The post Tutorial: construye un chatbot con búsqueda neuronal first appeared on Planeta Chatbot.
]]>
Pero la búsqueda también está enterrada en otros lugares. ¿Esos chatbots de atención al cliente que conoces y adoras? Hacen búsquedas. Pero en lugar de devolver páginas de resultados, sólo devuelven el resultado más relevante, y lo hacen en una interfaz de usuario conversacional.
Hoy veremos cómo podemos construir nuestro propio chatbot utilizando el ecosistema Jina, y cómo desplegarlo fácilmente en la nube.
Este tutorial se basa en nuestro repo de chatbot de ejemplo y puedes jugar con una demo en vivo. Que a su vez se basa en el chatbot jina hello de Jina< /code>.
Ten en cuenta que el código aquí es mucho más simple que en el repo, ya que no estamos demasiado interesados en el despliegue real o la eficiencia, sólo en la construcción de nuestro chatbot. Sin embargo, el repo contiene un docker-compose.yml para facilitar el despliegue en la nube.
¿Qué problema queremos resolver?
Cierra los ojos y retrocede en el tiempo. No, no tan lejos: los tazos (tambien conocidos como pogs) nunca volverán a estar de moda.
Pero retrocedamos en el tiempo hasta el nebuloso año 2020, justo al comienzo de la pandemia de COVID-19 (algunos creen que todavía estamos allí). Todo el mundo tenía preguntas, y se oían muchas respuestas que quizá no se sostenían demasiado bien cuando miramos atrás.
Vamos a construir un chatbot utilizando un conjunto de datos de preguntas y respuestas de COVID-19 de 2019. Por el amor de todo lo que es sagrado, no confíes en conjuntos de datos aleatorios que encuentres en Internet para obtener consejos médicos. Esto es sólo para construir una aplicación de ejemplo y no para sustituir a tu médico.
¿Cómo funcionará para el usuario final?
Desde el punto de vista del usuario final, todo lo que tiene que hacer es escribir una pregunta en la interfaz de usuario y se le devolverá una respuesta en una interfaz conversacional. Como cualquier otro chatbot.
¿Cómo funcionará bajo el capó?
Podemos dividir el código de nuestro chatbot en varios pasos:
- Procesar nuestros datos para cargarlos en nuestra aplicación de búsqueda.
- Construir y ejecutar un flujo para indexar nuestros datos (codificándolos y almacenando esos incrustaciones y metadatos en el disco).
- Ejecutar el mismo flujo para permitir a los usuarios buscar con preguntas como entrada.
- Abrir una bonita GUI en el navegador.
¡Vamos a construirlo!
Puedes referirte al repo para todo el código que discutimos aquí. No vamos a profundizar demasiado en la interfaz de usuario, excepto para mostrar dónde estamos interactuando con el ecosistema Jina.
Descargar los datos
Si clonas el repo, ya tendrás los datos allí. Alternativamente, puedes encontrar el conjunto de datos COVID-QA en Kaggle.
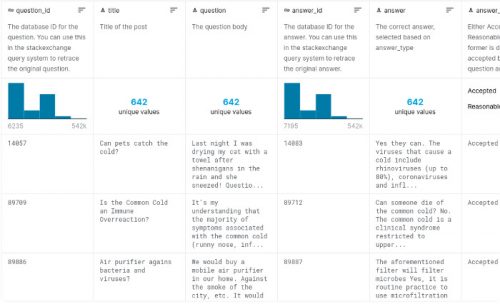
Vamos a utilizar el archivo community.csv, que tiene un montón de campos. Para nuestro caso de uso, sólo nos interesa question y answer.
Configuración básica
Crearemos un archivo llamado config.py y pondremos algunos valores allí para la configuración básica. Esto nos ahorra tener que rebuscar en el archivo principal de nuestra aplicación cada vez que queramos cambiar algo:
PORT = 23456 # which port will we run the REST interface on? NUM_DOCS = 30000 # how many rows of the CSV do we want to index? DATA_FILE = "./data/community.csv" # where can we find the CSV
También necesitaremos instalar DocArray y Jina:
pip install docarray jinag
Convertir los datos en DocumentArray
Casi todo el ecosistema de Jina funciona con Documentos, el tipo de datos primitivo de Jina. Estos pueden contener texto, imagen, audio, vídeo o cualquier otro tipo de datos. Un grupo de Documentos puede combinarse en un DocumentArray. Toda esta funcionalidad está en el paquete DocArray.
En nuestro caso, trataremos cada fila del archivo CSV como un único Documento, y luego combinaremos todos esos Documentos en un DocumentArray que luego podremos procesar.
DocArray contiene una buena función from_csv para procesar rápidamente los CSV, así que vamos a utilizarla en app.py:
from config import DATA_FILE, NUM_DOCS
docs = DocumentArray.from_csv(
DATA_FILE, field_resolver={"question": "text"}, size=NUM_DOCS
)
Como puedes ver, hacemos referencia a DATA_FILE y NUM_DOCS que hemos configurado antes en config.py. A continuación, asignamos el atributo de text de cada documento al campo de la pregunta en la fila correspondiente. Los demás campos se añadirán automáticamente como metadatos en el atributo tags del Documento.
Construir nuestro flujo de indexación
Queremos tomar nuestro DocumentArray, y para cada Documento:
- Codificar su contenido en una incrustación vectorial
- Almacenarlos en un índice para facilitar la búsqueda más tarde
Haremos esto con nuestro Flow, que construimos usando el núcleo de Jina.
flow = (
Flow(protocol="http", port=PORT)
.add(
name="encoder",
uses="jinahub+docker://TransformerTorchEncoder",
uses_with={
"pretrained_model_name_or_path": "sentence-transformers/paraphrase-mpnet-base-v2"
},
)
.add(name="indexer", uses="jinahub://SimpleIndexer", install_requirements=True)
)
Puedes ver que estamos usando un arreglo de Flow().add(...).add(...) para construir nuestro pipeline de procesamiento a partir de Executors:
- Codificación: El primer
.add()añade nuestro ejecutor codificador. Usaremos TransformerTorchEncoder de Jina Hub, que se ejecuta en un contenedor Docker para no tener que preocuparnos por las dependencias. También le diremos qué modelo queremos que utilice. - Indexación: Con el último
.add()traeremos nuestro indexador Executor. Sólo necesitamos algo sencillo como el bien llamado SimpleIndexer. De nuevo, lo sacamos de Jina Hub pero no lo ejecutaremos en Docker ya que necesita acceso para escribir en el sistema de archivos local (lo que podríamos hacer con unas cuantas opciones deuses_withyvolume, pero eso complica el código para un ejemplo sencillo)
También puedes ver que hemos habilitado una pasarela HTTP y hemos establecido el puerto en los argumentos de Flow.
Ejecutar nuestro flujo de indexación
Podemos abrir nuestro Flow con:
with flow:
flow.index(docs, show_progress=True)
Para ponerlo en marcha, ejecuta app.py en el terminal que prefieras. La primera ejecución puede tardar un poco, ya que tiene que descargar nuestros Ejecutores de Jina Hub y luego agitar todos los datos.
Es posible que veas algunas advertencias. No te preocupes por ellas. El Señor sabe que yo nunca lo hago.

Después deberías ver un workspace de espacio de trabajo que contiene los datos indexados:
Y dentro de esa carpeta del espacio de trabajo verás index.db, una base de datos SQLite que almacena tus datos:
Si has indexado todo el conjunto de datos, el directorio del espacio de trabajo debería ocupar unos 5,4Mb.
Hacer una pregunta a nuestro chatbot
Esta vez utilizaremos el mismo flujo, pero en lugar de indexar, buscaremos la respuesta a una pregunta. Como dijimos antes, todo en el ecosistema de Jina es un Documento, así que lo haremos:
- Envolver la pregunta en un Documento
- Pasar ese documento a nuestro flujo
- Obtener las preguntas más cercanas devueltas por el flujo
- Imprimir el campo de respuesta de la pregunta más cercana
question = Document(text="Can I catch COVID from my cat?")
with flow:
results = flow.search(question)
print(results[0].matches[0].tags["answer"])
Utilizamos los mismos dos Ejecutores que para la indexación, pero esta vez actúan de forma un poco diferente:
- Codificación: Codifica la cadena de texto de la pregunta en una incrustación vectorial
- Indexación: Busca en el índice la incrustación más cercana a la cadena de búsqueda codificada y devuelve los datos coincidentes
Ahora, si ejecutas app.py de nuevo, obtendrás una respuesta como:
El Covid-19 es el resultado de un brote zoonótico que pasa de los murciélagos a un huésped intermedio ( y no identificado ) y de ahí a los humanos. Se cree que los murciélagos no sufren la enfermedad por sí mismos, ya que son portadores de bajos niveles de virus, pero el huésped intermedio modifica el virus y lo amplifica, de modo que aumenta enormemente la cantidad de virus que puede verterse en el medio ambiente infectando a los humanos. Una posible hipótesis es que el coronavirus de los murciélagos se combine con un coronavirus de los peces dentro del huésped intermediario. Esto se basa en la observación de que el gen de la espiga del SARS-CoV-2 comparte una inserción de 39 bases con un tipo de pez soldado que nada en el Mar del Sur de China….
Si sigues leyendo, verás que la respuesta contiene información sobre los gatos más abajo:
El SARS-CoV-2 infecta a los humanos a través del receptor de superficie ACE2, pero este receptor no sólo se encuentra en los humanos. Otros animales tienen receptores ACE2 similares, pero no exactamente iguales, y varios perros y un gato han dado positivo en hisopos para el SARS-CoV-2. El gato desarrolló síntomas de covirus-19.
En un ejemplo más avanzado, dividiríamos la respuesta completa (larga) en trozos de frases y sólo devolveríamos al usuario el trozo más relevante.
Añadir una interfaz de usuario
No nos centraremos demasiado en la interfaz de usuario aquí, excepto en ciertas partes que se conectan al ecosistema de Jina. Puedes encontrar los archivos aquí.
Usaremos Streamlit para construir nuestro frontend y el maravilloso módulo Streamlit-Chat para añadir una interfaz tipo chatbot:
pip install streamlit-chat streamlit
Una vez más vamos a configurar un frontend_config.py básico:
PORT = 23456 SERVER = "0.0.0.0" TOP_K = 1
La parte más importante de frontend.py es la forma en que interactuamos con nuestro backend para obtener la mejor respuesta a la pregunta de un usuario. Hacemos esto usando Jina Client:
from jina import Client
def search_by_text(input, server=SERVER, port=PORT, limit=TOP_K):
client = Client(host=server, protocol="http", port=port)
response = client.search(
Document(text=input),
parameters={"limit": limit},
return_results=True,
show_progress=True,
)
match = response[0].matches[0].tags["answer"]
return match
El resto del código del frontend funciona básicamente para tomar la entrada del usuario, enviarla a esa función y mostrar la respuesta en una interfaz de chat. Dado que no es super-relevante para Jina no lo cubriremos aquí.
Conectando nuestra interfaz de usuario a nuestro flujo
Nuestro código de búsqueda de antes es genial para la creación de prototipos CLI, pero ahora tenemos que abrir (y mantener abierta) nuestra interfaz RESTful en nuestro app.py del backend. Vamos a comentar nuestra funcionalidad de búsqueda inicial, ya que ya no la estamos utilizando, y utilizaremos flow.block() para mantener un puerto abierto en su lugar:
# question = Document(text="Can I catch COVID from my cat?") # with flow: # results = flow.search(question) # print(results[0].matches[0].tags["answer"]) with flow: flow.block()
A continuación, volveremos a ejecutar nuestro código de backend:
python app.py
Seguido de nuestro código del frontend en una nueva terminal:
streamlit frontend.py
Una vez que todo se haya puesto en marcha, ahí lo tienes, ¡un chatbot con búsqueda neuronal!:
Próximos pasos
- Ya está hecho: Si fuéramos a correr en el mundo real, querríamos dividir las cosas en funciones, hacerlas correr en Docker, etc. Ya lo hemos hecho en nuestro repositorio, así que la ejecución y el despliegue es un paseo por el parque.
- Romper nuestro conjunto de datos en trozos más pequeños: Nadie quiere leer respuestas larguísimas, por lo que sería bueno sentenciar todo y buscar a través de frases en lugar de texto completo.
- Afinar nuestro modelo: Estamos utilizando un modelo preentrenado que no está especializado en preguntas médicas. Para mejorar el rendimiento, podemos afinar el modelo con el llamado Finetuner de Jina.
Únete a la comunidad
¿Tienes comentarios? ¿Quieres saber más sobre el ecosistema Jina y la búsqueda neuronal? Únete a nosotros en Slack y pásate por alguno de nuestros eventos.
The post Tutorial: construye un chatbot con búsqueda neuronal first appeared on Planeta Chatbot.
]]>The post Qué es la búsqueda neuronal y cómo se diferencia de la búsqueda simbólica first appeared on Planeta Chatbot.
]]>En pocas palabras, la búsqueda neuronal es un nuevo enfoque para la recuperación de información. En lugar de indicarle a una máquina un conjunto de reglas para que entienda qué datos son qué, el Neural Search o «búsqueda neuronal» hace lo mismo con una red neural preentrenada. Esto significa que los desarrolladores no tienen que escribir cada pequeña regla, lo que les ahorra tiempo y dolores de cabeza, y el sistema se entrena para mejorar a medida que avanza.
¿Qué es Jina?
Jina es una aproximación a la búsqueda neural. Es nativo de la nube, por lo que puede desplegarse en contenedores, y ofrece una búsqueda de todo a todo. Texto-a-texto, imagen-a-imagen, vídeo-a-vídeo, o cualquier otra cosa que pueda alimentar.
Antecedentes
Las búsquedas son un gran negocio, que cada vez se hace más grande. Hace sólo unos años, buscar significaba escribir algo en un cuadro de texto (¡ah, aquellos embriagadores días de Yahoo! y Altavista). Ahora la búsqueda abarca texto, voz, música, fotos, vídeos, productos y mucho más. Justo antes del cambio de milenio había sólo 3,5 millones de búsquedas en Google al día.
Hoy en día (según el primer resultado del término de búsqueda 2020 google searches per day) esa cifra podría llegar a los 5.000 millones y seguir aumentando, más de 1.000 veces más. Eso por no hablar de los miles de millones de perfiles de Tinder, productos de Amazon y listas de reproducción de Spotify que buscan millones de personas cada día desde sus teléfonos, ordenadores y asistentes virtuales.
Basta con ver el crecimiento estratosférico de las consultas en Google, ¡y eso solo hasta 2012!

En resumen, la búsqueda es enorme. En este artículo, vamos a analizar el campeón actual de los métodos de búsqueda, la búsqueda simbólica, y el valiente aspirante, la búsqueda neural.

Nota: Este artículo está basado en un post de Han Xiao con su permiso. Consúltalo si quieres una introducción más técnica a la búsqueda neuronal.
Búsqueda simbólica: Las reglas son las reglas
Google es un enorme motor de búsqueda de uso general. Otras empresas no pueden simplemente adaptarlo a sus necesidades y conectarlo a sus sistemas. En su lugar, utilizan frameworks como Elastic y Apache Solr, sistemas de búsqueda simbólica que permiten a los desarrolladores escribir las reglas y crear conductos para buscar productos, personas, mensajes o lo que la empresa necesite.
Tomemos como ejemplo Shopify. Utilizan Elastic para indexar y buscar entre millones de productos en cientos de categorías. Esto no podría hacerse de forma inmediata o con un motor de búsqueda de propósito general como Google. Tienen que hacer uso de Elastic y escribir reglas y pipelines específicas para indexar, filtrar, ordenar y clasificar los productos por una variedad de criterios, y luego convertir estos datos en símbolos que el sistema pueda entender. De ahí el nombre de búsqueda simbólica. Aquí está Greats, una popular tienda de Shopify de zapatillas de deporte:

Tú y yo sabemos que si buscas zapatillas nike rojas quieres, bueno, zapatillas nike rojas. Sin embargo, esas son sólo palabras para un sistema de búsqueda típico. Claro, si las escribes, con suerte obtendrás lo que has pedido, pero ¿qué pasa si esas zapatillas están etiquetadas como deportivas? ¿O incluso etiquetadas como escarlata? En casos como éste, un desarrollador necesita escribir reglas:
- El rojo es un color
- Escarlata es un sinónimo de rojo
- Nike es una marca
- Las zapatillas son un tipo de calzado
- Otro nombre para las zapatillas de deporte es zapatillas de deporte
O, expresado en JSON como pares clave-valor:
{
"color": "red",
"color_synonyms": ["scarlet"],
"brand": "nike",
"type": "sneaker",
"type_synonyms": ["trainers"],
"category": "footwear"
}
Cada uno de estos pares clave-valor puede considerarse un símbolo, de ahí el nombre de búsqueda simbólica. Cuando un usuario introduce una consulta de búsqueda, el sistema la descompone en símbolos y los compara con los símbolos de los productos de su base de datos.

¿Pero qué pasa si un usuario escribe nikke en lugar de nike, o busca shirts (con una s) en lugar de shirt? Hay muchas reglas en el lenguaje, y la gente las rompe todo el tiempo. Para conseguir símbolos eficaces (por ejemplo, saber que nikke significa realmente {«marca»: «nike«}), hay que definir muchas reglas y encadenarlas en una compleja cadena:

Inconvenientes de la búsqueda simbólica
Tienes que explicar cada pequeña cosa
Nuestro ejemplo de búsqueda anterior era el hombre de las zapatillas rojas de Nikke. ¿Pero qué pasa si nuestro buscador es británico? Un británico escribiría red nikke trainer man. Tendríamos que explicar a nuestro sistema que las zapatillas de deporte y las deportivas son lo mismo con nombres diferentes. ¿O qué pasa si alguien busca un bolso LV? Habría que decirle al sistema que LV significa Louis Vuitton.
Hacer eso para cada tipo de producto lleva una eternidad y siempre hay cosas que se quedan en el tintero. ¿Y si se quiere localizar para otros idiomas? Tendrás que volver a hacerlo todo de nuevo. Eso significa mucho trabajo, conocimiento y atención al detalle.

Es frágil
El texto es complicado: Como hemos explicado anteriormente, si un usuario escribe nikke rojo hombre zapatilla de deporte un sistema de búsqueda clásico tiene que reconocer que está buscando un rojo (color) Nike (marca con ortografía corregida) zapatilla de deporte (tipo) para los hombres (subtipo). Esto se hace interpretando la cadena de búsqueda y los detalles del producto a símbolos a través de pipelines, las cuales pueden tener problemas importantes.

- Cada componente de la cadena tiene una salida que sirve de entrada al siguiente componente. Por lo tanto, un problema al principio del proceso puede romper todo el sistema.
- Algunos componentes pueden tomar entradas de varios predecesores. Eso significa que hay que introducir más mecanismos para evitar que se bloqueen unos a otros
- Es difícil mejorar la calidad general de la búsqueda. Si se mejoran uno o dos componentes, es posible que los resultados de la búsqueda no mejoren.
- Si se quiere buscar en otro idioma, hay que reescribir todos los componentes dependientes del idioma en la cadena de producción, lo que aumenta el coste de mantenimiento.
Búsqueda neuronal: (pre)entrenar, no explicar
Una forma más sencilla sería un sistema de búsqueda entrenado con datos existentes. Si entrenas un sistema en suficientes escenarios diferentes de antemano (es decir, un modelo preentrenado), desarrolla una capacidad generalizada para encontrar resultados que coincidan con las entradas, ya sean GIFs de Tumblr, frases de Wikipedia o imágenes de Pokémon. Puedes conectar el modelo directamente a tu sistema y empezar a indexar y buscar de inmediato.
Aquí puedes ver el código:
from jina.flow import Flow
f = (Flow()
.add(name='my-encoder', image='jinaai/hub.examples.my_encoder',
volumes='./abc', yaml_path='hub/examples/my_encoder/my_encoder_ext.yml',
port_in=55555, port_out=55556)
De esta manera, no necesitas perder horas escribiendo reglas interminables para tu caso de uso. En su lugar, basta con incluir una línea en el código para descargar el modelo que quieras de una «tienda de aplicaciones» (como el próximo Jina Hub), y ponerte en marcha.
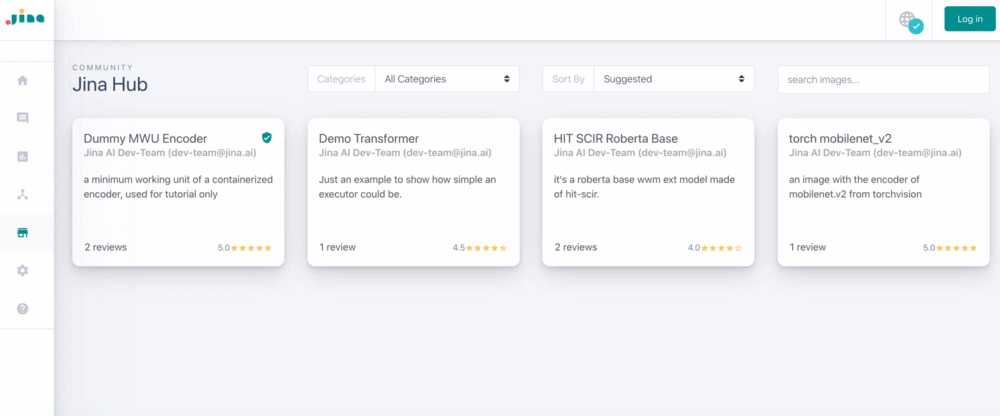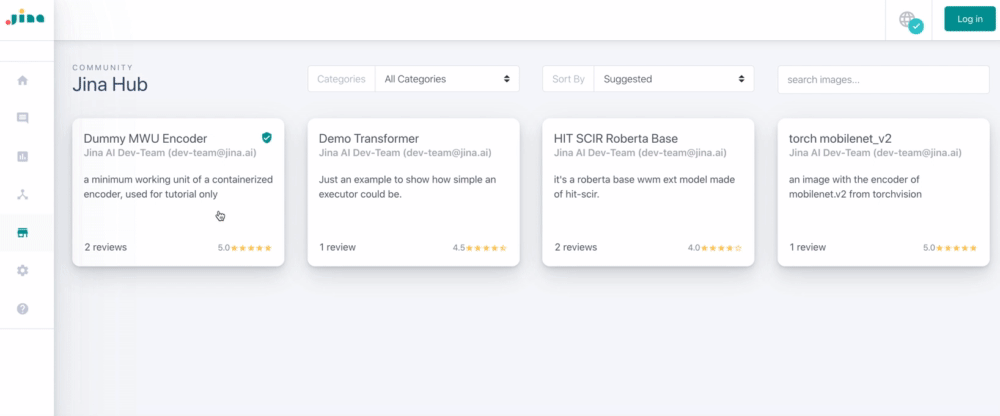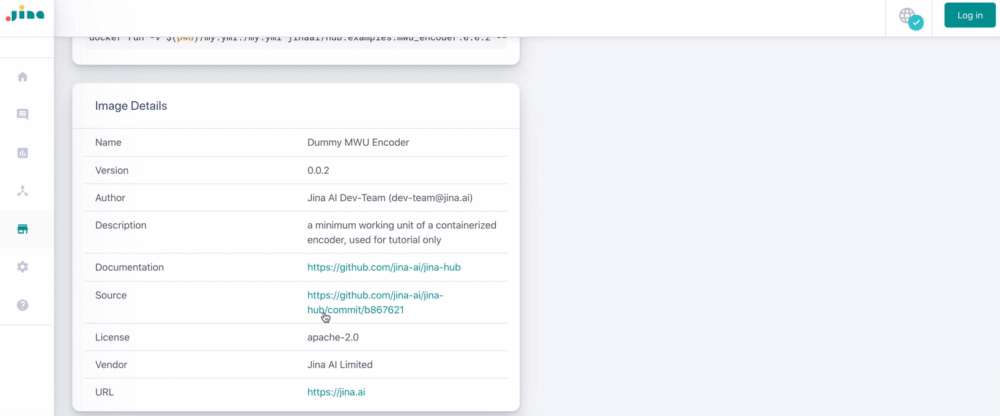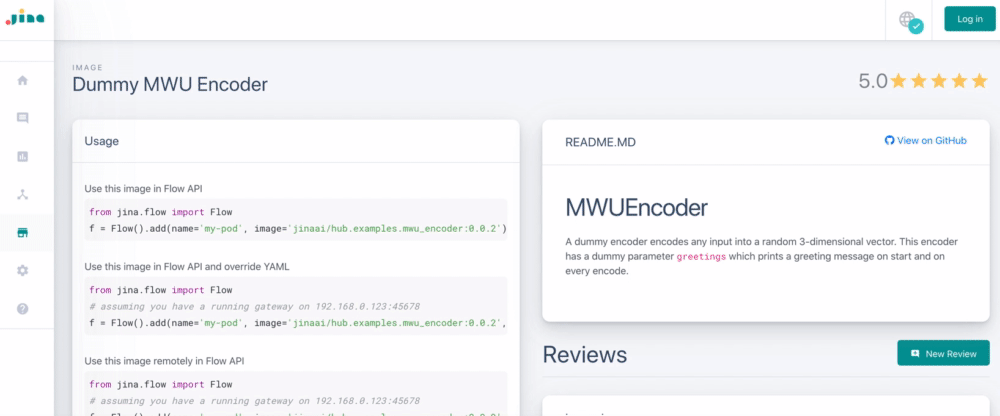
En comparación con la búsqueda simbólica, la búsqueda neural:
- Elimina el frágil pipeline, haciendo que el sistema sea más resistente y escalable.
- Encuentra una forma mejor de representar la semántica subyacente de los productos y las consultas de búsqueda.
- Aprende sobre la marcha, por lo que mejora con el tiempo.
¿Funciona Jina, sin embargo?
Una búsqueda «funciona» si entiende y devuelve resultados de calidad para:
- Consultas simples: Como la búsqueda de «rojo», «nike» o «zapatillas».
- Consultas compuestas: Como «zapatillas nike rojas.
Si ni siquiera es capaz de hacer eso, no tiene sentido que compruebe cosas tan sofisticadas como la corrección ortográfica o la capacidad de trabajar en diferentes idiomas.
En fin, menos hablar y más buscar:
🇬🇧 nike

🇩🇪 nike schwarz (en un idioma diferente)

🇬🇧 addidsa (marca mal escrita)

🇬🇧 addidsa trosers (marca y categoría mal escritas)

🇬🇧 🇩🇪 kleider flowers (lenguas mixtas)

Así que, como puedes ver, ¡la búsqueda neuronal lo hace bastante bien!
Comparación entre la búsqueda simbólica y la neural
Entonces, ¿cómo se compara la búsqueda neuronal con el actual campeón, la búsqueda simbólica? Veamos los pros y los contras de cada una:

No estamos tratando de elegir entre el Equipo Simbólico y el Equipo Neural. Ambos enfoques tienen sus propias ventajas y se complementan bastante bien. Así que la mejor pregunta que podemos hacernos es: ¿cuál es el que mejor se adapta a tu caso de uso y tus necesidades?
Prueba Jina
No hay mejor manera de probar Jina que sumergirse y jugar con ella. Proporcionamos imágenes Docker preentrenadas y jinabox.js, un front-end fácil de usar para buscar texto, imágenes, audio o vídeo. No hay ningún ejemplo de búsqueda de productos (todavía), pero puedes buscar cosas más desenfadadas como tu Pokémon favorito o la Wikipedia.
Puedes encontrar más información sobre Jina en nuestro repositorio de GitHub:
The post Qué es la búsqueda neuronal y cómo se diferencia de la búsqueda simbólica first appeared on Planeta Chatbot.
]]>