The post Construye clasificadores de Machine Learning sin datos ni entrenamiento con Humingbird first appeared on Planeta Chatbot.
]]>Pero, ¿por qué es tan difícil empezar? Te ahorraré el ensayo de cuatro páginas y te daré las SparkNotes:
- El machine learning por sí mismo es un reto para construir porque requiere codificación de alto nivel + matemáticas (no siempre, pero este es el caso la mayoría de las veces). Un desarrollador medio tiene que enfrentarse no a una, sino a dos curvas de aprendizaje.
- La gran dependencia de enormes conjuntos de datos (y me refiero a conjuntos de datos MASIVOS). Los modelos de machine learning requieren del orden de 50K a 100K muestras únicas para entender un problema. En la mayoría de los casos, la recopilación de datos no supone un gran problema si se quiere trabajar en problemas muy habituales; sin embargo, si el problema se convierte en algo único, resulta muy difícil recopilar todos estos datos.
- El entrenamiento de los modelos lleva demasiado tiempo. Incluso para tareas básicas, puedes encontrarte entrenando un modelo durante horas en un procesador de gama alta. En gran medida, esto no es factible para los desarrolladores.
Entonces, ¿cómo podemos solucionar esto? ¿Y si pudiéramos eliminar la necesidad de big data, suprimir el entrenamiento y ofrecer a los desarrolladores una experiencia sencilla sin código y con poco código? Te presentamos a Humingbird.
Humingbird: La forma más sencilla de iniciarse en el machine learning
En primer lugar, me gustaría dar un pequeño rodeo y volver a hablar de Humingbird.
Antes de que existiera Stripe, los pagos online eran uno de los proyectos más confusos en los que trabajar como desarrollador (para los que no estén familiarizados, Stripe es una herramienta para desarrolladores que hace que los pagos online sean sencillos). Había que ponerse en contacto con un banco, negociar un acuerdo, obtener la aprobación y trabajar con sus sistemas heredados. En resumen, era una barrera enorme incluso para aceptar un simple pago en línea para las empresas.
Entonces apareció Stripe, y podías pegar un pequeño programa de 6 líneas en tu backend para aceptar pagos online. Sin aplicación, sin negociaciones, simplemente plug and play. Hoy en día, Stripe impulsa la gran mayoría de los pagos en Internet, desde las grandes empresas hasta los proyectos desarrollados a pequeña escala.
¿Por qué estoy hablando de pagos? ¿No era este un blog sobre machine learning?
Aunque parezca una locura, creo que el machine learning todavía está en los «viejos tiempos» de los pagos en línea y no tenemos nada parecido a un servicio simple de plug and play. En otras palabras, no tenemos el equivalente de Stripe en machine learning.
Esta es la intención de Humingbird: una experiencia de machine learning altamente simplificada que simplemente funciona desde el principio. Sin largos ciclos de recogida de datos, ajuste de modelos, entrenamiento y codificación complicada.
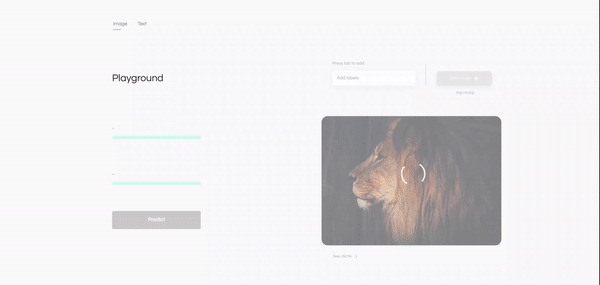
Humingbird es una plataforma para que los desarrolladores construyan clasificadores de machine learning personalizables:
- Poco o nada de código.
- Sin datos (no una pequeña cantidad, literalmente sin datos).
- Sin entrenamiento del modelo.
Pero en lugar de hablar de ello, ¡comparemos algunos ejemplos comunes!
Tareas comunes de machine learning: Humingbird frente al resto
Veamos algunos ejemplos de cómo Humingbird proporciona una simplicidad de siguiente nivel en comparación con las opciones comunes.
MNIST: Humingbird frente a TensorFlow y PyTorch
MNIST es una tarea común de nivel de entrada para las personas que aprenden el aprendizaje de máquinas. La tarea es simple: dado un dígito escrito a mano (como una imagen), predecir qué número es. Te comparto el código necesario para cada uno de los casos en los siguientes enlaces:
Humingbird no requiere preprocesamiento de datos, entrenamiento, recogida de datos ni una programación complicada. Pero, ¿y si quisiéramos predecir también un «10» escrito a mano? Todo lo que tenemos que hacer es añadir la etiqueta que podrás encontrar aquí.
Reseñas de IMDb: Humingbird vs TensorFlow y PyTorch
Otra tarea común en el machine learning es el conjunto de datos de críticas de películas de IMDb. Esta tarea se utiliza comúnmente para predecir el sentimiento en un pasaje de texto y hasta el día de hoy se utiliza como punto de referencia. Vamos a comparar los frameworks comunes y Humingbird:
Ya te has hecho una idea. Con Humingbird, puedes construir clasificadores de machine learning a medida en un abrir y cerrar de ojos.
Mi objetivo: hacer que el machine learning sea accesible y sencillo
Como probablemente puedes adivinar, mi motivación para construir Humingbird es muy simple: Quiero que el machine learning sea más sencillo para todo el mundo, aunque sea en lo más simple.
Si quieres saber más sobre el proyecto, dirígete a este post.
Aquí puedes leer los documentos y empezar.
Más contenido en PlainEnglish.io. Suscríbete a nuestra newsletter semanal gratuita. Siguenos en Twitter y LinkedIn. Echa un vistazo a nuestro Community Discord y únete a nuestro Talent Collective.
The post Construye clasificadores de Machine Learning sin datos ni entrenamiento con Humingbird first appeared on Planeta Chatbot.
]]>The post Despliegue de un filtro de modelo de lenguaje sin datos utilizando Humingbird first appeared on Planeta Chatbot.
]]>The post Despliegue de un filtro de modelo de lenguaje sin datos utilizando Humingbird first appeared on Planeta Chatbot.
]]>The post Un chatbot de texto e imagen de 5 minutos con cero datos usando Humingbird first appeared on Planeta Chatbot.
]]>- La integración de la IA en el backend de tu proyecto se ha hecho cada vez más popular en los últimos años. Muchos sectores han adoptado la IA para mejorar la productividad, reducir los costes y agilizar los procesos de tus aplicaciones. Una de estas formas en que la IA puede mejorar la experiencia de una aplicación es mediante el uso de un Chatbot. Un Chatbot es un agente automatizado que puede interactuar con un usuario hablando con él, respondiendo a sus peticiones y, en general, siendo útil. En otras palabras, los Chatbots pueden hacer que la experiencia del usuario sea mucho más natural y fluida.
La parte desafortunada es que los chatbots pueden llevar mucho tiempo para construir, diseñar y desplegar. Recopilar datos de entrenamiento, construir un modelo o incluso dedicar tiempo a aprender un servicio puede llevar mucho tiempo. Afortunadamente, Humingbird está aquí para salvar el día. Utilizando el método Text de Humingbird para la clasificación de textos, podemos aplicar las mismas técnicas para construir un chatbot. Para aquellos que no conozcan Humingbird, les recomiendo que consulten la entrada original del blog aquí; el resumen es que puedes construir fácilmente clasificadores ML sin datos ni entrenamiento.
Dicho esto, creo que es hora de construir un chatbot:
Creación de un chatbot con capacidad de reconocimiento de imágenes

El esquema de nuestro proyecto es sencillo: vamos a construir un chatbot para una tienda ficticia que vende helados. Este chatbot será capaz de:
- Responder a las preguntas generales de los usuarios sobre los helados
- Reconocer imágenes de diferentes sabores de helado y responder en consecuencia
- Ser capaz de retroceder si el chatbot no tiene una puntuación de confianza lo suficientemente alta
Nota al margen: Aunque se trata de un ejemplo sencillo y algo divertido, el esquema de este proyecto podría utilizarse en muchas aplicaciones. La fusión de las habilidades visuales y conversacionales en una sola plataforma podría ayudar a automatizar una serie de tareas diferentes, como la atención al cliente automatizada.
Para continuar con el resto de este tutorial, vamos a instalar el paquete Humingbird con el comando:
pip install humingbird
Paso 1: Construir nuestro sistema de reconocimiento de intenciones
En primer lugar, tenemos que empezar a construir un sistema de reconocimiento de intenciones. Para los que no estén familiarizados, el reconocimiento de intenciones es la tarea de predecir lo que «significa» una consulta. En otras palabras, establecemos un mapa predefinido de lo que podría decirse a nuestro chatbot dada la solicitud.
Para nuestro chatbot de helados, vamos a utilizar las siguientes intenciones:
# intents[greeting, goodbye, menu, prices, start_order]
Todos ellos son bastante autoexplicativos en cuanto a cuáles serán sus «roles».
Para construir nuestro reconocedor de intenciones, vamos a utilizar el código que puedes encontrar en esta URL.
Esto nos dará la siguiente salida:
[
{
"className": "menu",
"score": 0.84,
}, {
"className": "greeting",
"score": 0.09
},
{
"className": "prices",
"score": 0.06,
}, {
"className": "goodbye",
"score": 0.01
}, {
"className": "start_order",
"score": 0.01
}
]
¡Impresionante! Nuestro sistema de reconocimiento de intención predijo correctamente que la salida era que el usuario quería ver el menú. Hay un problema: ¡no tenemos ninguna respuesta!
Vamos a construirlo.
Paso 2: Construir un sistema de respuesta
No te preocupes, podemos usar el siguiente diccionario de Python para nuestra biblioteca de respuestas:
Ahora podemos construir una función sencilla para reconocer las intenciones y responder en consecuencia. En este enlace te comparto el código.
Lo que generará una respuesta de nuestro chatbot, como por ejemplo:
Welcome! What can i help you with?
En este punto, tenemos todo lo que necesitamos para un chatbot basado en texto. Podemos mejorar nuestro chatbot añadiendo más intenciones y mejores respuestas.
Pero queremos añadir una pieza más: capacidades visuales.
Paso 3: Añadir capacidades visuales a nuestro chatbot
Hasta este paso, hemos construido un simple chatbot basado en texto. Aunque hemos ahorrado mucho tiempo y hemos abstraído mucho código, no hemos hecho nada diferente de lo que pueden hacer la mayoría de las plataformas de chatbot.
Vamos a dar un paso en una dirección diferente añadiendo un componente de comprensión visual a nuestro chatbot. En nuestro sencillo ejemplo de un chatbot de una tienda de helados, vamos a reconocer diferentes sabores de helado y responder con un enlace de compra ficticio.
Para hacer esto con Humingbird, podemos utilizar el siguiente fragmento de código. Puedes utilizar esta imagen:

Y nuestro fragmento de código volverá:
[ {
"className": "strawberry ice cream"
"score: 0.93
}, {
"className": "vanilla ice cream",
"score": 0.05,
}, {
"className": "chocolate ice cream"
"score": 0.02
}]
Impresionante. Hemos hecho la parte más difícil con sólo unas pocas líneas de código. Ahora, vamos a ponerlo todo junto añadiendo algunos «intentos visuales» con una función visual_intent_detection. ¿Cómo hacerlo? Utiliza el código que te comparto en este enlace.
Que devolverá (con la imagen de ejemplo de arriba:
Great choice!
Here is the checkout link: https://www.fakeicecream.com/checkout/strawberry
¡Lo hemos hecho!
Conclusión
En este tutorial, construimos un chatbot muy básico basado en texto e imágenes usando Humingbird. Nos ahorramos toneladas de tiempo al no recopilar datos, nos abstrajimos de mucho código complicado y no necesitamos ningún entrenamiento para construir este modelo multimodal. Aunque este chatbot podría mejorarse y el concepto es un poco tonto, los chatbots que responden textual y visualmente tienen una enorme aplicación. ¿Imagina que pudiéramos construir un chatbot visual para que los estudiantes entendieran imágenes médicas, o para que detectaran puntos de referencia y aprendieran sobre su historia?
Espero que este tutorial haya sido útil para construir una aplicación divertida con Humingbird. No dudes en compartir este artículo. Si quieres ver un tutorial sobre cómo implementar este sistema, ¡déjame un comentari
The post Un chatbot de texto e imagen de 5 minutos con cero datos usando Humingbird first appeared on Planeta Chatbot.
]]>