The post Sistema de preguntas y respuestas multi-PDF con LLM y Langchain first appeared on Planeta Chatbot.
]]>El tema de esta entrada del blog en particular no es original. Ya hay muchos vídeos de YouTube, artículos publicados e hilos de Twitter que describen esta idea de hablar con PDFs. Hay plugins de ChatGPT que pueden hacer esto, y hay Langchain, una biblioteca que te permite hacer esto también. Esa es exactamente la biblioteca que vamos a utilizar hoy.
Pero creo que valdrá la pena describir una vez más esta metodología y este enfoque también teniendo en cuenta que para resolver el problema de chatear con tus PDFs correctamente no es suficiente con hacer el prompting y preguntar. Hay un par de pasos intermedios importantes que te pueden ayudar mucho a que tu solución sea mucho mejor y esto es algo en lo que nos podemos centrar hoy en este blog:
El reto: leer las propuestas de seguros
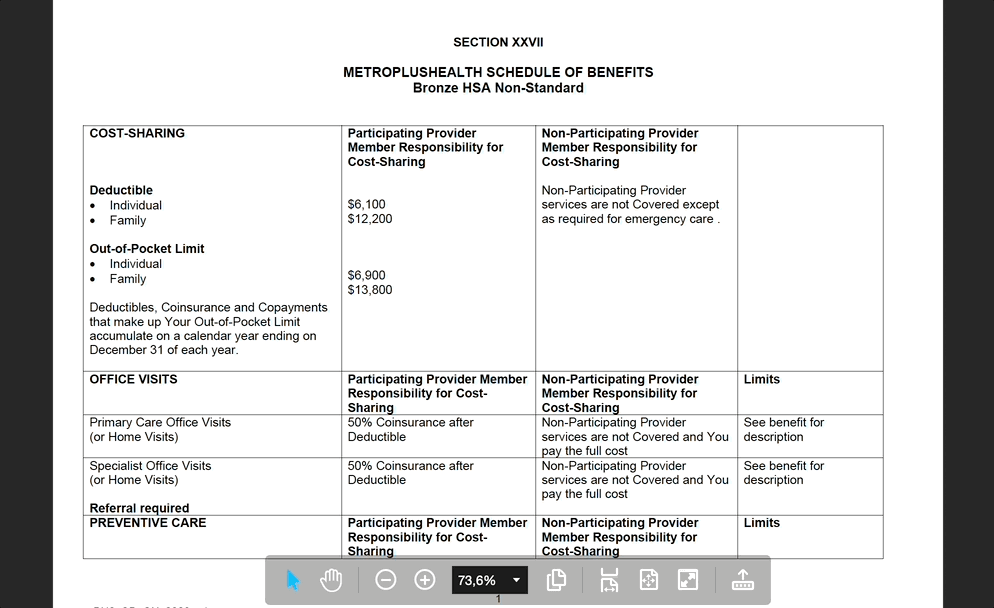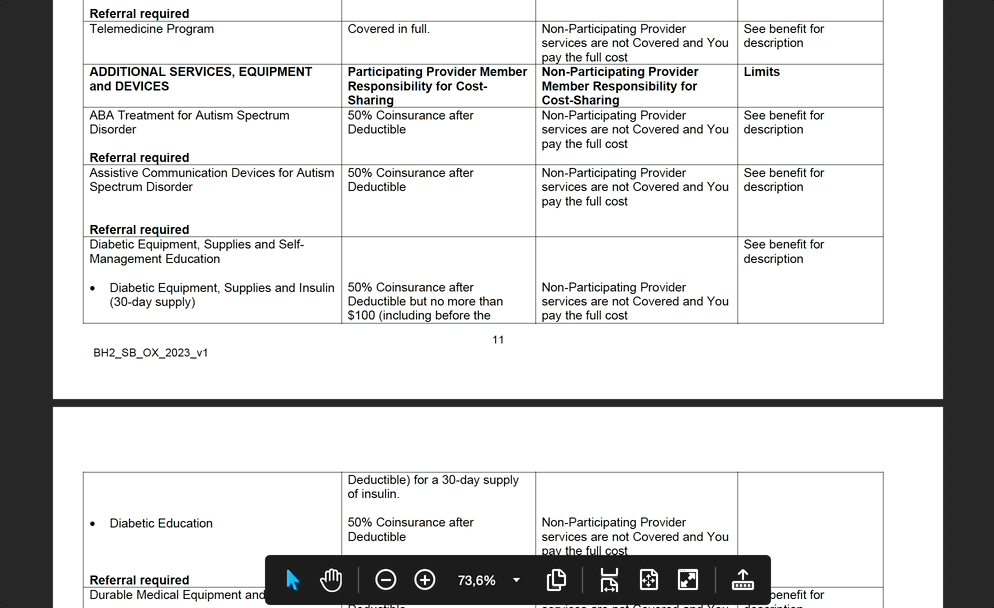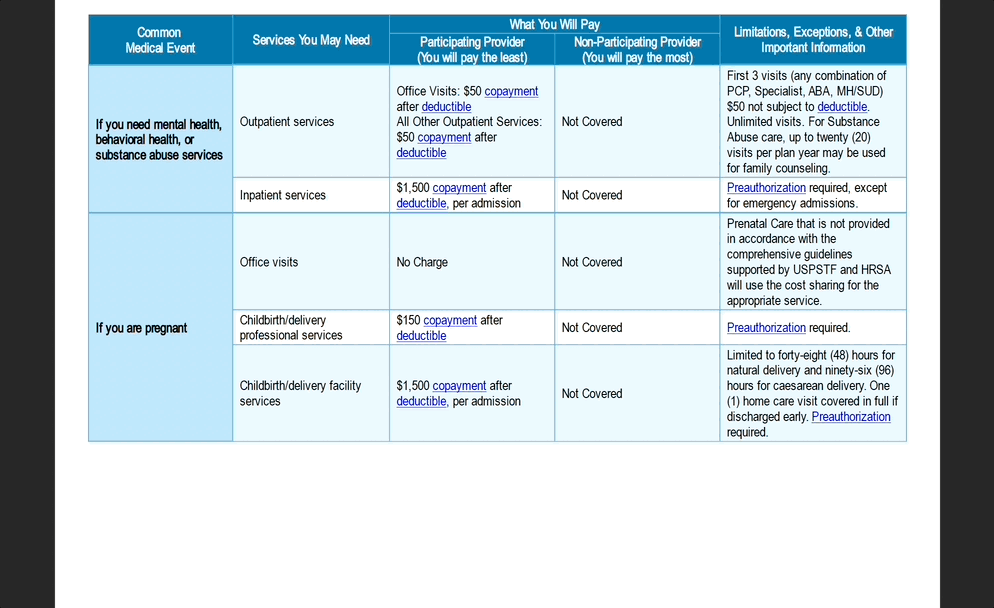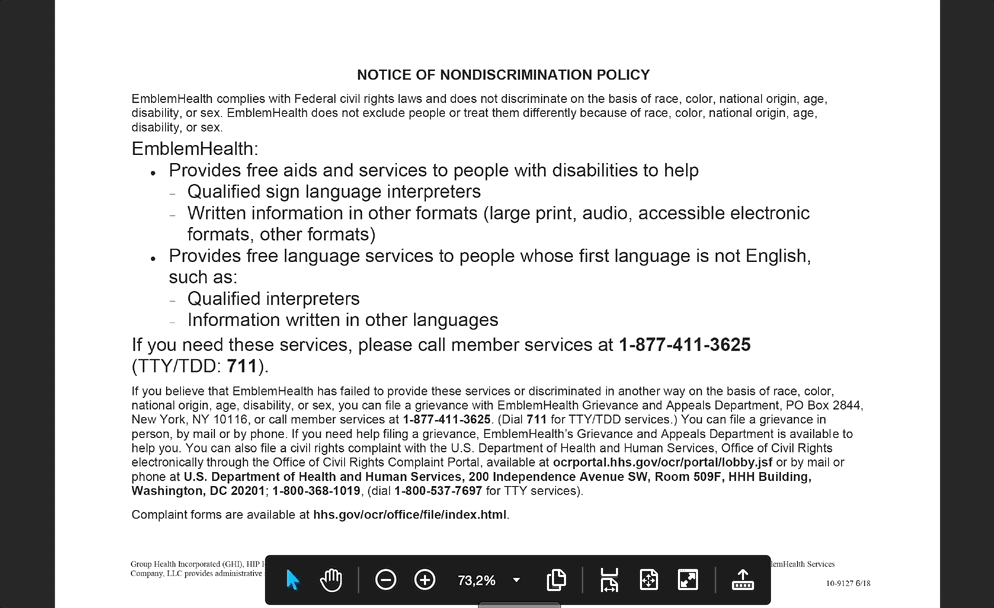
Elegir el plan de seguros adecuado para tu equipo significa revisar innumerables PDF, organizar la información y, en última instancia, tomar una decisión informada. Es una tarea que lleva mucho tiempo y que implica consultar docenas (y a veces cientos) de páginas y documentos. He aquí la gran pregunta: ¿Podemos automatizar esta carga de trabajo? Claro que sí. Pero, por desgracia, no basta con enviar miles de documentos a ChatGPT. Al menos no hoy.
Los pasos intermedios son clave
Hacer preguntas y dar indicaciones es importante, pero no basta para descifrar el código de este reto. Tenemos que añadir algunos pasos adicionales para superarlo de verdad. Un paso que a menudo se pasa por alto es generar un resumen intermedio antes de formular la pregunta final. ¿Por qué? Imaginemos que tenemos que trabajar con toneladas de documentos. Será difícil para cualquier algoritmo mantener el contexto con precisión durante todo el proceso.
Y no nos olvidemos de los límites de herramientas como Langchain, que tienen que lidiar con los límites de los tokens en esos LLM. Para hacer frente a estos obstáculos, podemos elaborar de forma proactiva respuestas a preguntas específicas relacionadas con los documentos de seguros. Al unir estas respuestas, creamos un resumen que captura la esencia de miles de documentos. Y el tutorial de Langchain (nivel 4 aquí) lo recomienda.
Conjunto de herramientas estándar: LLMs + Langchain
- Vectorización. Para simplificar las cosas, utilizaremos el modelo GPT de OpenAI, combinado con la biblioteca Langchain. Estas potentes herramientas nos permiten aprovechar el enorme potencial de los modelos lingüísticos y, al mismo tiempo, sacar el máximo partido de las capacidades de contexto ampliadas de Langchain. Al vectorizar esos PDF con un toque de superposición, nos aseguramos de no perder ningún contexto importante por el camino:
class DatasetVectorizer:
«»»
A class for vectorizing datasets.
«»»
def vectorize(self, text_file_paths, chunk_size=1000, chunk_overlap=500, openai_key=»»):
documents = []
for text_file_path in text_file_paths:
doc_loader = TextLoader(text_file_path)
documents.extend(doc_loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_overlap=chunk_overlap, chunk_size=chunk_size)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key=openai_key)
docsearch = Chroma.from_documents(texts, embeddings)
return documents, texts, docsearch
- Resumen hecho a mano. Hablemos ahora del resumen intermedio. Para hacerlo bien, prepararemos una serie de preguntas generales que se centrarán en los documentos del seguro. Las preguntas importantes se refieren a las franquicias, los detalles de la cobertura, los importes de indemnización, las opciones de hospital, la cobertura familiar, la cobertura internacional, los cuidados dentales, etcétera. Respondiendo a estas preguntas y uniendo las respuestas, crearemos un resumen de primera calidad que capte la esencia de cada documento.
QUESTIONS = [
‘How good are the deductibles?’,
«How is the preventive care coverage?»,
‘How this plan fits for remote workers in the US and abroad?’,
‘What is the maximum money amount that can be compensated?’,
‘Can I go to any hospital of my choice?’,
‘Are there any limitations that won\’t allow to use the insurance?’,
‘Does it cover the family members of the applicant?’,
‘What are the healthcare procedures that are not covered by the insurance?’,
‘Can I use the insurance for the dental care?’,
‘Can I use the insurance in other countries?’
]
- Formular la pregunta final. Con el resumen intermedio en el bolsillo, es hora de sumergirnos en el proceso de toma de decisiones. Aquí es donde por fin resolvemos lo que queremos. Ya podemos lanzar un conjunto específico de preguntas basadas en nuestros criterios de selección de propuestas de seguros. Comparemos esas propuestas en función de la cobertura, las franquicias, los requisitos específicos, etc. Planteando estas preguntas al resumen, extraeremos la información más jugosa y tomaremos decisiones como estrellas del rock.
template = «»»
I want you to act as an expert in insurance policies. I have asked two companies about their insurance policies and here are their answers:
{summary_of_answers}
I am looking for insurance for a full-remote consulting company with 100 employees. I want you to tell me which company is better and why.
Give me a rating (x out of 10) for the following categories for each company separately with a short explanation (10 words max) for each category:
1. Coverage of different health procedures
2. Flexibility for remote workers abroad
3. Price and compensation
Your answer:
«»»
prompt = PromptTemplate(
input_variables=[«summary_of_answers»],
template=template,
)
Aplicación Streamlit para hacerlo más sencillo
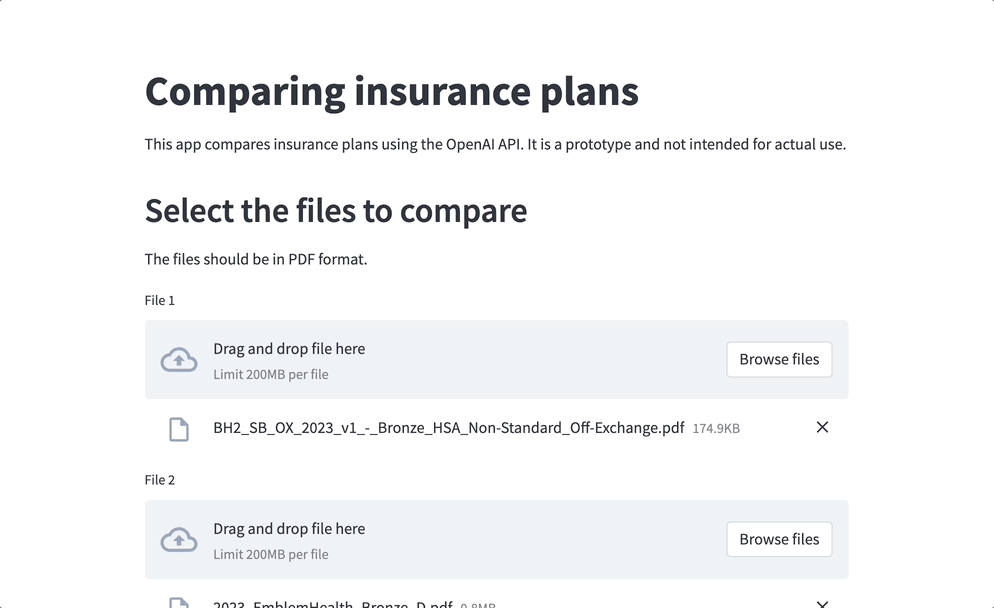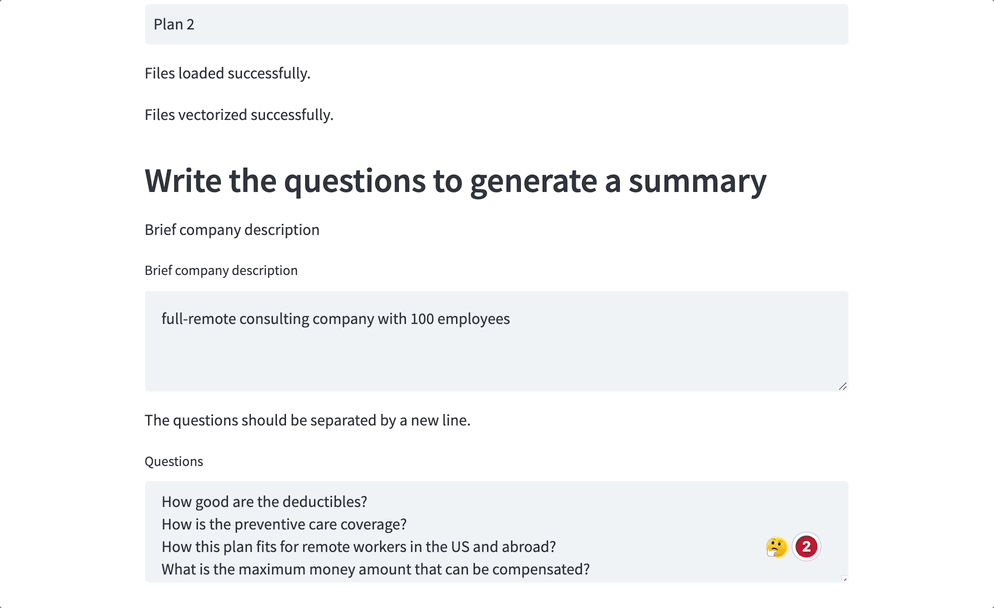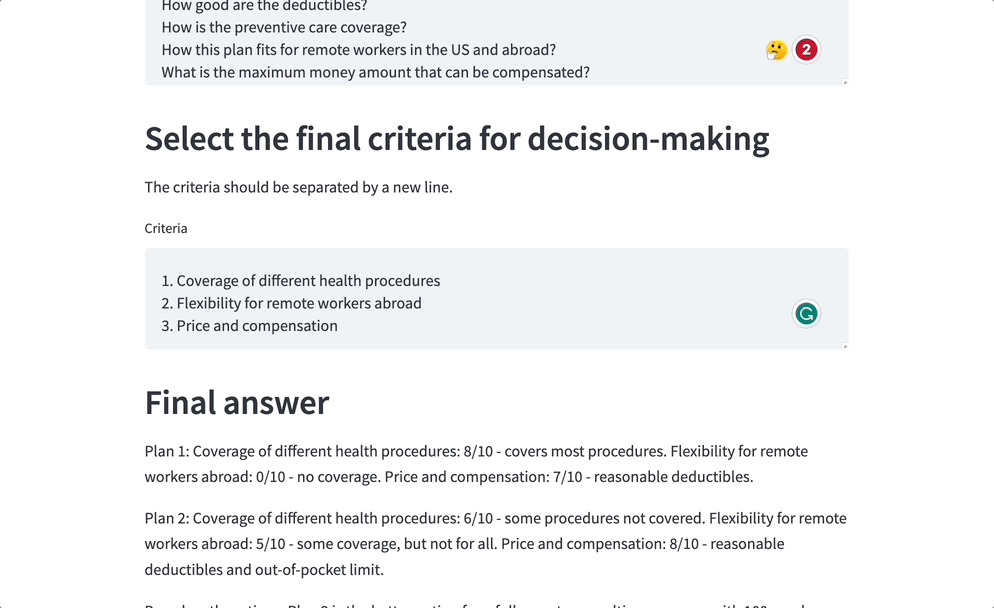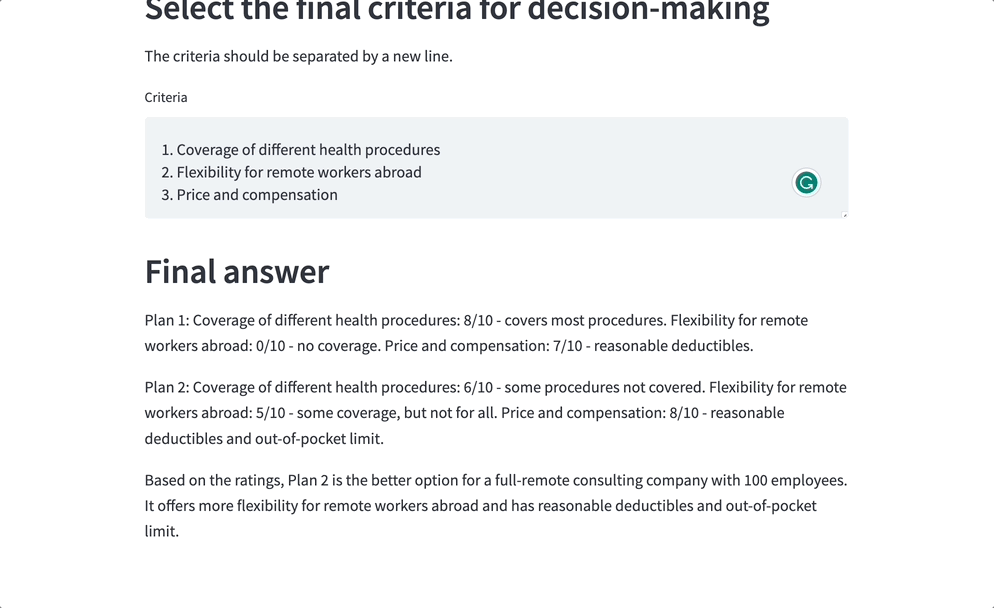
Ahora, aquí está la guinda del pastel. He preparado una interfaz fácil de usar utilizando la biblioteca Streamlit. Incluso si no eres un mago de la tecnología, puedes navegar sin esfuerzo por la aplicación e introducir tus preguntas y criterios más candentes.
Conclusiones
Hemos revisado las capacidades de modelos lingüísticos como OpenAI GPT y Langchain, para generar resúmenes exhaustivos y tomar decisiones bien informadas basadas en nuestros criterios. La inclusión de pasos intermedios, la utilización de la aplicación Streamlit y la introducción de la automatización agilizan todo el proceso, haciéndolo accesible y eficiente para todas las partes implicadas. ¡Ahora te toca a ti crear tu propia aplicación sobre él! Avísame si necesitas alguna pregunta o apoyo en el desarrollo.
The post Sistema de preguntas y respuestas multi-PDF con LLM y Langchain first appeared on Planeta Chatbot.
]]>The post ¿Cómo competir cuando se puede copiar una startup de IA con Whisper y ChatGPT en 3 minutos? first appeared on Planeta Chatbot.
]]>Paso 1: obtener un texto de voz
import whisper
model = whisper.load_model(«medium»)
result = model.transcribe(«job.m4a»)
Buenos días, equipo de Neurons Lab. He encontrado vuestro puesto para data scientist, comprobación de hipótesis y aprendizaje profundo, y quiero solicitarlo. Vivo en Italia. Mi nombre es Alex Honcher y ya he trabajado en ciencia de datos durante los últimos cinco años. Mi formación es licenciatura en informática y máster en matemáticas, ambos en el Politécnico de Milán. Primero trabajé como becario en Banca Popolare durante un año. Trabajé en la predicción de plazos para la banca minorista con un equipo de cuatro personas. En este trabajo yo estaba trabajando principalmente con SecondLearn y Pandas. Y después de esto me mudé y trabajé durante los últimos cuatro años en una startup. La startup también era FinTech, pero relacionada con la gestión de inversiones. Y yo estaba trabajando en la predicción de los mercados. Estaba construyendo modelos de aprendizaje automático en diferentes conjuntos de datos, principalmente series temporales, pero tenía que limpiarlos. Los datos eran más grandes, así que utilizaba AWS SageMaker para procesarlos. También entrenaba modelos allí y los implementaba. Así que entiendo todo el ciclo de MLops parte. Y me gusta mucho que tengas la política remota. Y creo que encajo muy bien en su área de responsabilidad. Puedo hacer modelado y pruebas. También tengo experiencia en Git. Siempre uso Git. Y las habilidades, mi inglés es bueno. Hago aprendizaje automático y modelado estadístico. Y me gusta mucho lo que ofrecen y también la posibilidad de trabajar a tiempo parcial. Así que por favor considere mi aplicación a la posición. Muchas Gracias
Paso 2: estructurar el texto en un CV
CV
Nombre: Alex Honcher
Lugar de trabajo: Italia
Estudios:
Licenciado en Informática, Politecnico di Milano
Máster en Matemáticas, Politecnico di Milano
Experiencia laboral:
Prácticas en Banca Popolare (1 año)
Trabajé en la predicción de plazos para el sector de la banca minorista
Colaboración con un equipo de cuatro personas
Utilización de SecondLearn y Pandas para el análisis de datos
Startup (4 años)
Trabajé en una startup FinTech centrada en la gestión de inversiones
Desarrolló modelos de aprendizaje automático para la predicción del mercado
Trabajo extensivo con series temporales de datos
Limpieza y procesamiento de datos con AWS SageMaker
Entrenó e implementó modelos de aprendizaje automático
Experiencia en todo el ciclo MLops
Competencias:
Machine Learning
Modelado estadístico
Control de versiones Git
Dominio del inglés
Otros:
Interesado en la política de trabajo remoto
Capacidad para trabajar a tiempo parcial
Paso 3: pedir que se adapte un CV a los puestos paso a paso
Por supuesto. Aquí tienes una tabla en la que se compara el CV del candidato con la descripción del puesto, junto con una puntuación final de coincidencia:
| Criterios de la descripción del puesto | CV del candidato |
|---|---|
| Modelización estadística y comprobación de hipótesis. | |
| Diseño, entrenamiento y validación de resultados de algoritmos de aprendizaje automático. | |
| Escribir SQL limpio y eficiente | Probablemente, basado en experiencia en ciencia de datos |
| Construir y probar aplicaciones Python. | |
| Construir redes neuronales profundas con herramientas modernas (por ejemplo, PyTorch o Tensorflow). | |
| Colaborar a través de Git | ✓ |
| Aprendizaje automático e ingeniería | ✓ |
| Modelado estadístico | ✓ |
| Minería y análisis de datos | ✓ |
| Inglés avanzado, buena comunicación con las partes interesadas del negocio | ✓ |
| Desarrollo de documentación | Probablemente, basado en experiencia en ciencia de datos |
| Experiencia con aprendizaje en línea, aprendizaje de refuerzo, algoritmos de bandidos contextuales | No se menciona en el CV |
| Experiencia en el lanzamiento y la validación de campañas en línea mediante pruebas A/B o los métodos antes mencionados. | No se menciona en el CV |
| Experiencia previa en juegos online, comercio electrónico y entretenimiento o industrias similares | Experiencia relevante en FinTech y predicción de mercados |
| Trabajo a distancia desde cualquier lugar | Interés expreso en la política de trabajo a distancia |
| Flexibilidad del horario laboral | Interés manifestado por el trabajo a tiempo parcial |
La estructura es excelente, e incluso se puede puntuar y empaquetar como JSON o cualquier otro formato para su visualización en el sitio web. Pero me hizo preguntarme, ¿dónde está la defensa? ¿Dónde está la singularidad? ¿Cómo pueden las startups de IA diferenciarse unas de otras e incluso de las startups o empresas de software que no son de IA?
Las startups de IA están en apuros
Las startups de IA ganan menos y son más difíciles de crear:
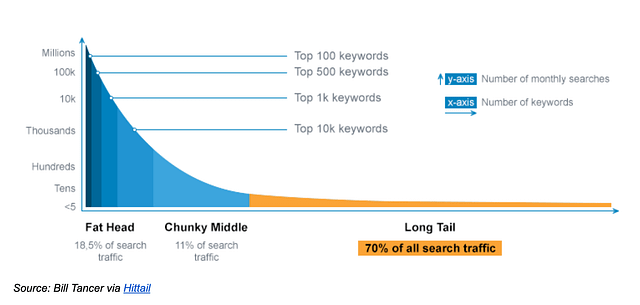
Este es un precio clásico de Andreessen & Horowitz escrito en 2019. Los programas de IA no son lo mismo que los programas SaaS que «solo» se ejecutan en la nube y tienen múltiples golpes de margen:
- La infraestructura implica trabajo humano ad-hoc (etiquetado de datos y manejo de casos edge).
- Los casos edge no son «edge» per se: la mayor parte de tu negocio vendrá de ellos y nunca tendrás suficientes datos «solo para entrenar IA».
- Los «efectos de los datos» son un mito (la mayoría de los datos recogidos serán esencialmente los mismos) y la I+D ya no es un stopper.
Los algoritmos ya no son un stopper (al menos no para ti)
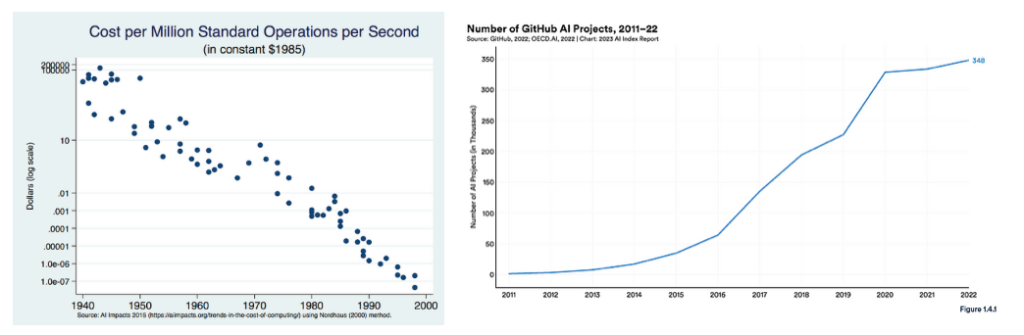
Los gráficos, creo, ya se explican por sí mismos. Todo el mundo puede ejecutar los mismos modelos de IA abierta utilizando los mismos proveedores de nube que tú. A menudo oigo decir que tus datos son únicos y que nadie más tiene acceso a ellos. Bueno, si tus datos son realmente tan únicos, significa que lo más probable es que no sea suficiente para entrenar un modelo de IA de última generación realmente bueno a partir de ellos. Todavía se puede construir una máquina de toma de decisiones automatizada muy decente y única y un negocio a partir de ella, pero no será un negocio de IA tal y como lo vemos hoy en día.
¿Volver a las raíces?
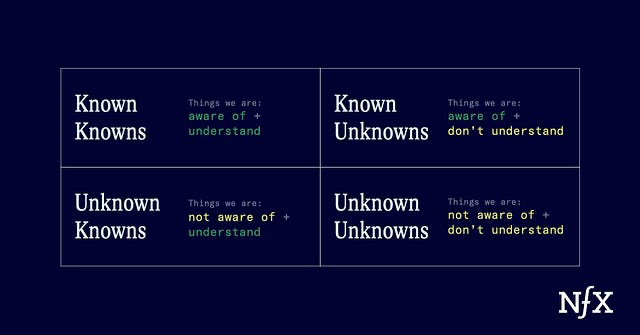
Si la informática, los modelos de IA, los datos y la ingeniería rápida no son un stopper, ¿qué lo es?
«Negocios» clásicos
Este increíble artículo de NFX plantea cuestiones fundamentales sobre tu negocio. Me gusta especialmente la pregunta: «Si eliminas la palabra “IA” de tu discurso, ¿sigue siendo un discurso ganador?» O esta otra: «¿Se tarda más de 60 segundos con ChatGPT en realizar la misma tarea?» Nuestro ejemplo de voz y contratación puede reducirse fácilmente a menos de 60 segundos. Volvemos a los orígenes: comprender los problemas reales de los clientes, analizar la cadena de valor e inyectar automatización donde realmente importa.
«Operaciones» clásicas
Cuando todo el mundo tiene los mismos LLM y centros en la nube, la competencia se reduce al triángulo «dorado» de velocidad, costes y calidad. Las nuevas preguntas importantes son: ¿Construir tu propio LLM? ¿Ejecutarlo en tu propia nube? ¿Optimizar la arquitectura de la nube? ¿Eres dueño de tu propio hardware? ¿Encontrar un equipo de etiquetado de datos más barato? ¿Acelerar el progreso de tu equipo de IA? No se trata de retos creativos de ingeniería de avisos para «Chief Prompt Engineering Officers», sino más bien de tediosas y complejas tareas de gestión.
Conclusiones
En una era en la que los modelos de IA y la infraestructura en la nube son cada vez más accesibles para todos, las startups de IA se enfrentan al reto de la diferenciación. Sin embargo, si adoptan los principios empresariales clásicos, se centran en la experiencia de dominio y dan prioridad a la eficiencia operativa, las startups de IA pueden labrarse su posición única en el mercado. Aunque los algoritmos por sí solos pueden no ser un foso, la combinación de datos únicos, personalización, innovación continua y un enfoque centrado en el cliente puede diferenciarlos de la competencia.
The post ¿Cómo competir cuando se puede copiar una startup de IA con Whisper y ChatGPT en 3 minutos? first appeared on Planeta Chatbot.
]]>