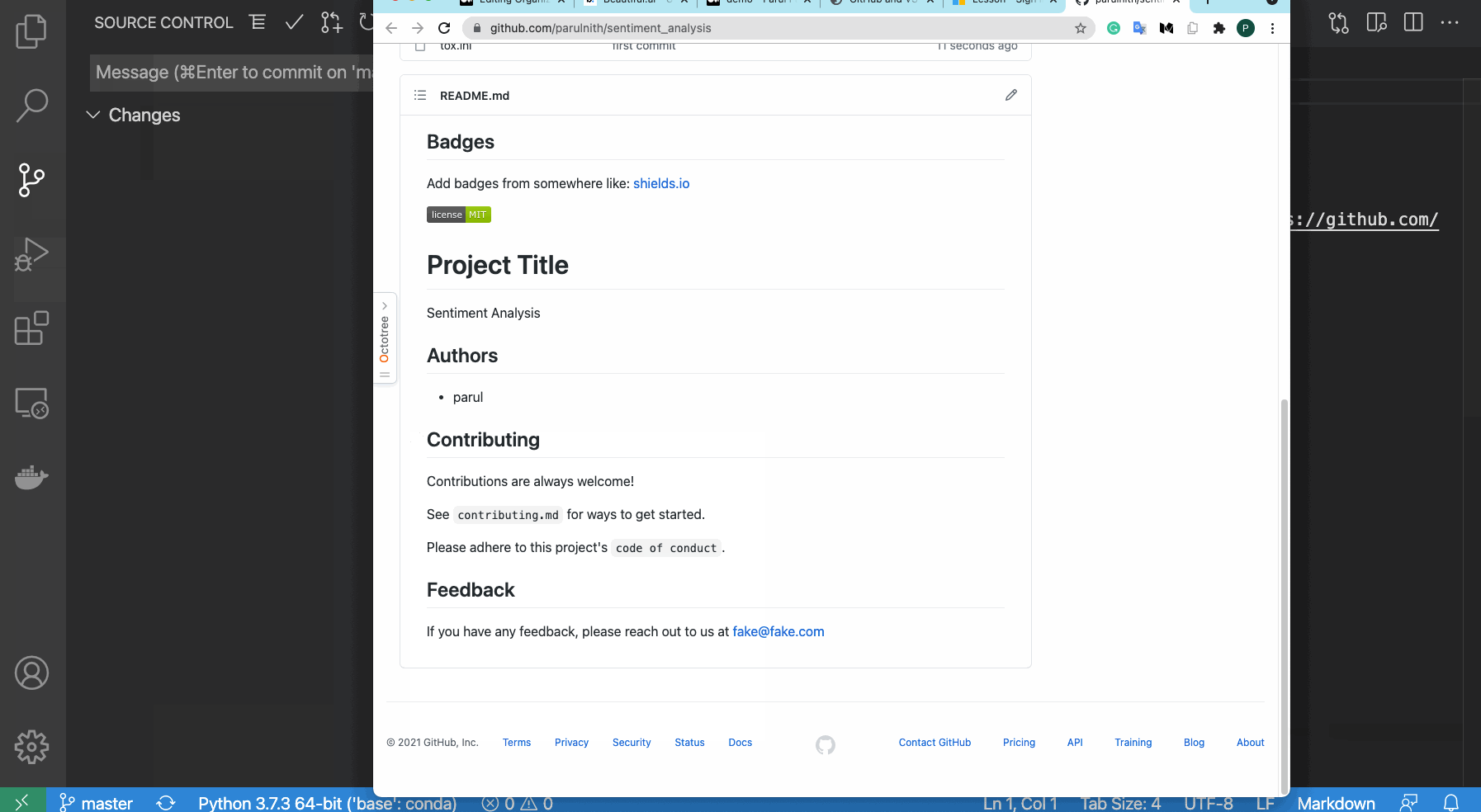{kind=link}
Eso es todo lo que necesitas para configurar una base de proyecto sólida y estructurada. Todos los pasos anteriores se han resumido en el siguiente video en caso de que desees ver todos los pasos en sincronización.
Conclusión
La creación de proyectos estructurados y reproducibles puede parecer difícil al principio, pero ofrece ventajas a largo plazo. En este artículo, analizamos tres herramientas útiles que pueden ayudarnos en esta tarea. Mientras que la ciencia de datos del cortador de cookies proporciona una plantilla de proyecto limpia, readme.so rellena automáticamente un archivo readme. Finalmente, VS Code puede ayudarnos a llevar el proyecto a la web para el control de código fuente y la colaboración. Esto crea la base necesaria para un buen proyecto de ciencia de datos. Ahora puede comenzar a trabajar en sus datos y obtener información de ellos para compartir con varias partes interesadas.
The post Automatiza la estructura de tu proyecto de Data Science en 3 sencillos pasos first appeared on Planeta Chatbot.
]]>The post Inteligencia Artificial para el análisis de sentimientos en textos first appeared on Planeta Chatbot.
]]>“Esta es la mejor funda para portátil de la historia. Es tan buena que en los dos meses que llevo usándola, es digna de ser utilizado como una bolsa de supermercado”.
El sarcasmo innato en la revisión es evidente ya que el usuario no está contento con la calidad de la funda. Sin embargo, como la oración contiene palabras como ‘mejor’, ‘bueno’ y ‘digno’, la crítica puede confundirse fácilmente con una positiva. Es un fenómeno común que dichas críticas humorísticas, aunque crípticas, se vuelvan virales en las redes sociales. Si tales respuestas no se detectan y se actúa sobre ellas, pueden resultar perjudiciales para la reputación de una empresa, especialmente si están planeando realizar un nuevo lanzamiento. La detección del sarcasmo en las revisiones es un caso de uso importante del procesamiento del lenguaje natural, y veremos cómo el aprendizaje automático puede ser de ayuda en este sentido.
Análisis de sentimientos: obtener información vital de datos no estructurados

Antes de entrar en el meollo de la detección del sarcasmo, intentemos tener una visión global del análisis de sentimientos.
El análisis de sentimientos, también conocido como “opinion mining”, es un subcampo del procesamiento del lenguaje natural (PLN) que intenta identificar y extraer opiniones de un texto dado.
Anteriormente, las empresas confiaban en métodos tradicionales como encuestas y estudios de grupos objetivos para obtener los comentarios de los consumidores. Sin embargo, las tecnologías respaldadas por el aprendizaje automático y la inteligencia artificial han permitido analizar texto de una amplia variedad de fuentes con mucha más precisión. No es necesario decir que la capacidad de extraer emociones del texto es una herramienta muy valiosa que tiene el potencial de mejorar el ROI de muchas empresas, de manera espectacular.
Importancia del análisis de sentimientos

Paul Hoffman, el CTO de Space-Time Insight, dijo una vez: “Si deseas comprender a las personas, especialmente a tus clientes … entonces debes ser capaz de poseer una gran capacidad para analizar textos “. No podríamos estar más de acuerdo con Paul, ya que el poder que el análisis de texto brinda a las empresas ha sido bastante evidente en los últimos años. Con un aumento en las actividades de las redes sociales, las emociones son vistas como productos valiosos desde una perspectiva comercial. Al evaluar cuidadosamente la opinión y los sentimientos de las personas, las empresas pueden averiguar razonablemente qué piensan las personas sobre un producto y, en consecuencia, incorporar retroalimentaciones.
Sarcasmo: el sentimiento negativo que usa palabras positivas
El análisis de sentimientos no es una tarea fácil de realizar. Los datos de texto a menudo vienen precargados con mucho ruido. El sarcasmo es uno de esos tipos de ruido presente de forma innata en las redes sociales y las opiniones de productos que pueden interferir con los resultados.
Los textos sarcásticos demuestran un comportamiento único. A diferencia de una simple negación, una oración sarcástica transmite un sentimiento negativo utilizando solo una connotación positiva de las palabras. Aquí hay algunos ejemplos donde el sarcasmo es bastante evidente.

El análisis de sentimientos puede confundirse fácilmente con la presencia de palabras tan sarcásticas y, por lo tanto, la detección de sarcasmo es un paso de preprocesamiento vital en muchas tareas de PLN. Es útil identificar y eliminar las muestras ruidosas antes de entrenar modelos para aplicaciones de PLN.
Detección de sarcasmo Driverless AI (DAI)
Driverless AI es un producto de machine learning deH2O.ai. Viene equipado con guías de procesamiento del lenguaje natural (PLN) para la clasificación de texto y problemas de regresión. La plataforma admite texto independiente y texto con otros valores numéricos como características predictivas. Las siguientes guías y modelos se han implementado en DAI:

La plataforma convierte automáticamente las cadenas de texto en características utilizando técnicas potentes como TFIDF, CNN y GRU. Con TensorFlow, Driverless AI también puedes procesar bloques de texto más grandes y construir modelos utilizando todos los datos disponibles para resolver problemas comerciales. Driverless AI tiene capacidades de PLN de última generación para el análisis de sentimientos, y la utilizaremos para construir un clasificador de detección de sarcasmo.
Conjunto de datos
El conjunto de datos consta de 1.3 millones de comentarios sarcásticos del sitio web de comentarios de Internet Reddit, etiquetados como sarcásticos y no sarcásticos. La fuente del conjunto de datos es un documento titulado: “A Large Self-Annotated Corpus for Sarcasm”. También se puede encontrar una versión procesada del conjunto de datos en Kaggle . Exploremos el conjunto de datos antes de ejecutar los diversos algoritmos de clasificación.
Importando los datos

El conjunto de datos consta de un millón de filas y cada registro consta de diez atributos:

A nosotros nos interesa especialmente dos columnas:
label:0para el comentario sarcásticoy1para el que no lo es.comment: la columna de texto que será usada para llevar a cabo el experimento.
Análisis exploratorio de datos
El conjunto de datos está perfectamente equilibrado, con un número igual de tweets sarcásticos y no sarcásticos.

La distribución de longitudes para comentarios sarcásticos y normales también es casi la misma.


Dado que el conjunto de datos se ha convertido a un formato tabular, está listo para incluirse en Driverless AI. Ten en cuenta que las características de texto se generarán y evaluarán automáticamente durante el proceso de ingeniería de características.
Lanzando el Experimento
Lanzaremos nuestro experimento en tres partes para obtener los mejores resultados posibles.
- Con guías incorporadas TF / IDF NLP
En la primera parte, utilizaremos las capacidades incorporadas TF / IDF de DAI.
En caso de que desees actualizar tus conocimientos sobre cómo comenzar con Driverless AI, no dudes en realizar una Prueba de funcionamiento. La Prueba de funcionamiento es el DriverlessAI de H2O en la nube de AWS, donde puedes explorar todas sus características sin tener que descargarla.
Comienza una nueva instancia de DAI. Luego, divide el conjunto de datos en conjuntos de entrenamiento y prueba en una proporción de 70:30 y unalabel especifica como la columna objetivo. También deseleccionaremos todas las otras columnas y retendremos solo la columna comment n nuestro conjunto de datos. Finalmente, seleccionaLogLoss como anotador manteniendo todos los demás parámetros como predeterminados e inicia el experimento. La pantalla debería quedarse de la siguiente manera:
 Con guías incorporadas TF / IDF NLP
Con guías incorporadas TF / IDF NLP
- Con guías integradas de Tensorflow NPL
Como alternativa, lanzaremos otra instancia del mismo experimento, pero con los modelos Tensorflow. Esto se hace ya que TextCNN se basa en los modelos TensorFlow. Haz click en la pestaña ‘Expert Settings’ y conecta ‘TensorFlow Models’. El resto del proceso sigue siendo el mismo.
 Con guías integradas de Tensorflow NPL
Con guías integradas de Tensorflow NPL
- Con guías de sentimientos personalizados
Si los built-in recipes no son suficientes, puede valer la pena construir nuestro propio recipe centrado en nuestro caso de uso específico. La última versión (1.7.0) de DAI implementa una característica clave llamada BYOR que significa Bring Your Own Recipes . Esta característica ha sido diseñada para permitir que los científicos de datos personalicen el DAI según sus necesidades comerciales. Puedes leer más sobre esta característica aquí .
Para cargar una guía personalizada, ve a la configuración experta y carga la guía deseada. H2O ha creado y abierto más de 80 guías que pueden usarse como plantillas. Se puede acceder a estas guías desde https://github.com/h2oai/driverlessai-recipes . Para este experimento, usaremos la siguiente:
text_sentiment_transformer.pyque extrae el sentimiento del texto usando modelos previamente entrenados de TextBlob.
TextBlob es una biblioteca de Python y ofrece una API simple para acceder a sus métodos y realizar tareas básicas de PLN. Puede realizar muchas tareas de PLN como análisis de sentimientos, revisión ortográfica, creación de resúmenes, traducción, etc. Haz clic en la pestaña expert settings y navega driverlessai-recipes > transformers > nlp y selecciónala (driverlessai-recipes > transformers > nlp). Haz clic en save para guardar la configuración.

A continuación, también puedes seleccionar transformadores específicos y deseleccionar el resto.

Resumen de los resultados del experimento
La siguiente captura de pantalla muestra la comparación entre las tres instancias de DAI con diferentes guías. La inclusión de una guía personalizada redujo el componente Logloss de 0,54 a 0,50, que, cuando se traduce a un dominio comercial, puede tener un valor inmenso.

Una vez que se realiza el experimento, los usuarios pueden hacer nuevas predicciones y descargar la scoring pipeline, como cualquier otro experimento de Driverless AI.
Conclusión
El análisis de sentimientos puede desempeñar un papel crucial en el dominio de marketing. Puede ayudar a crear mensajes de marca específicos y ayudar a una empresa a comprender las preferencias del consumidor. Estas ideas podrían ser críticas para que una empresa aumente su alcance e influencia en una variedad de sectores.
The post Inteligencia Artificial para el análisis de sentimientos en textos first appeared on Planeta Chatbot.
]]>The post Construyendo un Chatbot simple desde cero en Python (usando NLTK) first appeared on Planeta Chatbot.
]]>Gartner estima que para 2020, los chatbots manejarán el 85 por ciento de las interacciones de servicio al cliente; Ya están manejando alrededor del 30 por ciento de las transacciones ahora.
Estoy segura de que has oído hablar de Duolingo : una popular aplicación de aprendizaje de idiomas, que ayuda en el proceso de aprendizaje de un nuevo idioma. Esta herramienta es bastante popular debido a sus sistemas innovadores a la hora de enseñar una nueva lengua. El concepto es simple: de cinco a diez minutos de capacitación interactiva al día es suficiente para aprender un idioma.
Sin embargo, a pesar de que Duolingo está permitiendo que las personas aprendan un nuevo idioma, a los practicantes les preocupa. Las personas sintieron que se estaban perdiendo el aprendizaje de valiosas habilidades de conversación ya que estaban aprendiendo por su cuenta. Las personas también estaban preocupadas por ser emparejadas con otros estudiantes de idiomas debido al miedo a la vergüenza. Esto estaba resultando ser un gran cuello de botella en los planes de Duolingo .
Así que su equipo resolvió este problema mediante la creación de un chatbot nativo dentro de su aplicación, para ayudar a los usuarios a aprender habilidades de conversación y practicar lo que aprendieron.

Dado que los bots están diseñados para ser conversadores y amigables, los estudiantes de Duolingo pueden practicar la conversación a cualquier hora del día, utilizando los personajes que elijan, hasta que se sientan lo suficientemente valientes como para practicar su nuevo idioma con otros speakers. Esto resolvió un pain point para el consumidor e hizo que el aprendizaje a través de la aplicación fuera mucho más divertido.
Entonces, ¿qué es un chatbot?
Un chatbot es una pieza de software con inteligencia artificial en un dispositivo (Siri, Alexa, Google Assistant, etc.), aplicación, sitio web u otras redes que intentan medir las necesidades de los consumidores y luego ayudarlos a realizar una tarea particular como una transacción comercial. Reservas de hoteles, envío de formularios, etc. Hoy en día, casi todas las empresas tienen un chatbot implementado para interactuar con los usuarios. Algunas de las formas en que las empresas están utilizando los chatbots son:
- Para entregar información de vuelo.
- Para conectar a los clientes y sus finanzas.
- Como soporte al cliente.
Las posibilidades son (casi) ilimitadas.
La historia de los chatbots se remonta a 1966, cuando Weizenbaum inventó un programa de computadora llamado ELIZA. Imitaba el lenguaje de un psicoterapeuta desde solo 200 líneas de código. Todavía puedes conversar con él aquí: Eliza.

¿Cómo funcionan los chatbots?
En términos generales, existen dos variantes de chatbots: basadas en reglas y autoaprendizaje.
1. En un enfoque basado en reglas, un bot responde preguntas basadas en algunas reglas que previamente han sido entrenadas. Las reglas definidas pueden ser muy simples o muy complejas. Los bots pueden manejar consultas simples pero fallan en administrar las complejas.
2. Los robots de autoaprendizaje son los que utilizan algunos enfoques basados en el aprendizaje automático y son definitivamente más eficientes que los robots basados en reglas. Estos bots pueden ser de otros dos tipos: basados en recuperación o generativos.
i) En los modelos basados en recuperación , un chatbot utiliza cierta heurística para seleccionar una respuesta de una biblioteca de respuestas predefinidas. El chatbot utiliza el mensaje y el contexto de conversación para seleccionar la mejor respuesta de una lista predefinida de mensajes a dar. El contexto puede incluir una posición actual en el árbol de diálogo, todos los mensajes anteriores en la conversación, variables guardadas previamente (por ejemplo, nombre de usuario). Las heurísticas para seleccionar una respuesta se pueden diseñar de muchas maneras diferentes, desde la lógica condicional en el que se basan las reglas o los clasificadores de aprendizaje automático.
ii) Los bots generativos pueden generar las respuestas y no siempre responden con una de las respuestas de un conjunto de respuestas. Esto los hace más inteligentes a medida que toman palabra por palabra de la consulta y generan las respuestas.
Construyendo el bot
Requisitos previos
Se asume un conocimiento práctico de scikit biblioteca y NLTK. Sin embargo, si eres nuevo en la PNL, aún puedes leer el artículo y luego volver a consultar los recursos.
NLP
El campo de estudio que se centra en las interacciones entre el lenguaje humano y las computadoras se denomina Procesamiento del lenguaje natural, o PNL, para abreviar. Se encuentra en la intersección de la informática, la inteligencia artificial y la lingüística computacional [Wikipedia].
NLP es una forma en que las computadoras analizan, comprenden y derivan el significado del lenguaje humano de una manera inteligente y útil. Al utilizar el PNL, los desarrolladores pueden organizar y estructurar el conocimiento para realizar tareas como el resumen automático, la traducción, el reconocimiento de la entidad nombrada, la extracción de relaciones, el análisis de sentimientos, el reconocimiento de voz y la segmentación de temas.
NLTK: Una breve introducción
NLTK (Natural Language Toolkit) es una plataforma líder para crear programas Python para trabajar con datos en lenguaje humano. Proporciona interfaces fáciles de usar para más de 50 recursos corporales y léxicos , como WordNet, junto con un conjunto de bibliotecas de procesamiento de texto para clasificación, tokenización, derivación, etiquetado, análisis y razonamiento semántico, envoltorios para bibliotecas de PNL de potencia industrial.
NLTK ha sido llamada “una herramienta maravillosa para la enseñanza y el trabajo en lingüística computacional con Python” y “una biblioteca increíble para jugar con lenguaje natural”.
El procesamiento del lenguaje natural con Python proporciona una introducción práctica a la programación para el procesamiento del lenguaje. Recomiendo este libro a las personas que comienzan en PNL con Python.
Descargando e instalando NLTK
- Instalar NLTK: ejecutar
pip install nltk - Instalación de prueba: ejecutar y pythonluego escribir
import nltk
Para obtener instrucciones específicas de la plataforma, pues acudir a este enlace aquí .
Instalación de paquetes NLTK
Importar NLTK y ejecutar nltk.download().Esto abrirá el descargador de NLTK desde donde puedes elegir los corpus y modelos para descargar. También puedes descargar todos los paquetes a la vez.
Preprocesamiento de texto con NLTK
El problema principal con los datos de texto es que todo está en formato de texto (cadenas). Sin embargo, los algoritmos de aprendizaje automático necesitan algún tipo de vector de características numéricas para realizar la tarea. Entonces, antes de comenzar con cualquier proyecto de PNL, debemos preprocesarlo para que sea ideal para trabajar. El preprocesamiento de texto básico incluye:
- Convertir todo el texto en mayúsculas o minúsculas , para que el algoritmo no trate las mismas palabras en diferentes casos como diferentes.
- Tokenización : Tokenización es solo el término usado para describir el proceso de conversión de las cadenas de texto normales en una lista de tokens, es decir, las palabras que realmente queremos. El tokenizador de oraciones se puede usar para encontrar la lista de oraciones y el tokenizador de palabras se puede usar para encontrar la lista de palabras en cadenas.
El paquete de datos NLTK incluye un tokenizer Punkt previamente entrenado para el inglés.
- Eliminar ruido, es decir, todo lo que no esté en un número o letra estándar.
- Eliminando las Stop words. A veces, algunas palabras extremadamente comunes que parecen tener poco valor para ayudar a seleccionar documentos que coinciden con las necesidades de un usuario se excluyen por completo del vocabulario. Estas palabras se llaman Stop words.
- Generación de derivaciones: derivación es el proceso de reducir las palabras con inflexión (o algunas veces derivadas) a su forma de raíz, base o raíz, generalmente una forma de palabra escrita. Ejemplo si tuviéramos que detener las siguientes palabras: “Pan” “panadero, “y panaderia”, el resultado sería una sola palabra “pan”.
- Lemmatización: una ligera variante de la derivación es la lematización. La principal diferencia entre estos es que, la derivación a menudo puede crear palabras inexistentes, mientras que los lemas son palabras reales. Por lo tanto, su raíz, es decir, la palabra con la que termina, no es algo que pueda buscar en un diccionario, pero sí puede buscar un lema. Algunos ejemplos de Lemmatización son que “correr” es una forma básica de palabras como “ccorriendo” o “corrió” o que la palabra “mejor” y “bueno” están en el mismo lema, por lo que se consideran iguales.
Bag of Words
Después de la fase de preprocesamiento inicial, necesitamos transformar el texto en un vector significativo (o matriz) de números. La bolsa de palabras es una representación de texto que describe la aparición de palabras dentro de un documento. Se trata de dos cosas:
- Un vocabulario de palabras conocidas.
- Una medida de la presencia de palabras conocidas.
¿Por qué se llama una “bag” of words? Esto se debe a que cualquier información sobre el orden o la estructura de las palabras en el documento se descarta y al modelo solo le preocupa si las palabras conocidas aparecen en el documento, no donde aparecen en el documento.
La intuición detrás de esta Bolsa de palabras es que los documentos son similares si tienen un contenido similar. Además, podemos aprender algo sobre el significado del documento solo a partir de su contenido.
Por ejemplo, si nuestro diccionario contiene las palabras {Learning, is, the, not, great}, y queremos vectorizar el texto “Learning is great”, tendríamos el siguiente vector: (1, 1, 0, 0, 1).
Enfoque TF-IDF
Un problema con el enfoque de la Bolsa de Palabras es que las palabras muy frecuentes comienzan a dominar en el documento (por ejemplo, mayor puntuación), pero es posible que no contengan tanto “contenido informativo”. Además, dará más peso a los documentos más largos que a los más cortos.
Un enfoque es volver a escalar la frecuencia de las palabras según la frecuencia con la que aparecen en todos los documentos, de manera que se penalicen las puntuaciones de las palabras frecuentes como “the” que también son frecuentes en todos los documentos. Este enfoque de puntuación se denomina Frecuencia de documentos de frecuencia inversa a término , o TF-IDF para abreviar, donde:
Frecuencia de término : es una puntuación de la frecuencia de la palabra en el documento actual.
TF = (Number of times term t appears in a document)/(Number of terms in the document)
Frecuencia de documentos inversa : es una puntuación de cuán rara es la palabra entre los documentos.
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.
El peso de Tf-idf es un peso que se usa a menudo en la recuperación de información y la minería de texto. Este peso es una medida estadística que se utiliza para evaluar la importancia de una palabra para un documento de una colección o un corpus.
Ejemplo:
Considera un documento que contiene 100 palabras en donde la palabra “teléfono” aparece 5 veces.
El término frecuencia (es decir, tf) para teléfono es entonces (5/100) = 0.05. Ahora, supongamos que tenemos 10 millones de documentos y la palabra teléfono aparece en mil de estos. Luego, la frecuencia del documento inverso (es decir, IDF) se calcula como log (10,000,000 / 1,000) = 4. Por lo tanto, el peso de Tf-IDF es el producto de estas cantidades: 0.05 * 4 = 0.20.
Tf-IDF puede implementarse en scikit learn como:
desde sklearn.feature_extraction.text import TfidfVectorizer
Similitud coseno
TF-IDF es una transformación aplicada a los textos para obtener dos vectores de valor real en el espacio vectorial. Luego podemos obtener la similitud de coseno de cualquier par de vectores tomando su producto puntual y dividiéndolo por el producto de sus normas. Eso produce el coseno del ángulo entre los vectores. La similitud de coseno es una medida de similitud entre dos vectores distintos de cero. Usando esta fórmula podemos descubrir la similitud entre dos documentos d1 y d2.
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
Donde d1, d2 son dos vectores que no son cero.
Para una explicación detallada y un ejemplo práctico de TF-IDF y Cosine Similarity, consulta el documento a continuación.
Tf-Idf and Cosine similarity
In the year 1998 Google handled 9800 average search queries every day. In 2012 this number shot up to 5.13 billion…
janav.wordpress.com
Ahora tenemos una idea clara del proceso de la PNL. Es hora de que lleguemos a nuestra tarea real, es decir, la creación de nuestro chatbot. Llamaremos a nuestro chatbot ‘ROBO ’.
’.
Importando las librerías necesarias.
import nltk import numpy as np import random import string # to process standard python strings
Cuerpo
Para nuestro ejemplo, usaremos la página de Wikipedia para chatbots como nuestro corpus. Copia el contenido de la página y colócalo en un archivo de texto llamado ‘chatbot.txt’. Si lo prefieres, puedes utilizar otro corpus.
Leyendo en los datos
Leeremos en el archivo corpus.txt y convertiremos el corpus completo en una lista de oraciones y una lista de palabras para un procesamiento previo adicional.
f=open('chatbot.txt','r',errors = 'ignore')raw=f.read()raw=raw.lower()# converts to lowercasenltk.download('punkt') # first-time use only
nltk.download('wordnet') # first-time use onlysent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences
word_tokens = nltk.word_tokenize(raw)# converts to list of words
Veamos un ejemplo de sent_tokens y word_tokens
sent_tokens[:2]
['a chatbot (also known as a talkbot, chatterbot, bot, im bot, interactive agent, or artificial conversational entity) is a computer program or an artificial intelligence which
conducts a conversation via auditory or textual methods.',
'such programs are often designed to convincingly simulate how a human would behave as a conversational partner, thereby passing the turing test.']
word_tokens[:2]
['a', 'chatbot', '(', 'also', 'known']
Pre-procesamiento del texto crudo
Ahora definiremos una función llamada LemTokens que tomará como entrada los tokens y devolverá tokens normalizados.
lemmer = nltk.stem.WordNetLemmatizer() #WordNet is a semantically-oriented dictionary of English included in NLTK.def LemTokens(tokens): return [lemmer.lemmatize(token) for token in tokens] remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation) def LemNormalize(text): return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
Coincidencia de palabras clave
A continuación, definiremos una función para un saludo a través el bot, es decir, si la entrada de un usuario es un saludo, el bot devolverá una respuesta de saludo. ELIZA usa una palabra clave simple que coincide con los saludos. Utilizaremos el mismo concepto aquí.
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)
GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
Generando respuestas
Para generar una respuesta de nuestro bot para preguntas de entrada, se utilizará el concepto de similitud de documentos. Entonces comenzamos importando los módulos necesarios.
- Desde la biblioteca scikit learn, importa el vectorizador TFidf para convertir una colección de documentos en bruto en una matriz de características TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
- Además, importa el módulo de similitud de coseno desde la biblioteca de aprendizaje de scikit
from sklearn.metrics.pairwise import cosine_similarity
Esto se usará para encontrar la similitud entre las palabras ingresadas por el usuario y las palabras en el corpus. Esta es la implementación más simple posible de un chatbot.
Definimos una respuesta de función que busca la expresión del usuario para una o más palabras clave conocidas y devuelve una de las varias repsuestas posibles. Si no encuentra la entrada que coincide con ninguna de las palabras clave, devuelve una respuesta: “¡Lo siento! No te entiendo.
def response(user_response): robo_response='' sent_tokens.append(user_response)TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english') tfidf = TfidfVec.fit_transform(sent_tokens) vals = cosine_similarity(tfidf[-1], tfidf) idx=vals.argsort()[0][-2] flat = vals.flatten() flat.sort() req_tfidf = flat[-2]if(req_tfidf==0): robo_response=robo_response+"I am sorry! I don't understand you" return robo_response else: robo_response = robo_response+sent_tokens[idx] return robo_response
Finalmente, alimentaremos las líneas que queremos que diga nuestro robot al iniciar y finalizar una conversación, según la información del usuario.
flag=True
print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!")while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("ROBO: You are welcome..")
else:
if(greeting(user_response)!=None):
print("ROBO: "+greeting(user_response))
else:
print("ROBO: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("ROBO: Bye! take care..")
Y eso es todo. Tenemos el codificado de nuestro primer chatbot en NLTK. Puedes encontrar el código completo con el corpus aquí . Ahora, veamos cómo interactúa con los humanos:

Esto no fue tan malo como parece. Incluso aunque el chatbot no pudo dar una respuesta satisfactoria a algunas preguntas, hizo un trabajo excelente en otras.
Conclusión
Aunque es un bot muy simple con casi ninguna habilidad cognitiva, es una buena manera de entrar en la PNL y aprender sobre los chatbots. Aunque ‘ROBO’ responde a las sugerencias del usuario. No engañará a sus amigos y, para un sistema de producción, querrá considerar una de las plataformas o marcos de bots existentes, pero este ejemplo lo ayudará a pensar en el diseño y el desafío de crear un chatbot. Internet está inundado de recursos. y después de leer este artículo, estoy seguro de que desearás crear un chatbot propio.
Espero que hayas encontrado útil este artículo. Déjame saber si tienes alguna duda o sugerencia en la sección de comentarios que verás a continuación.
The post Construyendo un Chatbot simple desde cero en Python (usando NLTK) first appeared on Planeta Chatbot.
]]>The post Construyendo un Chatbot conversacional para Slack usando Rasa y Python – Parte 2 first appeared on Planeta Chatbot.
]]>“Slack volvió a caer, así que los colegas tuvieron que hablar entre ellos”.
Cuando el uso de Slack disminuyó momentáneamente a mediados de 2018, todo el mundo tecnológico había caído en el caos y la depresión. Internet se inundó de discusiones sobre la app y hashtag #Slack estaba siendo tendencia en Twitter. Bueno, Slack ya se ha convertido en una parte integral de muchas compañías y la gente lo usa mucho para comunicarse y discutir cosas. Algunas empresas que trabajan de forma remota utilizan Slack todo el tiempo para la comunicación en tiempo real.
Donde nos fuimos
Esta es la parte final del primer artículo. En la primera parte, discutimos en detalle sobre Rasa Stack: un kit de herramientas de aprendizaje de código abierto que permite a los desarrolladores expandir los bots más allá de responder preguntas simples. Luego utilizamos dos módulos de Rasa, a saber, Rasa NLU y Rasa Core para crear un chatbot completamente funcional capaz de controlar el estado de ánimo de las personas y tomar las medidas necesarias para animarlos. Las acciones incluyeron mostrar a los usuarios la imagen de un perro, gato o ave dependiendo de la elección del usuario.
Objetivo
En este artículo, utilizaremos todos los archivos generados para implementar el Bot en Slack. Te recomiendo que leas la Parte 1 antes de intentar continuar con la segunda parte.
Instalaciones Rasa
- A diferencia de la parte anterior, tendremos que instalar la última versión de Rasa Core. Es muy recomendable que crees un entorno virtual y luego procedas con las instalaciones.
#creating a virtual environment conda create --name bot python=3.6#Activate the new environment to use itWINDOWS: activate bot LINUX, macOS: source activate bot#Install latest Rasa stack #Rasa NLU python m pip install rasa_nlu[spacy] (https://rasa.com/docs/nlu/installation/)#Rasa Core python m pip install -U rasa_core (https://rasa.com/docs/core/installation/)#Language Modelpython -m spacy download en_core_web_md python -m spacy link en_core_web_md en --force;
- Clona mi repositorio GitHub .
El repositorio contiene los archivos generados en la Parte 1. Sin embargo, debido a algunos cambios en las versiones de Rasa API wrt, hay algunos cambios en las funciones y comandos.
Ajustes
Vamos a crear una integración de Slack creando una aplicación de Slack. Vayamos por el proceso de crear una aplicación Slack.
- Crea una cuenta de Slack y ves a https://api.slack.com/. Ahora elige un lugar de trabajo de Slack de desarrollo existente (en caso de que tenga uno) o crea uno nuevo. Nómbralo como DemoWorkplace o como quieras.

DemoWorkplace creation
Creación de lugares de trabajo:
- Ahora crea una aplicación Slack en DemoWorkplace y dale un nombre. Llamemos a nuestra aplicación Robo .
- Comienza a agregar características y funcionalidades a la aplicación. Primero crearemos a bot user debajo de Bot tab y lo integraremos en la aplicación. Esto hará que la aplicación sea conversacional. Dado que este bot se creará como usuario, podemos optar por mantenerlo constantemente en línea. Guarda todos los cambios realizados: bot user Bots Tab.
- Para asegurarte de que el bot se ha integrado, navega hasta la parte Add Features and Functionalityinferior Basic Information Taby y asegúrate de que las pestañas Botsy Permissions están activas. Nuestro bot se ha integrado en la aplicación.
- A continuación, podemos agregar un poco más de información sobre nuestro bot, incluida una imagen, una descripción y un color de fondo. Desplázate Display Information y agrega la información.
- Guarda todos los cambios a medida que avanzas.
- Por último, necesitamos instalar esta aplicación en nuestro lugar de trabajo que definimos anteriormente. Autorízalo y tenemos nuestra aplicación lista e integrada en el lugar de trabajo.
El proceso se ha resumido en el siguiente gif.

Adding Robo App to the DemoWorkplace
Ngrok
Ngrok es un software de proxy inverso para túneles multiplataforma que establece túneles seguros desde un punto final público como Internet a un servicio de red que se ejecuta localmente. En palabras simples, significa que abre el acceso a tu aplicación local desde Internet.
- Descarga ngrok desde aquí . asegúrese de iniciar sesión primero.
- Descomprimir para instalar a través de $ unzip /path/to/ngrok.zip
- Conecta tu cuenta a través de $ ./ngrok <authtoken>
Navega hasta el directorio donde descomprimiste Ngrok y escribe $ ngrok <authtoken> en la consola. Se puede acceder al token desde aquí .
- Actívalo.
Comienza diciéndole qué puerto queremos exponer al internet público: ./ngrok http 5004
Si todo va bien deberías ver la siguiente pantalla:

Aquí http://——-.ngrok.io es la url de ngrok.
Desplegando el Bot en Slack
- Crear una secuencia de comandos de Python
Ya que hemos terminado con todos los requisitos, es hora de implementar nuestro bot. Para esto, tendremos que escribir un script de Python llamado run_app.py, que integrará nuestro chatbot con la aplicación de Slack que creamos anteriormente. Comenzaremos creando un conector de Slack para nuestro chatbot Rasa. Usaremos el intérprete RasaNLU para cargar el modelo NLU directamente desde el script de python.
Volveremos a entrenar a nuestro modelo para asegurarnos de que todo esté bien y funcionando.
Entrenando el Modelo NLU
python nlu_model.py
Entrenando el modelo básico de Rasa
El archivo de acciones que creamos en la Parte 1, ahora debe ejecutarse en un servidor separado. Este es un cambio en la última versión de Rasa Core. Lee la documentación para más detalles.
-
- Iniciar el servidor de acciones personalizadas.
python -m rasa_core_sdk.endpoint --actions actions
-
- Abre una nueva terminal y entrena el modelo Rasa Core.
python dialogue_management_model.py
-
- Inicia el agente ejecutando el run_app.py archivo. Asegúrate de proporcionar el token de Slack en el script. La ficha de Slack se puede obtener de la siguiente manera.

-
- Inicia el ngrok en el puerto 5004 y toma tu ngrok_url.
- Proporciona la url: https: // <your_ngrok_url> / webhooks / slack / webhook en la página “Suscripciones de eventos” de la configuración de Slack. Espera a que seas verificado.

-
- Por último, subscribe to some Workplace events como.
app_mention para que nuestro bot responda cuando alguien lo menciona por su nombre.
message_im que permite al usuario enviar mensajes directos al bot.

-
- Asegúrate de guardar todos los cambios a medida que avanzas.
Hablemos
- Asegúrate de que el servidor de acciones personalizadas se está ejecutando.
- Asegúrate de que ngrok se esté ejecutando en el puerto 5004.
- Navega a la interfaz de Slack y habla con tu bot.
Esto puede sonar como una tarea hercúlea, pero si lo sigues paso a paso, finalmente podrás crear un slackbot en funcionamiento llamado Robo en muy poco tiempo. Podrás chatear con tu bot, al igual que yo:

Conclusión
Este fue un tutorial bastante completo y largo, pero el hecho de que pudiéramos crear una función completa de Slackbot hace que todo el trabajo valga la pena. Rasa es una biblioteca bastante útil y puedes experimentar y jugar con ella para crear algunos chatbots realmente útiles.
The post Construyendo un Chatbot conversacional para Slack usando Rasa y Python – Parte 2 first appeared on Planeta Chatbot.
]]>The post Construyendo un Chatbot conversacional para Slack usando Rasa y Python – Parte 1 first appeared on Planeta Chatbot.
]]>Es hora de ir más allá de acabar con los chatbot del tipo “Lo siento, no entendí tu pregunta” y construir asistentes de IA que escalan utilizando el aprendizaje automático: Rasa
Los sistemas conversacionales de inteligencia artificial se están convirtiendo en una parte indispensable del ecosistema humano. Entre los ejemplos más conocidos de AI conversacional se incluyen Siri de Apple, Alexa de Amazon y Cortana de Microsoft. Los chatbots conversacionales han recorrido un largo camino desde sus predecesores basados en reglas y casi todas las empresas de tecnología emplean hoy a uno o más ade estos asistentes.
Una conversación con un chatbot comprende el contexto de la conversación y puede manejar cualquier objetivo del usuario con gracia y ayudarle a lograrlo de la mejor manera posible. Esto no siempre significa que el bot podrá responder todas las preguntas, pero puede manejar bien la conversación.
Objetivo
En este artículo, vamos a construir un chatbot llamado ‘Robo’ capaz de controlar el estado de ánimo de las personas y tomar las medidas necesarias para animarlos. Luego lo desplegaremos en Slack. Será un Slackbot totalmente funcional capaz de escuchar y responder a tus solicitudes. La siguiente captura de pantalla de demostración debe motivarte lo suficiente como para construir la tuya propia.
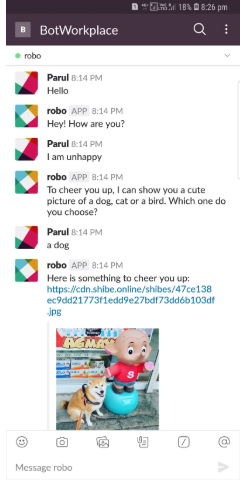
La fuente de este artículo es una maravillosa charla que Tom Bocklisch, Jefe de Ingeniería @ Rasa dio en Pydata Berlin.
Requerimientos
Principalmente requerimos la instalación de Rasa Stack y un modelo de idioma. El modelo de idioma se utilizará para analizar los mensajes de texto entrantes y extraer la información necesaria. Estaremos trabajando con el modelo de lenguaje SpaCy .
Pila de Rasa
Rasa Stack es un conjunto de herramientas de aprendizaje automático de código abierto para que los desarrolladores creen asistentes contextuales de AI y chatbots. Es el kit de herramientas de aprendizaje automático de código abierto que permite a los desarrolladores expandir los bots más allá de responder preguntas simples con un mínimo de datos de capacitación. Los robots se basan en un modelo de aprendizaje automático formado en conversaciones de ejemplo. Se compone de dos marcos:
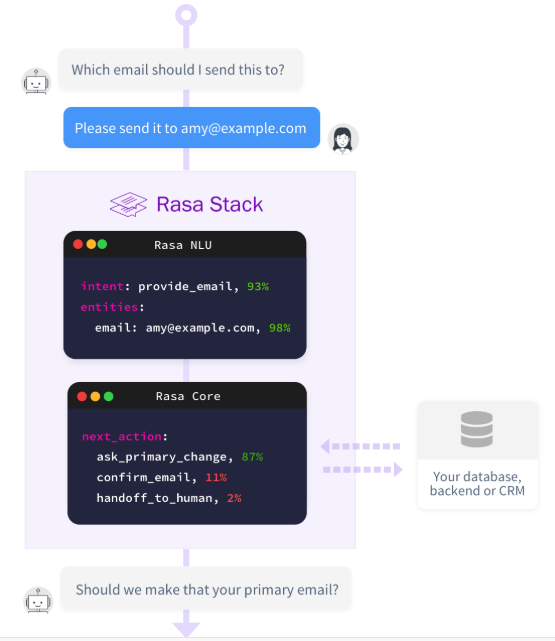
Rasa NLU: una biblioteca para la comprensión del lenguaje natural con clasificación de intención y extracción de entidades. Esto ayuda al chatbot a entender lo que el usuario está diciendo.
Rasa Core: un marco de chatbot con gestión de diálogos basada en el aprendizaje automático que predice la siguiente mejor acción basada en la entrada de NLU, el historial de conversaciones y los datos de entrenamiento.
Rasa tiene una gran documentación que incluye algunos ejemplos interactivos para comprender fácilmente cada uno de los grupos.
Instalaciones
Usaremos el cuaderno Jupyter para ejecutar el código. Sin embargo, recomendaría usar el Colaboratory de Google, ya que no requiere ninguna configuración y el código se ejecuta en una máquina virtual dedicada a tu cuenta. El único inconveniente es que las máquinas virtuales se reciclan cuando están inactivas por un tiempo y tienen una vida útil máxima impuesta por el sistema.
Instalaciones primarias
Necesitarás una NLU Rasa, Rasa Core y un modelo de lenguaje de spaCy.
#Rasa NLU python m pip install rasa_nlu[spacy] (https://rasa.com/docs/nlu/installation/)#Rasa Core python m pip install -U rasa_core == 0.9.6 (https://rasa.com/docs/core/installation/)#Language Modelpython -m spacy download en_core_web_md python -m spacy link en_core_web_md en --force;
La versión Rasa Core utilizada en este artículo no es la más reciente. Trabajar con el último generó errores al ejecutar el código, así que tuve que trabajar con la versión anterior. Actualmente estoy trabajando para que el código se ejecute en la última versión.
Instalaremos las otras dependencias según tus requerimientos.
1. Enseñar al bot a comprender las entradas del usuario utilizando Rasa NLU
NLU se ocupa de enseñar a un chatbot a entender las entradas de los usuarios. Aquí hay un ejemplo de una conversación que nos gustaría tener con nuestro bot.

Para poder lograr esto, vamos a construir un modelo Rasa NLU y alimentar los datos de entrenamiento que el usuario debe preparar. El modelo convertirá los datos en un formato estructurado que consta de entidades e intenciones.
1. Preparando los datos de entrenamiento de NLU
Los datos de entrenamiento consisten en una lista de mensajes que uno espera recibir del bot. Estos datos se anotan con la intención y las entidades que Rasa NLU debe aprender a extraer. Entendamos el concepto de intención y entidades con un ejemplo.
-
- Intención: La intención describe lo que piden los mensajes. Por ejemplo, para un robot de predicción del tiempo, la oración: What’s the weather like tomorrow?” tiene una request_weatherintención.

- Entidad: piezas de información que ayudan a un chatbot a comprender qué es lo que específicamente pregunta un usuario al reconocer los datos estructurados en la oración .

Aquí la cocina y la ubicación son dos entidades extraídas.
A continuación se muestra un extracto de los datos de entrenamiento. También puedes agregar algunos errores de ortografía o slangs ya que le darán un tono diferente al bot. Para toda la información de entrenamiento, puedes chequear el cuaderno .
nlu_md = """ ## intent:greet - hey - hello there - hi - hello there ## intent:goodbye - cu - good by - cee you later ## intent:mood_unhappy - my day was horrible - I am sad - I don't feel very well - I am disappointed %store nlu_md > nlu.md
Los datos de entrenamiento se escribirán en un nlu.mdarchivo y se almacenarán en el mismo directorio que tu cuaderno. Los datos de entrenamiento generalmente se almacenan en un markdown file.
2. Definiendo la configuración del modelo NLU
Rasa NLU tiene una serie de componentes diferentes, que juntos hacen una pipeline. Una vez que los datos de entrenamiento estén listos, podemos enviarlos al modelo de NLU. Todos los componentes que se enumeran en la pipeline serán entrenados uno tras otro. Puedes leer más sobre las pipelines aquí .
config = """ language: "en" pipeline: - name: "nlp_spacy" # loads the spacy language model - name: "tokenizer_spacy" # splits the sentence into tokens - name: "ner_crf" # uses the pretrained spacy NER model - name: "intent_featurizer_spacy" # transform the sentence into a vector representation - name: "intent_classifier_sklearn" # uses the vector representation to classify using SVM - name: "ner_synonyms" # trains the synonyms """ %store config > config.yml
Este archivo contiene las configuraciones que se utilizarán en el modelo nlu. El archivo de configuración será importante para el entrenamiento del modelo, ya que proporcionará unos cuantos parámetros importantes que se utilizarán durante el entrenamiento del modelo.
3. Entrenando el Modelo NLU.
Es hora de entrenar a nuestro modelo para que reconozca las entradas del usuario, de modo que cuando envíe un mensaje como “hola” a tu bot, este lo reconocerá como una greetintención y cuando envíe “bye”, lo reconocerá como una goodbyeintención.
from rasa_nlu.training_data import load_data
from rasa_nlu.config import RasaNLUModelConfig
from rasa_nlu.model import Trainer
from rasa_nlu import config
# loading the nlu training samples
training_data = load_data("nlu.md")
# trainer to educate our pipeline
trainer = Trainer(config.load("config.yml"))
# train the model!
interpreter = trainer.train(training_data)
# store it for future use
model_directory = trainer.persist("./models/nlu", fixed_model_name="current")
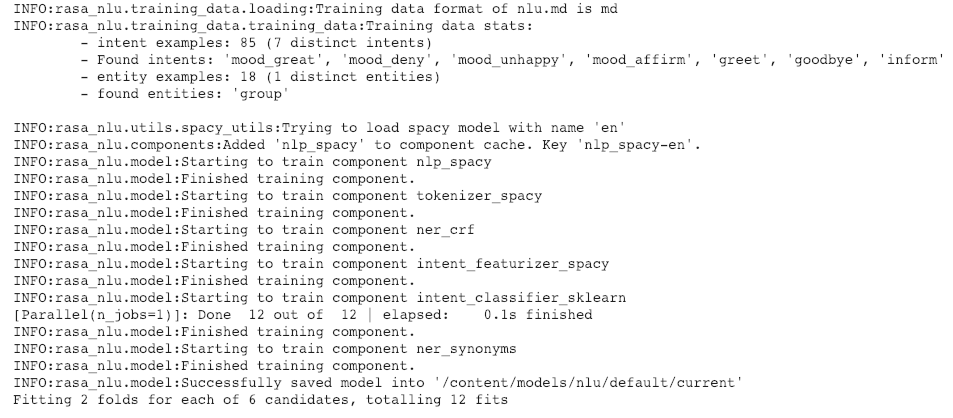
Los archivos de modelo entrenados se almacenarán en la ruta: ‘./models/nlu/current’.
4. Evaluando el modelo NLU
Es hora de probar cómo funciona nuestro modelo. Pasemos algunos mensajes al azar.
# small helper to make dict dumps a bit prettier
def pprint(o):
print(json.dumps(o, indent=2))pprint(interpreter.parse("I am unhappy"))

Nuestro modelo ha funcionado bien. Ahora evaluémoslo en un conjunto de datos de prueba. Sin embargo, para nuestro propósito, evaluémoslo en los datos disponibles, es decir,nlu.md
fromrasa_nlu.evaluateimport run_evaluationrun_evaluation("nlu.md", model_directory)
Obtenemos una matriz de Intent Confusion con varios resultados de evaluación.
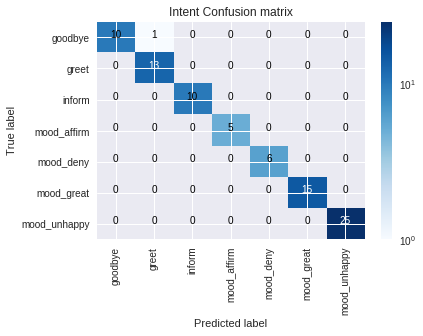
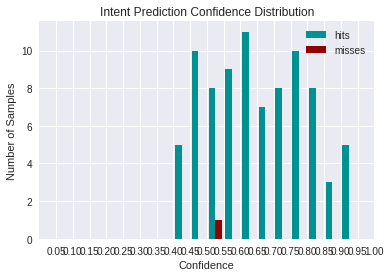 <
<
Hemos creado con éxito un Bot básico que solo puede comprender el lenguaje natural pero no los diálogos. Es hora de agregar las capacidades de diálogo a nuestro bot.
2. Enseñar al bot a responder utilizando Rasa Core.
Nuestro Bot, ahora es capaz de entender lo que el usuario está diciendo, es decir, si nuestro estado de ánimo es feliz o triste. Ahora la siguiente tarea sería hacer que el Bot responda a los mensajes. En nuestro caso, sería obtener una imagen de un perro, gato o ave dependiendo de la elección del usuario para animarlos. Enseñaremos a Robo a hacer respuestas formando un modelo de gestión de diálogo utilizando Rasa Core.
1. Escribiendo Historias
Los datos de capacitación para los modelos de gestión de diálogos se denominan stories. Una historia que consiste en una conversación real que tiene lugar entre un usuario y un Bot. Las entradas del usuario se expresan como intentos, así como las entidades correspondientes, y las respuestas de chatbot se expresan como acciones.
Veamos cómo se ve una historia típica. Esto es solo un extracto y, para obtener información completa, tan solo tienes que consultar el cuaderno.
stories_md = """## happy path
* greet
- utter_greet
* mood_great
- utter_happy
* mood_affirm
- utter_happy
* mood_affirm
- utter_goodbye
## sad path
* greet
- utter_greet
* mood_unhappy
- utter_ask_picture
* inform{"animal":"dog"}
- action_retrieve_image
- utter_did_that_help
* mood_affirm
- utter_happy
"""%store stories_md > stories.md
El formato de una historia típica es el siguiente:
## denota el inicio de una historia y puedes darle un nombre como happy path, sad pathetc.
* Denota los mensajes enviados por el usuario en forma de intenciones.
- Denota la acción tomada por el bot.
3. Definiendo un dominio
El dominio es como un universo donde opera el bot. Esto incluye qué aportaciones del usuario debería esperar obtener, qué acciones debería poder predecir, cómo responder y qué información almacenar. El dominio se compone de cinco partes fundamentales que consisten en intents, slots, entities, actions y templates. Somos conscientes de los dos primeros, entendamos los demás.
- ranuras : las ranuras son como marcadores de posición para los valores que permiten al robot mantener un seguimiento de las conversaciones.
- Acciones : cosas que nuestro bot diría o haría.
- plantillas : cadenas de plantillas para las cosas que diría bot
Definimos el dominio en forma de una domain.ymlvida. Aquí hay un dominio de ejemplo para nuestro bot:
domain_yml = """
intents:
- greet
- goodbye
- mood_affirm
slots:
group:
type: text
entities:
- group
actions:
- utter_greet
- utter_did_that_help
- utter_happy
templates:
utter_greet:
- text: "Hey! How are you?"
utter_goodbye:
- text: "Bye"
utter_ask_picture:
- text: "To cheer you up, I can show you a cute picture of a dog, cat or a bird. Which one do you choose?"
"""
%store domain_yml > domain.yml
4. Acciones personalizadas
Dado que queremos que nuestro Bot realice una llamada a la API para recuperar fotografías de un perro, un gato o un ave, según lo que haya especificado el usuario, debemos crear una acción personalizada. El robot sabrá qué tipo de imagen se debe recibir al recuperar el valor de la ranura group.
from rasa_core.actions import Action
from rasa_core.events import SlotSet
from IPython.core.display import Image, display
import requests
class ApiAction(Action):
def name(self):
return "action_retrieve_image"
def run(self, dispatcher, tracker, domain):
group = tracker.get_slot('group')
r = requests.get('http://shibe.online/api/{}?count=1&urls=true&httpsUrls=true'.format(group))
response = r.content.decode()
response = response.replace('["',"")
response = response.replace('"]',"")
#display(Image(response[0], height=550, width=520))
dispatcher.utter_message("Here is something to cheer you up: {}".format(response))
5. Entrenando un modelo de diálogo
Finalmente, capacitaremos el modelo de gestión del diálogo citando las políticas que deben usarse para capacitarlo. Para nuestro ejemplo, implementaremos una red neuronal en Keras que gana para predecir qué acción tomar a continuación.
El componente principal del modelo es una red neuronal recurrente (un LSTM), que se mapea del historial de diálogos en bruto directamente a la distribución sobre las acciones del sistema.
from rasa_core.policies import FallbackPolicy, KerasPolicy, MemoizationPolicy
from rasa_core.agent import Agent
# The fallback action will be executed if the intent recognition has #a confidence below nlu_threshold or if none of the dialogue #policies predict an action with confidence higher than #core_threshold.
fallback = FallbackPolicy(fallback_action_name="utter_unclear",
core_threshold=0.2,
nlu_threshold=0.1)
agent = Agent('domain.yml', policies=[MemoizationPolicy(), KerasPolicy(), fallback])
# loading our neatly defined training dialogues
training_data = agent.load_data('stories.md')
agent.train(training_data)
agent.persist('models/dialogue')
A veces quieres retroceder a una acción alternativa como decir “Lo siento, no entendí eso”. Para hacer esto, agregue el FallbackPolicyconjunto a tu póliza.

El modelo de política de keras ajustado.
El modelo se guardará en el camino:‘models/dialogue’
6. Hora de chatear
Es hora de chatear con nuestro bot. Ejecuta el siguiente código y comienza a chatear.
import warnings
warnings.simplefilter('ignore', ruamel.yaml.error.UnsafeLoaderWarning)from rasa_core.agent import Agent
from rasa_core.interpreter import NaturalLanguageInterpreter
interpreter = NaturalLanguageInterpreter.create(model_directory)
agent = Agent.load('models/dialogue', interpreter=interpreter)print("Your bot is ready to talk! Type your messages here or send 'stop'")
while True:
a = input()
if a == 'stop':
break
responses = agent.handle_text(a)
for response in responses:
print(response["text"])

El cuaderno
Puedes acceder al cuaderno desde Github o puedes revisarlo a continuación:
Conclusión
Así pues, acabamos así la primera parte del tutorial. Hemos creado un chatbot que es capaz de escuchar la entrada del usuario y responder contextualmente. En la Parte 2 desplegaremos este bot en Slack .
Utilizamos las capacidades de Rasa NLU y Rasa Core para crear un bot con datos de entrenamiento mínimos. En la siguiente parte, utilizaremos el modelo creado para implementar el bot en Slack. Rasa hace que sea realmente fácil para los usuarios experimentar con los chatbots y crearlos sin problemas. Así que es hora de que comiences a crear un bot para tu caso de uso con Rasa.
The post Construyendo un Chatbot conversacional para Slack usando Rasa y Python – Parte 1 first appeared on Planeta Chatbot.
]]>