The post Cómo crear agentes de IA generativa a escala empresarial con AWS Bedrock: Una guía completa first appeared on Planeta Chatbot.
]]>Amazon Web Services (AWS) ofrece una solución a este desafío a través de AWS Bedrock y un conjunto de servicios de AWS diseñados para crear agentes de IA conversacionales que puedan gestionar y utilizar de forma segura los datos de propiedad. AWS Bedrock, junto con el sólido ecosistema de AWS, ofrece un marco en el que la seguridad y la gobernanza están en primer plano, lo que garantiza que las empresas puedan aprovechar el poder de la IA generativa sin comprometer la protección de los datos.
En este tutorial práctico, profundizaremos en la creación de un agente de IA conversacional que utiliza documentos propios almacenados en Amazon S3. Este agente de IA será capaz de recuperar información relevante de nuestra base de datos mediante Retrieval-Augmented Generation (RAG) y AWS OpenSearch Vector Database, mostrando la integración perfecta y las potentes capacidades de los servicios de AWS para manejar tareas complejas de recuperación de datos.
Para que este agente de IA sea accesible, desarrollaremos una API utilizando AWS Lambda y API Gateway, garantizando una interfaz escalable y segura para la interacción. Además, para mejorar la experiencia del usuario, emplearemos Voiceflow para el front-end, lo que permitirá una interfaz conversacional intuitiva y atractiva.
La arquitectura
El siguiente diagrama es un patrón de arquitectura de solución común que puedes utilizar para integrar cualquier aplicación de chatbot a Knowledge Bases para Amazon Bedrock. Utilizaremos este diagrama como base para el back-end de nuestra aplicación y lo integraremos a través de una API en nuestra interfaz de chat Voiceflow.
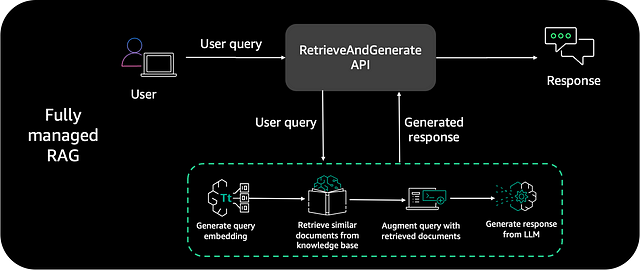
Esta arquitectura incluye los siguientes pasos:
- Consulta del usuario: Un usuario inicia el proceso interactuando con el chatbot a través de una solicitud de API iniciada a través de la interfaz de chat front-end de Voiceflow, emitiendo una pregunta en lenguaje natural.
- La API activa AWS Lambda: La API recibe la consulta y activa una función de AWS Lambda. Esta función es responsable del procesamiento posterior de la consulta del usuario.
- Invocar la API RetrieveAndGenerate: Dentro de la función de AWS Lambda, se procesa la consulta del usuario y se invoca la API RetrieveAndGenerate de Amazon Bedrock.
- Conversión de la consulta en vector: A continuación, la consulta del usuario se convierte en un vector mediante un modelo de incrustación de Amazon Titan dentro de Amazon Bedrock.
- Recuperación de información relevante: Tras convertir la consulta, el sistema extrae segmentos de datos de la base de conocimientos que se alinean semánticamente con la consulta del usuario. Este proceso se realiza mediante la comparación de la representación vectorial de la consulta con las incrustaciones de texto almacenadas en un almacén vectorial de Amazon OpenSearch Serverless.
- Aumento de la consulta del usuario: La información recuperada se utiliza para aumentar la consulta original del usuario, añadiendo contexto adicional que es fundamental para generar una respuesta precisa y contextualmente relevante.
- Generación de la respuesta con LLM: esta instrucción enriquecida se utiliza como entrada para un modelo de lenguaje amplio (LLM), como Anthropic Claude 2, disponible en Amazon Bedrock. A partir del contexto enriquecido, el LLM genera una respuesta completa y pertinente.
- Envío de la respuesta al usuario: La respuesta elaborada por el LLM se envía de vuelta al usuario a través de la API al front-end Voiceflow, donde se muestra al usuario.
La siguiente sección proporciona una guía detallada paso a paso sobre la construcción de un agente de IA conversacional utilizando varios servicios de AWS y Voiceflow. Para participar y seguir la guía, asegúrate de tener una cuenta de AWS activa. También puedes encontrar una copia del código fuente en GitHub.
La base de datos de conocimientos
Carga tu conjunto de datos de conocimiento en Amazon S3
Encuentra un conjunto de datos que te gustaría que tu Agente de IA consultara. Procederemos a cargar este conjunto de datos en un bucket de Amazon S3 y a configurar una base de datos de conocimientos para interactuar con el conjunto de datos elegido de forma eficaz.
Completa los siguientes pasos:
- En la consola de Amazon S3, selecciona Buckets en el panel de navegación.
- Haz clic en Crear bucket.
- Nombra el bucket knowledgebase-<chatbot-name>.
- Deja el resto de la configuración del bucket como predeterminada y seleccione Crear.
- Navega hasta el bucket knowledgebase-<chatbot-name>.
- Selecciona «Crear carpeta» y nómbrala dataset.
- Deja el resto de configuraciones de carpeta por defecto y elija Crear.
- Ve a la carpeta del conjunto de datos.
- Arrastra y suelta el conjunto de datos que descargaste anteriormente en este bucket y selecciona Cargar.
- Vuelve al inicio del bucket y elige «Crear carpeta» para crear una nueva carpeta y nómbrala lambdalayer.
- Deja todos los demás ajustes por defecto y crea la carpeta.
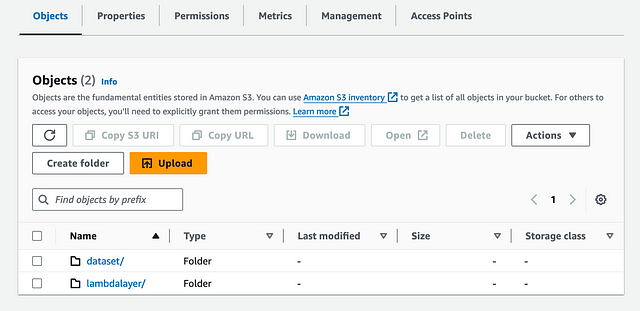
- Navega hasta la carpeta lambdalayer.
- Sube el archivo knowledgebase-lambdalayer.zip disponible en la carpeta /data/lambda_layer en GitHub y selecciona Upload. Utilizarás este código de capa lambda más adelante para crear la función lambda.
Crear una base de conocimientos
- En este paso, crearemos una base de conocimientos utilizando el conjunto de datos que subimos al bucket de S3 en el paso anterior.
En la consola de Amazon Bedrock, navega hasta la sección Orchestration y selecciona Knowledge Base. Es importante tener en cuenta que, en el momento de escribir este artículo, la función de base de datos de conocimientos solo está disponible en determinadas regiones. Por lo tanto, para este tutorial, utilizaremos us-east-1 como región predeterminada. - Selecciona «Crear base de conocimientos».
- En la sección «Detalles de la base de conocimientos», introduce un nombre y una descripción opcional.
- En la sección Permisos IAM, selecciona «Crear «y utiliza un nuevo rol de servicio e introduzca un nombre para el rol.
- Selecciona Siguiente.
- En la sección Fuente de datos, deja «Nombre de fuente de datos» como nombre predeterminado.
- En URI de S3, seleccione Examinar S3 para elegir el bucket de S3 knowledgebase-<chatbot-name>/dataset/. Debes apuntar al bucket de S3 y a la carpeta del conjunto de datos que creó en los pasos anteriores.
- En la sección Configuración avanzada, deja los valores predeterminados (si lo deseas, puedes cambiar la estrategia de fragmentación predeterminada y especificar el tamaño de los trozos y la superposición en porcentaje).
- Selecciona «Siguiente».
- En la sección Modelo de incrustación, selecciona «Incrustación Titan G1 – Texto para el modelo de incrustación».
- En la sección Base de datos vectorial, seleccionea «Crear» rápidamente un nuevo almacén vectorial, esto crea un nuevo almacén vectorial OpenSearch Serverless en su cuenta.
- Selecciona Siguiente.
- En la página Revisar y crear, revisa toda la información o selecciona Anterior para modificar cualquier opción.
- Selecciona Crear base de conocimientos. Observa que comienza el proceso de creación de la base de conocimientos y que el estado es En curso. La creación del almacén de vectores y de la base de conocimientos tardará unos minutos. No abandones la página, de lo contrario la creación fallará.
- Cuando el estado de la base de conocimientos sea «Listo», anota el ID de la base de conocimientos. Lo utilizarás en los próximos pasos para configurar la función Lambda.
- Ahora que la base de conocimientos está lista, tenemos que sincronizar nuestro conjunto de datos personalizado con ella. En la sección «Fuente de datos» de la página de detalles de la base de conocimientos, seleccione Sincronizar para activar el proceso de ingestión de datos desde el bucket de S3 a la base de conocimientos.
- Este proceso de sincronización divide los archivos de documentos en trozos más pequeños del tamaño especificado anteriormente, genera incrustaciones vectoriales utilizando el modelo de incrustación de texto seleccionado y los almacena en el almacén vectorial administrado por Knowledge Bases para Amazon Bedrock.
- Cuando se complete la sincronización del conjunto de datos, el estado de la fuente de datos cambiará al estado Listo. Ten en cuenta que, si añades documentos adicionales en la carpeta de datos de S3, deberás volver a sincronizar la base de conocimientos.
Nuestra base de conocimientos ya está lista. Ten en cuenta que también puede utilizar las API del servicio Knowledge Bases for Amazon Bedrock y la CLI de AWS para crear una base de conocimientos mediante programación.
La función Lambda y la puerta de enlace API
En esta sección, construiremos una API diseñada para activar una función Lambda, que gestionará las consultas de los usuarios mediante la integración de AWS Bedrock y la base de conocimientos establecida previamente. Para simplificar la implementación y el desarrollo, se utilizará el marco Serverless para construir e implementar la infraestructura backend.
Iniciar el marco Serverless
Para obtener información sobre la instalación de Serverless, consulte esta página de instrucciones. Para iniciar un nuevo proyecto Serveless ejecute:
# initate a new serverless project
serverless
> select AWS - Python - HTTP API
> name your project
> Register or Login to Serverless Framework: n enter
> Do you want to deploy now?: n enter
A continuación, configuraremos nuestra infraestructura de back-end en el archivo serverless.yml.
service: knowledge-base-api
frameworkVersion: "3"
provider:
name: aws
runtime: python3.12
stage: dev
region: us-east-1
environment:
KNOWLEDGE_BASE_ID: ${self:custom.knowledgeBaseID}
iam:
role:
statements:
- Effect: "Allow"
Action:
- "bedrock:InvokeModel"
- "bedrock:Retrieve"
- "bedrock:RetrieveAndGenerate"
Resource: "*"
custom:
knowledgeBaseID: "<your knowledgebase ID>"
lambdaLayerS3BucketName: "<your S3 bucket name>"
functions:
invokeKnowledgeBase:
handler: handler.lambda_handler
memorySize: 256
timeout: 60
layers:
- { Ref: DeployKnowledgeBaseLambdaLayer }
events:
- http:
path: /
method: get
cors: true
resources:
Resources:
DeployKnowledgeBaseLambdaLayer:
Type: AWS::Lambda::LayerVersion
Properties:
LayerName: KnowledgeBaseLambdaLayer
Description: Knowledge Base Lambda Layer
Content:
S3Bucket: ${self:custom.lambdaLayerS3BucketName}
S3Key: lambdalayer/knowledgebase_lambdalayer.zip
CompatibleRuntimes:
- python3.12
- python3.11
- python3.10
Este archivo serverless.yml describe la configuración para implementar un servicio de API de base de conocimientos mediante el marco Serverless en AWS. El servicio, llamado knowledge-base-api, especifica AWS como el proveedor de la nube, utilizando Python 3.12 como el entorno de tiempo de ejecución en la etapa dev dentro de la región us-east-1. Las variables de entorno están configuradas, incluyendo un KNOWLEDGE_BASE_ID, que anotamos en el paso 15 de la Creación de Knowlege Base.
El rol de IAM definido en la configuración del proveedor concede al servicio permiso para realizar acciones como invocar modelos y recuperar datos mediante las API de Amazon Bedrock (bedrock:InvokeModel, bedrock:Retrieve y bedrock:RetrieveAndGenerate), con los permisos asignados a todos los recursos (Resource: «*») para simplificar y ampliar el acceso en este ejemplo.
La sección personalizada incluye marcadores de posición para especificar el knowledgeBaseID y el nombre de un bucket de S3 (knowledgebase-<chatbot-name>) donde se almacena la capa Lambda para la base de conocimientos.
Se detalla una única función, invokeKnowledgeBase, con handler.lambda_handler indicando el punto de entrada para la función Lambda. Está configurada para utilizar 256 MB de memoria y tiene un tiempo de espera de 60 segundos. Esta función está asociada a un evento HTTP GET, por lo que es accesible a través de un punto final RESTful, y CORS está habilitado para solicitudes de origen cruzado. La función también incluye una capa Lambda, DeployKnowledgeBaseLambdaLayer, que se define en la sección de recursos.
En el bloque de recursos, DeployKnowledgeBaseLambdaLayer se configura para crear una versión de la capa Lambda, que encapsula el código adicional o las bibliotecas que necesita la función Lambda. Esta capa se denomina KnowledgeBaseLambdaLayer y obtiene su contenido del bucket de S3 (knowledgebase-<chatbot-name>/lambdalayer). La capa es compatible con varios tiempos de ejecución de Python, lo que garantiza la flexibilidad entre diferentes versiones de Python.
Crear la función Lambda
En esta sección, nos sumergiremos en la creación de una función Lambda que forma la columna vertebral de nuestra aplicación de IA conversacional. Esta función es responsable de procesar las consultas de los usuarios, aprovechando el potente servicio AWS Bedrock para obtener y generar respuestas de nuestra base de conocimientos. Desglosaremos la función en pasos manejables, explicando el propósito y la funcionalidad de cada parte.
import os
import boto3
import json
boto3_session = boto3.session.Session()
region = boto3_session.region_name
La función comienza importando las bibliotecas necesarias. os se utiliza para acceder a variables de entorno, boto3 para AWS SDK para interactuar con los servicios de AWS y json para manejar estructuras de datos JSON. A continuación, inicializa una sesión de boto3 y recupera la región de AWS en la que se implementa la función Lambda.
bedrock_agent_runtime_client = boto3.client('bedrock-agent-runtime', region_name="us-east-1")
Esta línea crea un cliente Boto3 para el tiempo de ejecución del agente Bedrock, especificando la región (aquí, «us-east-1»). Este cliente se utiliza para interactuar con AWS Bedrock, específicamente para invocar la API retrieve_and_generate.
def lambda_handler(event, context):
# Extract the question and session ID from the event
question = event[«queryStringParameters»][«question»]
try:
session_id = event[«queryStringParameters»][«session_id»]
except:
session_id = «None»
# Assuming you’ve set the KNOWLEDGE_BASE_ID as an environment variable in your Lambda function
kb_id = os.environ[«KNOWLEDGE_BASE_ID»]
# Specify the model ID and construct its ARN. Update these placeholders as needed.
model_id = «anthropic.claude-v2»
region = «us-east-1»
model_arn = f’arn:aws:bedrock:{region}::foundation-model/{model_id}’
# Call the retrieve and generate function
response = retrieveAndGenerate(question, kb_id, model_arn, session_id)
# Extract the generated text and session ID from the response
generated_text = response[‘output’][‘text’]
session_id = response.get(‘sessionId’, »)
headers = {
«Access-Control-Allow-Origin»: «*»,
«Access-Control-Allow-Credentials»: True
}
# Return the response in the expected format
return {
‘statusCode’: 200,
‘headers’: headers,
‘body’: json.dumps({
«question»: question.strip(),
«answer»: generated_text.strip(),
«sessionId»: session_id
}, ensure_ascii=False)
}
La función lambda_handler actúa como puerta de enlace entre AWS Lambda y el mundo exterior, en este caso, principalmente AWS API Gateway que activa esta función de Lambda. Cuando un usuario envía una consulta a través de la interfaz de front-end, esta función entra en acción. Comienza analizando la solicitud entrante, buscando específicamente la pregunta y, opcionalmente, un session_id en los parámetros de consulta. Estos parámetros son esenciales para mantener un flujo de diálogo continuo y proporcionar contexto al modelo de IA para generar respuestas relevantes.
Tras extraer la información necesaria del objeto de evento, lambda_handler procede a recopilar detalles de configuración adicionales. Recupera el ID de la base de conocimientos (kb_id) de las variables de entorno y, a continuación, construye el ARN del modelo, que identifica de forma exclusiva el modelo de IA que se utilizará para generar las respuestas. Este ARN incluye la región y el identificador específico del modelo. En este tutorial, utilizaremos el modelo Claude 2 de Anthropic (anthropic.claude-v2).
def retrieveAndGenerate(question, kbId, model_arn, sessionId=None):
if sessionId != "None":
return bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': question
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn
}
},
sessionId=sessionId
)
else:
return bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': question
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn
}
}
)
Con toda la información y las configuraciones necesarias a mano, lambda_handler llama a la función retrieveAndGenerate. La función retrieveAndGenerate interactúa con la API Retrieve and Generate de AWS Bedrock. Toma la pregunta del usuario, el ID de la base de conocimientos, el ARN del modelo y un ID de sesión opcional, y llama a la API de Bedrock para generar una respuesta basada en el contenido de la base de conocimientos.
El session_id es un identificador único que permite el seguimiento y la gestión de sesiones de usuario individuales en una aplicación de IA conversacional, facilitando respuestas contextualizadas al preservar el historial de diálogo a través de las interacciones del usuario. Esto permite a la IA proporcionar respuestas coherentes y contextualmente relevantes, mejorando la experiencia del usuario al hacer que la conversación resulte más natural y atractiva.
Por último, la función lambda_handler formatea y devuelve esta respuesta como un objeto JSON estructurado, garantizando la compatibilidad con las aplicaciones web mediante las cabeceras CORS adecuadas y un código de estado HTTP estándar.
A continuación, puedes encontrar el código completo de la función Lambda.
import os
import boto3
import json
boto3_session = boto3.session.Session()
region = boto3_session.region_name
# create a boto3 bedrock client
bedrock_agent_runtime_client = boto3.client('bedrock-agent-runtime',region_name="us-east-1")
def retrieveAndGenerate(question, kbId, model_arn, sessionId=None):
if sessionId != "None":
return bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': question
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn
}
},
sessionId=sessionId
)
else:
return bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': question
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn
}
}
)
def lambda_handler(event, context):
# Extract the question and session ID from the event
question = event["queryStringParameters"]["question"]
try:
session_id = event["queryStringParameters"]["session_id"]
except:
session_id = "None"
# Assuming you've set the KNOWLEDGE_BASE_ID as an environment variable in your Lambda function
kb_id = os.environ["KNOWLEDGE_BASE_ID"]
# Specify the model ID and construct its ARN. Update these placeholders as needed.
model_id = "anthropic.claude-v2"
region = "us-east-1"
model_arn = f'arn:aws:bedrock:{region}::foundation-model/{model_id}'
# Call the retrieve and generate function
response = retrieveAndGenerate(question, kb_id, model_arn, session_id)
# Extract the generated text and session ID from the response
generated_text = response['output']['text']
session_id = response.get('sessionId', '')
headers = {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": True
}
# Return the response in the expected format
return {
'statusCode': 200,
'headers': headers,
'body': json.dumps({
"question": question.strip(),
"answer": generated_text.strip(),
"sessionId": session_id
}, ensure_ascii=False)
}
Al desplegar la infraestructura Serverless (serverless deploy), obtenemos una dirección API que podemos utilizar para interactuar con nuestro agente de IA:
https://<API ID>.execute-api.us-east-1.amazonaws.com/dev/?question=<your question>&session_id=<your session ID>
Voiceflow Frontend
Para integrar perfectamente nuestra API en una interfaz de chatbot, empleamos Voiceflow junto con los servicios de AWS. Esta potente combinación garantiza que nuestro chatbot no solo reciba a los usuarios con calidez, sino que también responda de forma inteligente a sus consultas e integre respuestas alternativas en caso de que fallen las solicitudes de API.
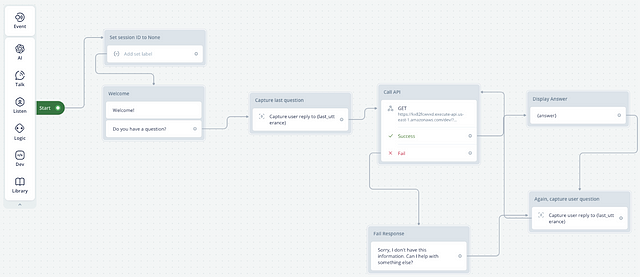
Al iniciar una conversación, el usuario recibe un amistoso mensaje de bienvenida del chatbot. A continuación, el chatbot espera la respuesta del usuario y la captura para una acción posterior. Esta entrada actúa como disparador para el bloque de solicitud GET, preconfigurado en Voiceflow para llegar a nuestra API externa, el punto final de nuestra función AWS Lambda. Una vez recibida la consulta del usuario, el bloque de solicitud GET la envía a nuestra función Lambda, donde se genera una respuesta adecuada que se envía de vuelta a través de nuestra API. Si la llamada a la API tiene éxito, el siguiente bloque de Voiceflow mostrará la respuesta de la función Lambda directamente al usuario.
Sin embargo, si hubiera algún problema en la obtención de la respuesta, Voiceflow está diseñado para manejar estas anomalías con elegancia. Se crea un mensaje de error que informa al usuario del problema y le invita a continuar la conversación. Este cuidadoso diseño garantiza que el chatbot siga siendo atractivo y útil, incluso cuando surgen circunstancias imprevistas. Tras una respuesta satisfactoria, el usuario puede formular una nueva pregunta. En las siguientes llamadas a la API, se transmite el identificador de sesión generado durante la interacción inicial, lo que garantiza una conversación fluida y coherente al mantener el contexto del viaje del usuario.
Conclusión
Hemos llegado al final de nuestro exhaustivo viaje a través de la creación de un agente de IA generativa a escala empresarial con AWS Bedrock. Desde la configuración de una interfaz de chatbot acogedora en Voiceflow, hasta los intrincados procesos de back-end que implican AWS Lambda, API Gateway, Bedrock y Knowledge Bases, hemos explorado un enfoque de desarrollo de pila completa que prioriza la seguridad y el manejo eficiente de los datos. Hemos visto cómo almacenar y recuperar información con los servicios de AWS, y cómo entrelazar estos elementos en una experiencia conversacional sin fisuras utilizando el marco Serverless.
El tutorial te ha equipado con los conocimientos prácticos para implementar datos propios en interacciones de IA, garantizando un diálogo continuo y consciente del contexto con la administración de sesiones. Este conocimiento establece una base sólida para crear agentes de IA inteligentes que no solo entienden y responden a las consultas de los usuarios, sino que lo hacen con una gran conciencia de la seguridad y la gobernanza de los datos empresariales.
Sigue mi página de Instagram, LinkedIn o visita mi página web https://www.pairrot.eu/ para obtener más contenido relacionado con la IA.
The post Cómo crear agentes de IA generativa a escala empresarial con AWS Bedrock: Una guía completa first appeared on Planeta Chatbot.
]]>The post Componentes de una aplicación de IA generativa first appeared on Planeta Chatbot.
]]>El corazón de la innovación: Modelos básicos
En el núcleo de cualquier aplicación de IA generativa se encuentra el modelo base. A diferencia de los modelos tradicionales de machine learning diseñados para tareas concretas, los modelos básicos se entrenan en conjuntos de datos amplios y diversos. Esta formación les permite comprender y generar contenidos en diversos ámbitos, desde el lenguaje matizado hasta elementos visuales complejos. Los grandes modelos lingüísticos (LLM), un subconjunto de los modelos básicos, utilizan este enfoque y se entrenan en amplios datos de texto para realizar tareas como la generación de texto, el resumen y la interacción con chatbot.
Salvando las distancias: interfaces y parámetros de inferencia
Para aprovechar la potencia de un modelo básico, es esencial disponer de una interfaz. Esta interfaz, a menudo una API, sirve de conducto entre la aplicación y el modelo, facilitando las interacciones basadas en preguntas y la devolución de respuestas de inferencia. La eficacia de estas interacciones puede mejorarse significativamente mediante parámetros de inferencia cuidadosamente elegidos, que guíen al modelo para producir resultados adaptados a casos de uso específicos.
Personalización mediante conjuntos de datos empresariales
El potencial de la IA generativa aumenta cuando se aplica a retos específicos de la empresa. Mediante la incorporación de conjuntos de datos empresariales, los modelos de base pueden generar resultados que no sólo se asemejan a los humanos, sino que también están profundamente alineados con las necesidades únicas de una organización. Esta personalización se apoya en tecnologías de incrustación y bases de datos vectoriales, que permiten la recuperación eficiente de información semánticamente similar basada en las indicaciones del usuario.
El papel de las bases de datos vectoriales y las incrustaciones
En la intersección de la inteligencia artificial y la recuperación de datos, las bases de datos vectoriales destacan en el almacenamiento y la búsqueda de miles de millones de vectores de alta dimensión. Estos vectores, creados mediante un proceso conocido como incrustación, representan palabras y entidades de una forma que captura sus relaciones semánticas. La incrustación transforma los datos en vectores que los modelos de IA pueden entender, lo que les permite reconocer el contexto y el significado más allá de las simples coincidencias de texto.
Las bases de datos vectoriales utilizan estas incrustaciones para realizar búsquedas de similitud ultrarrápidas, esenciales para aplicaciones como la generación aumentada de recuperación (RAG). Esto permite a la IA encontrar y recuperar con eficacia la información pertinente, mejorando la precisión y contextualidad de los contenidos generados. La combinación de bases de datos vectoriales e incrustaciones mejora significativamente la capacidad de la IA para interactuar con grandes cantidades de información e interpretarlas, lo que supone un salto adelante en las capacidades de la IA.
Inteligencia artificial conversacional y almacenes de historial
Para las aplicaciones de IA conversacional, la gestión del historial de diálogos es crucial. Un almacén de historial de avisos permite la persistencia del contexto de la conversación, garantizando la continuidad y la coherencia de las interacciones. Este componente es vital para las aplicaciones que requieren conversaciones de varios turnos, ya que ayuda a mantener una memoria a largo plazo del diálogo.
Interfaces de usuario: La puerta de entrada a la IA generativa
La interfaz de usuario, ya sea una aplicación web o una aplicación móvil, desempeña un papel fundamental a la hora de hacer accesible la IA generativa. Es aquí donde se construyen y envían las instrucciones al modelo base, y donde se procesan las respuestas recibidas y se presentan al usuario. Una interfaz bien diseñada garantiza una experiencia de usuario fluida e intuitiva, gestionando eficazmente los fallos y las consecuencias imprevistas.
Gobernanza y seguridad: La base de la confianza
Crear una aplicación de IA generativa no consiste sólo en aprovechar tecnologías potentes, sino también en hacerlo de forma responsable. Las medidas de gobernanza y seguridad son esenciales para garantizar que las aplicaciones no sólo sean eficaces, sino también seguras, responsables y dignas de confianza. Desde la gestión del acceso hasta la supervisión de las interacciones, cada paso debe guiarse por una gobernanza estricta y unos protocolos de seguridad sólidos.
Conclusión
Los componentes de una aplicación de IA generativa forman un complejo ecosistema que aúna tecnología, datos e interacción con el usuario. Desde los modelos fundacionales de su núcleo hasta las medidas de gobernanza y seguridad que garantizan su uso seguro, cada elemento desempeña un papel crucial a la hora de liberar todo el potencial de la IA generativa. A medida que seguimos explorando e innovando en este ámbito, la comprensión de estos componentes resulta esencial para cualquiera que desee aprovechar el poder transformador de la IA.
Para obtener más información sobre la IA, sigue mi página de Instagram lorevanoudenhove.ai, LinkedIn o visite mi sitio web https://www.pairrot.eu/.
The post Componentes de una aplicación de IA generativa first appeared on Planeta Chatbot.
]]>