The post Centrarse en el impacto: Errores y niveles de madurez en el análisis de datos first appeared on Planeta Chatbot.
]]>- Asegurarse de que cada problema de datos se trata como un problema de negocio.
- Centrarse en el impacto y los resultados de los indicadores clave de rendimiento más que en el rendimiento.
- Aumentar la madurez de los equipos con el tiempo y no saltarse lo básico.
Exploremos estas áreas problemáticas subyacentes con más detalle.
Conocimiento del dominio, relevancia empresarial y expectativas
Uno de los errores más comunes que he encontrado es la desconexión entre los objetivos de un equipo de datos y los objetivos empresariales generales. Sin una comprensión clara del contexto y los requisitos de la empresa, las iniciativas de datos no suelen aportar un valor significativo. Esta falta de alineación provoca frustración en ambos extremos: las partes interesadas se sienten decepcionadas por los resultados y los equipos de datos lidian con directrices vagas. En la mayoría de los casos, cuando los productos o equipos de datos fracasan, no lo hacen por razones técnicas, sino porque han entregado algo que no ha dado resultados reales para las partes interesadas.
Como resumió Leandro Carvalho en su artículo Data Product Canvas:
«El éxito de una cultura impulsada por los datos depende de la definición y aplicación de estrategias, no de tecnologías. Por eso es importante dejar claro que los productos de datos son un problema de dominio empresarial, no tecnológico.»
En el análisis de datos, la verdadera esencia de las necesidades empresariales a veces queda oculta bajo peticiones superficiales. Es crucial profundizar, fomentando una cultura de investigación para desenterrar las causas profundas de estas necesidades. Una metodología probada consiste en preguntar continuamente «por qué» hasta descubrir el problema subyacente. Por ejemplo, cuando alguien solicita un nuevo producto de datos, profundizar con preguntas como «¿por qué necesita/quiere/no puede X?» puede dar lugar a valiosos conocimientos. A través de este proceso iterativo, podemos descubrir los verdaderos retos y requisitos a los que se enfrentan las distintas unidades de negocio o grupos de productos. Al comprender estos matices, los equipos de datos pueden adaptar sus soluciones para abordar eficazmente las necesidades específicas de la empresa.
Otro obstáculo que puede impedir el progreso es la ausencia de conocimientos especializados en los equipos de datos. Ya sea debido a silos organizativos o a un fallo a la hora de integrar el conocimiento del sector en el proceso analítico, esta deficiencia puede obstaculizar la capacidad de un equipo para generar perspectivas procesables. Sin un conocimiento profundo del sector y de la dinámica empresarial, los análisis de datos pueden pasar por alto factores críticos o malinterpretar tendencias. Esta necesidad ha llevado al auge de las arquitecturas de malla de datos/cubo y radio en varios sectores, como JP Morgan, Delivery Hero e Intuit. La idea es sencilla: mientras que la infraestructura y las plataformas de datos se proporcionan de forma centralizada (hub), la incorporación del conocimiento empresarial a los productos de datos sólo puede funcionar haciendo que estos equipos empresariales sean responsables de ellos de forma descentralizada (spokes). Esto fomenta la colaboración y la fiabilidad.
Los números sólo tienen sentido en su contexto. Cuando los números no tienen un contexto adecuado, incluso los mejores científicos de datos del mundo pueden tratarlos sólo como números al final. Por lo tanto, no hay forma de evitar hacer de esto la máxima prioridad cuando se trabaja en análisis: sea lo que sea en lo que se trabaje tiene que ofrecer resultados relevantes para (y junto con) las partes interesadas para resolver un problema. Nadie aplaude lo bonito.
Acceso a los datos y calidad de los datos
La segunda área de problemas se centra en los propios datos. Uno de los retos a los que se enfrentan a menudo los analistas es garantizar la fiabilidad de los datos que utilizan. El acceso a datos precisos es vital para un análisis significativo, pero muchos analistas se enfrentan a obstáculos relacionados con la calidad y accesibilidad de los datos. Cuanto mayor es el entorno, mayor es el riesgo de no saber qué datos existen o a quién pedirlos, y mayor es el riesgo de que los datos no estén en buen estado para analizarlos.
La confianza es clave. Cuando se considera que los datos en bruto no son fiables, se ponen en duda los resultados de los análisis, lo que provoca el escepticismo de las partes interesadas y reduce las posibilidades de que el trabajo de los equipos de datos conduzca a resultados significativos. Por lo tanto, establecer una gobernanza clara de los datos es crucial: los equipos de datos tienen que saber a quién pertenecen los datos y dónde pueden encontrarlos. Una propiedad clara también puede contribuir a la calidad de los datos. Cuando los analistas no están seguros de en qué datos pueden confiar más para su proyecto, deben pedir ayuda a las partes interesadas. Es probable que tengan una opinión sobre qué datos tienen sentido para su dominio y cuáles no.
Madurez y participación de las partes interesadas
En tercer lugar, consideremos la aceptación de las partes interesadas. A todas las personas que trabajan con datos les encantan los cuadros de mando, los modelos de machine learning y (recientemente) la exploración de casos de uso de GenAI. Esto coincide con la perspectiva intrínseca de un analista, pero ilustra el riesgo de centrarse en las cosas equivocadas. En su afán por mostrar sofisticación, los equipos de datos tienden a pasar por alto las etapas fundamentales de la madurez. Sin una base sólida, los intentos de abordar problemas complejos a menudo se traducen en ineficiencias y oportunidades perdidas de mejoras incrementales. No tiene sentido crear modelos de IA cuando ni siquiera se dispone de informes sencillos.
Aunque el marco de madurez de Gartner es un modelo bien conocido (de descriptivo a prescriptivo), se centra más en las metodologías de análisis de datos que en el proceso de ser un buen socio comercial para las partes interesadas del negocio. Por lo tanto, resumiríamos el nivel de madurez de los equipos de datos de la siguiente manera:

Nivel 1: Informes precisos
Como fundamento básico, los equipos de datos deben ser reconocidos como la organización «a la que acudir» para las necesidades de datos. Esto podría dar lugar a la elaboración de varios informes bien conocidos que actúen como fuente de la verdad para un mayor número de partes interesadas.
Nivel 2: Facilitador de ideas
Una vez que los datos son fiables, los analistas pueden actuar como facilitadores de información para resolver problemas analíticos y empresariales. Ya no se limitan a informar de las cifras, sino que intentan situarlas en un contexto significativo, lo que finalmente conduce a una toma de decisiones basada en los datos.
Nivel 3: Romper el cuello de botella
El inconveniente de los buenos datos y los analistas inteligentes es que se hacen populares y reciben demasiadas peticiones. Ese es un buen momento para ampliar las capacidades, invertir en funciones de autoservicio y considerar cambios organizativos, así como una mejor infraestructura.
Nivel 4: Socio empresarial proactivo
La última etapa hace que el equipo de datos pase de reactivo a proactivo. Es el momento de empezar a generar hipótesis para desafiar y apoyar a las partes interesadas, en lugar de dejar que dicten lo que importa.
A medida que los equipos de datos crecen con el tiempo, es importante ceñirse a lo básico: empezar poco a poco y centrarse en la confianza. Hay menos posibilidades de que la funcionalidad de autoservicio sea apreciada si los datos subyacentes no son fiables, o si un equipo no es visto como un socio de datos fiable. Reaccionar a las necesidades de la organización y convertirse con el tiempo en una organización de datos proactiva es el último paso.
Conclusión
Intentar resolver los problemas analíticos de una empresa puede resultar abrumador. Especialmente en las grandes organizaciones, es imposible resolver los problemas de calidad de datos de forma aislada. Los equipos deben centrarse más en lo que es posible influir directamente en lugar de abordar cosas que dependen demasiado de factores externos.
También es necesario asegurarse de que cada problema de datos se trata como un problema de negocio y no sólo como un problema tecnológico. Los productos de datos deben estar relacionados con cuestiones empresariales concretas e integrados en procesos empresariales relacionados.
Y los equipos deben mostrar los KPI de impacto y los resultados, en lugar de limitarse a los productos. El valor de los productos de datos nunca debe medirse sólo por el resultado. En lugar de eso, hay que ponerle un precio adecuado: hacer visible qué ingresos adicionales se han generado o en qué se ha influido. Y destacar los costes y el tiempo ahorrado.
Por último, es fundamental garantizar que la madurez de los equipos crece con el tiempo y que los fundamentos están sólidamente asentados. El éxito de las aplicaciones (de IA) depende de la solidez y la calidad de los datos.
The post Centrarse en el impacto: Errores y niveles de madurez en el análisis de datos first appeared on Planeta Chatbot.
]]>The post Cómo utilizar la API ChatGPT para la interacción directa desde Colab o Databricks first appeared on Planeta Chatbot.
]]>Hoy, sin embargo, exploraremos una alternativa: la API ChatGPT. Este artículo se divide en tres secciones principales:
- Configura tu cuenta OpenAI y crea una clave API
- Establece la conexión general desde Google Colab
- Prueba diferentes peticiones: generación de texto, creación de imágenes & corrección de errores
Nota: Aunque este tutorial se ha realizado en Google Colab (gratuito), puede que quieras probar otros entornos. Por ejemplo, todo el código se aplicó también en Databricks.
1. Configura tu cuenta OpenAI y crea una clave API
Para interactuar con los algoritmos de GPT, necesitas registrarte en una cuenta OpenAI (gratuita): https://platform.openai.com/signup/
Una vez que te hayas registrado y dado de alta, necesitarás crear una clave API que te permitirá enviar peticiones a OpenAI desde servicios de terceros como Google Colab o Databricks. Navega hasta la sección «Ver clave de API» a través del menú de usuario, o utiliza el siguiente enlace: https://platform.openai.com/account/api-keys.
En esta sección, simplemente haz clic en «Crear nueva clave secreta» y guarda la clave creada en algún lugar de tu ordenador (¡la necesitarás pronto!):
Ten en cuenta que la API ChatGPT ofrece un uso de prueba gratuito (a partir de hoy) con solicitudes y tokens limitados por minuto. Consulte los límites de velocidad a continuación [1]:
- Usuarios de prueba gratuitos: 20 RPM 40000 TPM
- Usuarios de pago por uso (primeras 48 horas): 60 RPM 60000 TPM
- Usuarios de pago (después de 48 horas): 3500 RPM 90000 TPM
(RPM = peticiones por minuto; TPM = tokens por minuto)
2. Establecer la conexión general desde Colab
La forma más fácil y directa de probar la API es utilizar Google Colaboratory («Colab»), que es algo así como «un entorno gratuito de cuadernos Jupyter que no requiere configuración y se ejecuta completamente en la nube». Aunque hay muchos entornos más profesionales que quizá quieras explorar (por ejemplo, Databricks), creo que Colab no es un mal servicio para dar tus primeros pasos con la API ChatGPT.
Para configurar un entorno básico para ChatGPT dentro de Colab puedes seguir los siguientes pasos:
- Abre https://colab.research.google.com/ y regístrate para obtener una cuenta gratuita
- Crear un nuevo cuaderno en Colab
- Instala y utiliza el paquete openai:
pip install openai
Para ejecutar una simple petición de chat a la API usando el modelo turbo GPT 3.5 (ver otros modelos disponibles en su documentación enlazada al final de este artículo), similar a lo que conoces de la interfaz web de OpenAI, puedes simplemente ejecutar las siguientes líneas de código en tu bloc de notas:
import os
import openai
openai.api_key = «please-paste-your-API-key-here»
openai.ChatCompletion.create(
model=»gpt-3.5-turbo»,
messages=[
{«role»: «user», «content»: «Hello ChatGPT, does this work?»}
]
)
En cuanto ejecutes el comando en Colab, recibirás como respuesta un objeto JSON que contiene la respuesta esperada (Ha sido fácil, ¿verdad?):
¡Hola! Como modelo lingüístico de IA, no tengo el contexto de a qué se refiere «esto». ¿Podrías especificar a qué te refieres para que pueda ayudarte mejor?
<OpenAIObject chat.completion id=chatcmpl-70ErnAfGGwU7GhMXzCcLGyUvr4hA2 at 0x7f097f0a5f40> JSON: {
«choices»: [
{
«finish_reason»: «stop»,
«index»: 0,
«message»: {
«content»: «Hello! As an AI language model, I don’t have the context of what \»this\» refers to. Could you please specify what you are referring to so I can assist you better?»,
«role»: «assistant»
}
}
],
«created»: 1680291503,
«id»: «chatcmpl-70ErnAfGGwU7GhMXzCcLGyUvr4hA2»,
«model»: «gpt-3.5-turbo-0301»,
«object»: «chat.completion»,
«usage»: {
«completion_tokens»: 38,
«prompt_tokens»: 17,
«total_tokens»: 55
}
}
Además, el objeto JSON proporciona información sobre el número de tokens utilizados y el motivo del fin de la solicitud. Si sólo deseas imprimir la respuesta de texto, puedes acceder a este elemento modificando ligeramente tu código:
import os
import openai
openai.api_key = «please-paste-your-API-key-here»
response = openai.ChatCompletion.create(
model=»gpt-3.5-turbo»,
messages=[
{«role»: «user», «content»: «Hello ChatGPT, does this work?»}
]
)
print(response.choices[0].message.content)
3. Probar diferentes peticiones: generación de texto, creación de imágenes y corrección de errores
Si estás tan emocionado como yo cuando descubrí esto, puedes empezar a enviar un montón de peticiones diferentes a la API. Una forma útil de modularizar tu código es crear algunas funciones útiles que quieras llamar para diferentes propósitos. Déjame darte algunas ideas.
Función para chatear con ChatGPT
El siguiente código simplemente resume el trabajo hecho hasta ahora en una función invocable que te permite hacer cualquier petición a GPT y obtener sólo la respuesta de texto como resultado.
import os
import openai
openai.api_key = «please-paste-your-API-key-here»
def chatWithGPT(prompt):
completion = openai.ChatCompletion.create(
model=»gpt-3.5-turbo»,
messages=[
{«role»: «user», «content»: prompt}
]
)
return print(completion.choices[0].message.content)
¿Crees que tiene sentido aprender python? ¡Preguntemos a GPT!
chatWithGPT(«is it a good idea to start learning python?»)
Como modelo de lenguaje de IA, no puedo dar opiniones personales, pero sí puedo decir que Python es un lenguaje de programación popular y muy utilizado, muy apreciado tanto por principiantes como por desarrolladores experimentados. Cuenta con el apoyo de una amplia comunidad, un gran número de bibliotecas y una sintaxis sencilla que lo hace fácil de entender para los principiantes. Es útil para diversas aplicaciones, como el análisis de datos, el desarrollo web, el aprendizaje automático y mucho más. Por lo tanto, podría ser una buena idea empezar a aprender Python si quieres seguir una carrera en programación o quieres añadir otra habilidad a tu currículum.
Función para corregir errores en tu código
Otro caso de uso de ChatGPT es obtener ideas para arreglar tu código. Imagina que tu comando Python devuelve un error y quieres obtener consejos sobre qué hacer sin usar Google o StackOverflow:
import os
import openai
openai.api_key = «please-paste-your-API-key-here»
def fixMyCode(code):
completion = openai.ChatCompletion.create(
model=»gpt-3.5-turbo»,
messages=[
{«role»: «user», «content»: «find error in my python script below and fix it: » + code}
]
)
return print(completion.choices[0].message.content)
Verás mi código python ha lanzado un error, y no sé por qué…
fixMyCode(«»»
def some_function():
print(«I’m going to sleep»)
time.sleep(10)
print(«I’m awake again»)
some_function()
«»»)
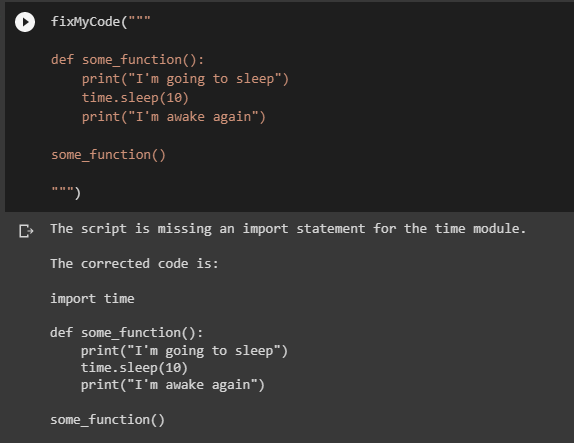
Verás, mi código python ha arrojado un error, y no sé por qué…No es ninguna sorpresa, pero ChatGPT descubrió inmediatamente que me había olvidado de importar el módulo antes de utilizarlo. Esto puede ser muy útil en el día a día, sobre todo cuando puedes pedir ayuda directamente desde el entorno de programación.
Función para crear imágenes
El último caso de uso que me gustaría presentar aquí es la creación de imágenes. La propia petición devuelve un hipervínculo que contiene la imagen. Usando la librería IPhython, puedes mostrar la imagen directamente en tu cuaderno.
import IPython
import os
import openai
openai.api_key = «please-paste-your-API-key-here»
def createImageWithGPT(prompt):
completion = openai.Image.create(
prompt=prompt,
n=1,
size=»512×512″
)
return IPython.display.HTML(«<img src =» + completion.data[0].url + «>»)
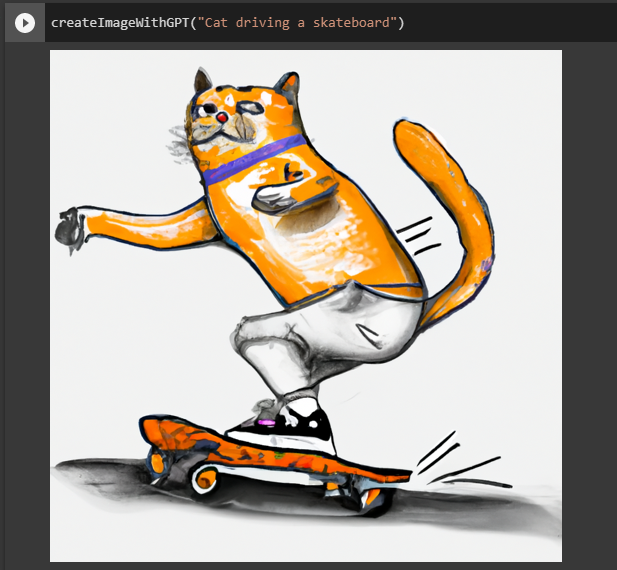
Seamos creativos y pidamos un gato conduciendo un monopatín.
createImageWithGPT(«Cat driving a skateboard»)
Resumen
Con la API ChatGPT, las empresas y los particulares pueden incorporar chatbots a su flujo de trabajo de forma fácil y asequible, sin los conocimientos técnicos o los amplios recursos que suelen ser necesarios. La API también puede utilizarse para crear asistentes virtuales, tutores personales, etc. Recomiendo la documentación puesta a disposición por OpenAI para su API: https://platform.openai.com/docs/api-reference.
En resumen, es fácil utilizar la API en tu entorno de programación. Esto no sólo puede ser útil para la depuración directa de tu código, sino que también ha demostrado tasas de respuesta más estables en comparación con la interfaz web de OpenAI (a veces no disponible). Con la capacidad de entender el lenguaje natural y volverse más inteligente con el tiempo, ChatGPT tiene el potencial de revolucionar la forma en que las empresas interactúan con sus clientes y agilizar sus flujos de trabajo. Pruébelo usted mismo y experimente el futuro de los chatbots.
The post Cómo utilizar la API ChatGPT para la interacción directa desde Colab o Databricks first appeared on Planeta Chatbot.
]]>The post Primeros pasos en la predicción de series temporales de datos con Facebook Prophet first appeared on Planeta Chatbot.
]]>Este artículo pretende eliminar las barreras de entrada para empezar con el análisis de series temporales en un tutorial práctico utilizando una de las herramientas más sencillas, cuyo nombre es Facebook Prophet dentro de Google Colab (¡ambas son gratuitas!). En caso de que quieras empezar inmediatamente, no dudes en saltarte los dos capítulos siguientes, en los que daré una breve introducción a los principios de las series temporales y a Facebook Prophet. Diviértete.
1. Principios generales del análisis de series temporales
Imagínate que eres gerente de una tienda de productos de consumo y deseas predecir la próxima demanda de productos para gestionar mejor la oferta. Un enfoque razonable de machine learning para este escenario es ejecutar algún análisis de series temporales que implica comprender, modelar y hacer predicciones basadas en puntos de datos secuenciales. [1]
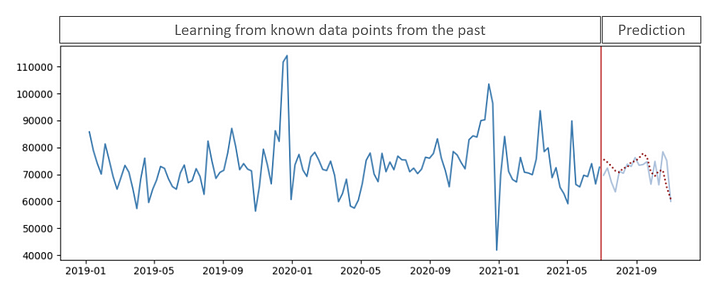
El siguiente gráfico ilustra un desarrollo artificial de la demanda histórica de productos (línea azul oscuro) a lo largo del tiempo, que puede utilizarse para analizar un patrón de series temporales. Nuestro objetivo final sería predecir (línea de puntos rojos) la demanda futura real (línea azul claro) con la mayor precisión posible:
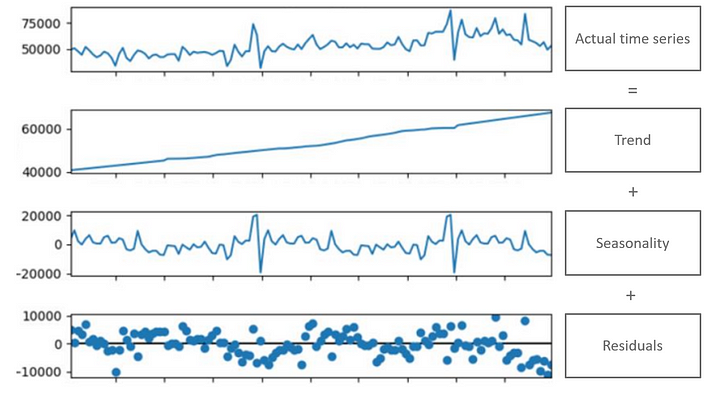
Una serie temporal suele descomponerse en tres componentes principales:
- Tendencia: el movimiento a largo plazo o la dirección general de los datos.
- Estacionalidad: fluctuaciones o patrones que se repiten a intervalos regulares.
- Residual/error: resto o variación sobrante en los datos.
La descomposición de una serie temporal en estos tres componentes, a menudo denominada descomposición aditiva o multiplicativa, permite a los analistas comprender mejor la estructura y las pautas subyacentes. Esta comprensión es esencial para seleccionar modelos de previsión adecuados y realizar predicciones precisas basadas en datos históricos. [2]
2. ¿Qué es Facebook Prophet?
Prophet es una herramienta de código abierto lanzada por el equipo de Data Science de Facebook que produce datos de previsión de series temporales basados en un modelo aditivo en el que se ajusta una tendencia no lineal con efectos de estacionalidad y vacaciones. Los principios de diseño permiten ajustar los parámetros sin mucho conocimiento del modelo subyacente, lo que hace que el método sea aplicable a equipos con menos conocimientos estadísticos. [3]
Prophet es especialmente adecuado para aplicaciones de previsión empresarial, y ha ganado popularidad debido a su facilidad de uso y eficacia en el manejo de una amplia gama de datos de series temporales. Como con cualquier herramienta, hay que tener en cuenta que, aunque Prophet es potente, la elección del método de previsión depende de las características específicas de los datos y de los objetivos del análisis. En general, no está garantizado que Prophet funcione mejor que otros modelos. Sin embargo, Prophet incorpora algunas funciones útiles, como el reflejo del cambio de estacionalidad antes y después de la COVID o el tratamiento de los cierres como vacaciones puntuales.
Para una introducción más detallada por parte de Meta (Facebook), te recomiendo ver el siguiente vídeo en YouTube.
En el siguiente tutorial, implementaremos y utilizaremos Prophet con Python. Sin embargo, ¡también puedes realizar tus análisis con R!
3. Tutorial práctico sobre el uso de Prophet
En caso de que tengas poca experiencia o no tengas acceso a tu entorno de codificación, te recomiendo hacer uso de Google Colaboratory («Colab») que es algo así como «un entorno de Jupyter notebook gratuito que no requiere configuración y se ejecuta completamente en la nube». Si bien este tutorial afirma más sobre la simplicidad y las ventajas de Colab, hay inconvenientes como la potencia de cálculo reducida en comparación con los entornos adecuados en la nube. Sin embargo, creo que Colab puede no ser un mal servicio para dar los primeros pasos con Prophet.
Para configurar un entorno básico de Análisis de Series Temporales dentro de Colab puedes seguir estos dos pasos:
- Abrir https://colab.research.google.com/ y registrarte para obtener una cuenta gratuita
- Crear un nuevo cuaderno dentro de Colab
- Instalar y utilizar el paquete prophet:
pip install prophet
from prophet import Prophet
Carga y preparación de datos
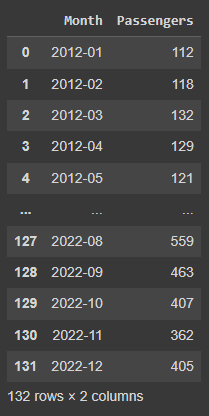
He cargado un pequeño conjunto de datos ficticio que representa la cantidad mensual de pasajeros de una empresa local de autobuses (2012-2023). Puedes encontrar los datos en GitHub.
Como primer paso, cargaremos los datos utilizando pandas y crearemos dos conjuntos de datos separados: un subconjunto de entrenamiento con los años 2012 a 2022 y un subconjunto de prueba con el año 2023. Entrenaremos nuestro modelo de series temporales con el primer subconjunto y trataremos de predecir el número de pasajeros en 2023. Con el segundo subconjunto, podremos validar la precisión más adelante.
import pandas as pd
df_data = pd.read_csv(«https://raw.githubusercontent.com/jonasdieckmann/prophet_tutorial/main/passengers.csv»)
df_data_train = df_data[df_data[«Month»] < «2023-01»]
df_data_test = df_data[df_data[«Month»] >= «2023-01»]
display(df_data_train)
La salida del comando de visualización puede verse a continuación. El conjunto de datos contiene dos columnas: la indicación de la combinación año-mes, así como una columna numérica con el importe de pasajeros en ese mes. Por defecto, Prophet está diseñado para trabajar con datos diarios (o incluso horarios), pero nos aseguraremos de que también se pueda utilizar el patrón mensual.
Descomposición de los datos de entrenamiento
Para comprender mejor los componentes de las series temporales dentro de nuestros datos ficticios, realizaremos una descomposición rápida. Para ello, importamos el método de la biblioteca statsmodels y ejecutamos la descomposición en nuestro conjunto de datos. Nos decidimos por un modelo aditivo e indicamos que un periodo contiene 12 elementos (meses) en nuestros datos. Un conjunto de datos diarios sería period=365.
from statsmodels.tsa.seasonal import seasonal_decompose
decompose = seasonal_decompose(df_data_train.Passengers, model=’additive’, extrapolate_trend=’freq’, period=12)
decompose.plot().show()
Este breve fragmento de código nos dará una impresión visual de las series temporales en sí, pero sobre todo de la tendencia, la estacionalidad y los residuos a lo largo del tiempo:
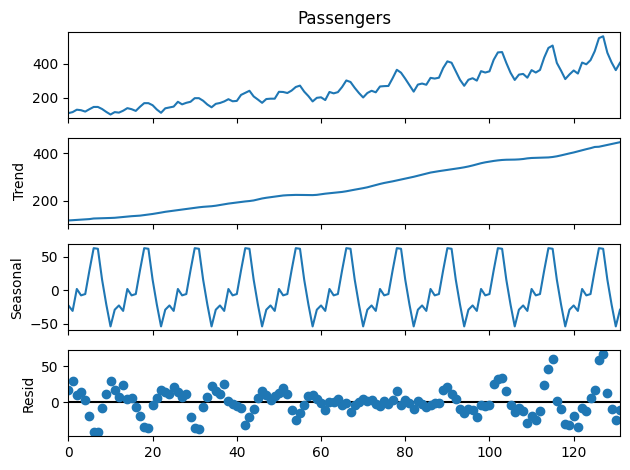
Ahora podemos ver claramente una tendencia al alza significativa en los últimos 10 años, así como un patrón de estacionalidad reconocible cada año. Siguiendo estas indicaciones, cabría esperar que el modelo predijera un nuevo aumento del número de pasajeros tras los picos estacionales del verano del año siguiente. Pero vamos a probarlo: ¡es hora de aplicar el aprendizaje automático!
Ajuste de modelos con Facebook Prophet
Para ajustar modelos en Prophet, es importante tener al menos una columna «ds» (fecha) e «y» (valor que se va a pronosticar). Debemos asegurarnos de que nuestras columnas tienen el mismo nombre.
df_train_prophet = df_data_train
# date variable needs to be named «ds» for prophet
df_train_prophet = df_train_prophet.rename(columns={«Month»: «ds»})
# target variable needs to be named «y» for prophet
df_train_prophet = df_train_prophet.rename(columns={«Passengers»: «y»})
Ahora puedes empezar la magia. El proceso para ajustar el modelo es bastante sencillo. Sin embargo, por favor, echa un vistazo a la documentación para hacerte una idea de la gran cantidad de opciones y parámetros que podríamos ajustar en este paso. Para simplificar las cosas, ajustaremos un modelo sencillo sin más ajustes por ahora, pero ten en cuenta que los datos del mundo real nunca son perfectos: sin duda necesitarás ajustar los parámetros en el futuro.
model_prophet = Prophet()
model_prophet.fit(df_train_prophet)
Eso es todo lo que tenemos que hacer para ajustar el modelo. ¡Hagamos algunas predicciones!
Hacer predicciones
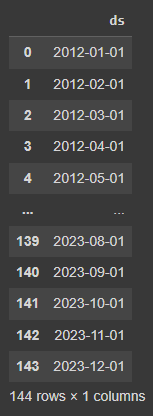
Tenemos que hacer predicciones en una tabla que tenga una columna ‘ds’ con las fechas para las que quieres predicciones. Para configurar esta tabla, utiliza el método make_future_dataframe, y automáticamente incluirá las fechas históricas. De esta forma, podrás ver lo bien que el modelo se ajusta a los datos pasados y predice el futuro. Como manejamos datos mensuales, indicaremos la frecuencia con «freq=12» y pediremos un horizonte futuro de 12 meses («periods=12»).
df_future = model_prophet.make_future_dataframe(periods=12, freq=’MS’)
display(df_future)
Este nuevo conjunto de datos contiene tanto el periodo de entrenamiento como los 12 meses adicionales que queremos predecir:
Para realizar predicciones, basta con llamar al método predict de Prophet y proporcionar el futuro conjunto de datos. El resultado de la predicción contendrá un gran conjunto de datos con muchas columnas diferentes, pero nos centraremos únicamente en el valor predicho yhat, así como en los intervalos de incertidumbre yhat_inferior y yhat_superior.
forecast_prophet = model_prophet.predict(df_future)
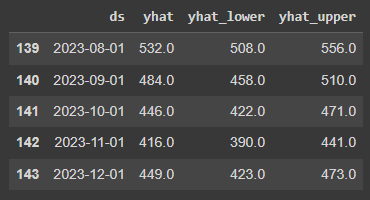
forecast_prophet[[‘ds’, ‘yhat’, ‘yhat_lower’, ‘yhat_upper’]].round().tail()
La tabla siguiente nos da una idea de cómo se genera y almacena el resultado. Para agosto de 2023, el modelo predice un número de pasajeros de 532 personas. El intervalo de incertidumbre (que está fijado por defecto en el 80%) nos indica de forma sencilla que podemos esperar con toda probabilidad una cantidad de pasajeros de entre 508 y 556 personas en ese mes.
Por último, queremos visualizar los resultados para comprender mejor las predicciones y los intervalos.
Visualización de resultados
Para trazar los resultados, podemos utilizar las herramientas de trazado incorporadas en Prophet. Con el método de trazado, podemos mostrar los datos originales de la serie temporal junto con los valores pronosticados.
import matplotlib.pyplot as plt
# plot the time series
forecast_plot = model_prophet.plot(forecast_prophet)
# add a vertical line at the end of the training period
axes = forecast_plot.gca()
last_training_date = forecast_prophet[‘ds’].iloc[-12]
axes.axvline(x=last_training_date, color=’red’, linestyle=’–‘, label=’Training End’)
# plot true test data for the period after the red line
df_data_test[‘Month’] = pd.to_datetime(df_data_test[‘Month’])
plt.plot(df_data_test[‘Month’], df_data_test[‘Passengers’],’ro’, markersize=3, label=’True Test Data’)
# show the legend to distinguish between the lines
plt.legend()
Además del gráfico general de series temporales, hemos añadido una línea de puntos para indicar el final del periodo de entrenamiento y, por tanto, el inicio del periodo de predicción. Además, utilizamos el conjunto de datos de prueba reales que habíamos preparado al principio.
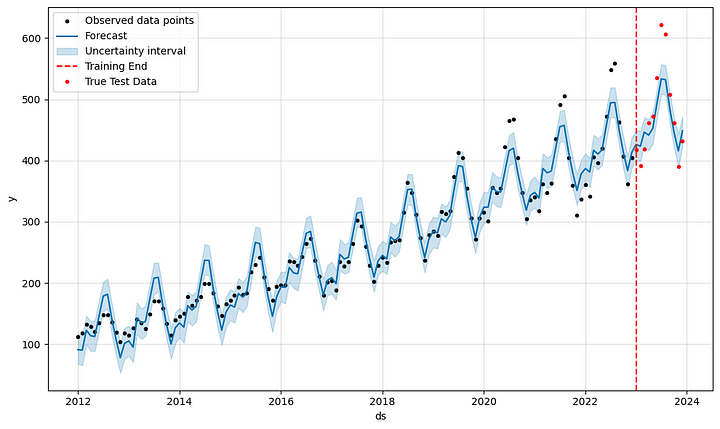
Puede verse que nuestro modelo no es tan malo. La mayoría de los valores reales de pasajeros están dentro de los intervalos de incertidumbre previstos. Sin embargo, los meses de verano parecen seguir siendo demasiado pesimistas, lo cual es un patrón que ya podemos ver en años anteriores. Este es un buen momento para empezar a explorar los parámetros y características que podríamos utilizar con Prophet.
En nuestro ejemplo, la estacionalidad no es un factor aditivo constante, sino que crece con la tendencia a lo largo del tiempo. Por lo tanto, podríamos considerar cambiar el seasonality_mode de «aditivo» a «multiplicativo» durante el ajuste del modelo. [4]
Nuestro tutorial concluirá aquí para darnos algo de tiempo para explorar el gran número de posibilidades que nos ofrece Prophet. Para revisar juntos el código completo, he consolidado los fragmentos en este archivo Python. Además, puedes subir este notebook directamente a Colab y ejecutarlo tú mismo. ¡Cuéntame qué tal te ha funcionado!
Conclusión
Prophet es una potente herramienta para predecir valores futuros en datos de series temporales, especialmente cuando tus datos tienen patrones repetitivos como ciclos mensuales o anuales. Es fácil de usar y puede proporcionar rápidamente predicciones precisas para tus datos específicos. Sin embargo, es esencial ser consciente de sus limitaciones. Si tus datos no tienen un patrón claro o si hay cambios significativos que el modelo no haya visto antes, es posible que Prophet no funcione de forma óptima. Comprender estas limitaciones es crucial para utilizar la herramienta con sensatez.
La buena noticia es que es muy recomendable experimentar con Prophet en tus conjuntos de datos. Cada conjunto de datos es único, y ajustar la configuración y probar diferentes enfoques puede ayudarte a descubrir lo que funciona mejor para tu situación específica. Así pues, sumérgete, explora y mira cómo Prophet puede mejorar tus previsiones de series temporales.
References
[1] Shumway, Robert H.; Stoffer, David S. (2017): Time Series Analysis and Its Applications. Cham: Springer International Publishing.
[2] Brownlee, Jason (2017): Introduction to Time Series Forecasting With Python
[3] Rafferty, Greg (2021): Forecasting Time Series Data with Facebook Prophet
[4] https://facebook.github.io/prophet/docs/quick_start.html
The post Primeros pasos en la predicción de series temporales de datos con Facebook Prophet first appeared on Planeta Chatbot.
]]>